Archive
Microsoft PSS – SQL 2016 Series: It just runs faster | April updates
Microsoft PSS Engineers have built a series on “It Just Runs Faster”!
“In the Sep 2014 the SQL Server CSS and Development teams performed a deep dive focused on scalability and performance when running on current and new hardware configurations. The SQL Server Development team tasked several individuals with scalability improvements and real world testing patterns. You can take advantage of this effort packaged in SQL Server 2016. – https://www.microsoft.com/en-us/server-cloud/products/sql-server-2016/”
SQL 2016 will run faster in many ways, without changing code.
The series kickoff is here:
https://blogs.msdn.microsoft.com/psssql/2016/02/23/sql-2016-it-just-runs-faster-announcement/
Previous updates:
Microsoft PSS – SQL 2016 Series: It just runs faster | Feb-March updates
The announcements so far in April are:
SQL 2016 – It Just Runs Faster: Updated Scheduling Algorithms
https://blogs.msdn.microsoft.com/psssql/2016/04/01/sql-2016-it-just-runs-faster-updated-scheduling-algorithms/
SQL 2016 – It Just Runs Faster: Dynamic Memory Object (CMemThread) Partitioning
https://blogs.msdn.microsoft.com/psssql/2016/04/06/sql-2016-it-just-runs-faster-dynamic-memory-object-cmemthread-partitioning/
SQL 2016 – It Just Runs Faster: SOS_RWLock Redesign
https://blogs.msdn.microsoft.com/psssql/2016/04/07/sql-2016-it-just-runs-faster-sos_rwlock-redesign/
SQL 2016 – It Just Runs Faster: Indirect Checkpoint Default
https://blogs.msdn.microsoft.com/psssql/2016/04/12/sql-2016-it-just-runs-faster-indirect-checkpoint-default/
SQL 2016 – It Just Runs Faster: Larger Data File Writes
https://blogs.msdn.microsoft.com/psssql/2016/04/15/sql-2016-it-just-runs-faster-larger-data-file-writes/
SQL 2016 – It Just Runs Faster: Multiple Log Writer Workers
https://blogs.msdn.microsoft.com/psssql/2016/04/19/sql-2016-it-just-runs-faster-multiple-log-writer-workers/
SQL 2016 – It Just Runs Faster: Column Store Uses Vector Instructions (SSE/AVX)
https://blogs.msdn.microsoft.com/psssql/2016/04/22/sql-2016-it-just-runs-faster-column-store-uses-vector-instructions-sseavx/
SQL 2016 – It Just Runs Faster – BULK INSERT Uses Vector Instructions (SSE/AVX)
https://blogs.msdn.microsoft.com/psssql/2016/04/27/sql-2016-it-just-runs-faster-bulk-insert-uses-vector-instructions-sseavx/
SQL 2016 – It Just Runs Faster: AlwaysOn Log Transport Reduced Context Switches
https://blogs.msdn.microsoft.com/psssql/2016/04/28/sql-2016-it-just-runs-faster-alwayson-log-transport-reduced-context-switches/
Check my blog posts on most of the new features released in SQL Server 2016 here
Informatica – The first character in a name cannot be a number (error)
Today while creating a mapping by using import method & template I got a pop-up with following error message in Designer:
03/30/2016 16:30:55 **** Importing Source Definition: tblCustomerResults ...
: The first character in a name cannot be a number.
** Failed to Import: tblCustomerResults
03/30/2016 16:30:55 **** Importing Target Definition: tblCustomerResults ...
: A column with the name 120_-_Unknown already exists.
Please enter a unique name.
** Failed to Import: tblCustomerResults
03/30/2016 16:30:56 **** Importing Mapping: mACQtblCustomerResults ...
: Could not find Transformation definition for: tblCustomerResults
** Failed to Import: mACQtblCustomerResults
With the above error its quiet evident that Informatica do not support column names that starts with a number. But to confirm I checked online and found it to be true and one of the biggest limitation in Informatica.
As a workaround:
1. I dropped the Source Connection pointing to the Original source.
2. I created the Source table in my Database and re-created the Source Connection pointing to this table.
3. Save and export the Source XML.
4. Finally Import the mapping by using same template and the new Source XML, successful 🙂
I also found that this limitation is not only with columns, but also with Source Table Name, Database Definition (DBD) name, Repository Folders, etc.
DB Basics – How to control Data Redundancy in a database system (RDBMS) by Normalization
Redundancy in Database systems occurs with various insert, update, and delete anomalies.
To avoid these anomalies in first step you need to make sure your database tables or relations are in good normal forms or normalized upto a certain level.
Normalization is a systematic way of ensuring that a database structure is suitable for general-purpose querying and free the anomalies discussed above. that could lead to a loss of data integrity.
Normal forms in a database or the concept of Normalization makes a Relation or Table free from insert/update/delete anomalies and saves space by removing duplicate data.
–> According to E. F. Codd the objectives of normalization were stated as follows:
1. To free the collection of relations from undesirable insertion, update and deletion dependencies.
2. To reduce the need for restructuring the collection of relations as new types of data are introduced, and thus increase the life span of application programs.
3. To make the relational model more informative to users.
4. To make the collection of relations neutral to the query statistics, where these statistics are liable to change as time goes by.
As of now there are total 8 normal forms, but to keep our data consistent & non-redundant the first 3 Normal Forms are sufficient.
–> Anomalies like: Let’s say you have a single table that stores Employee and Department details, thus:
1. Insert Anomaly: If you are inserting a detail of an Employee then his department detail will also be entered for every employee record, thus departments details will be repeated with multiple records, thus storing duplicate data for Departments.
2. Update Anomaly: While updating a department detail you have to update the same department for various employees, which may lead to inconsistent state if any record is left while updating or on any error.
3. Delete Anomaly: If a department is closed, then deleting department record will also delete the Employee records, thus missing records.
The process of normalization makes this EmployeeDepartment table to decompose or split into 2 or more tables and linked them by Foreign Keys, thus eliminating duplicate records, data redundancy and making data/records consistent across all relations/tables.
– 1st NF talks about atomic values and non-repeating groups.
– 2nd NF enforces that a non-Key attribute should belong to entire Key attribute.
– 3rd NF makes sure that there should be no transitive dependency between a non-Key and a Key attribute.
For details on these 3 NFs check my blog post on [Database Normalization].
Download & Install SQL Server Management Studio (SSMS) 2016 (decoupled from SQL Server engine setup)
In my [previous blog] post of SQL Server 2016 RC0 availability, I mentioned regarding SQL Server Management Studio (SSMS) that it will no longer be installed from the main feature tree of SQL Server engine setup.
As per Microsoft, this is basically to support the move to make a universal version of SSMS that ships every month or so.
So, now on wards after installing SQL Server 2016 you need to install SSMS separately.
–> Till SQL Server 2014 you have an option of choosing SSMS in the Feature selection tree, but with SQL Server 2016 and on wards this option is taken out, can be seen in the pic below:

–> Now to download SSMS 2016 you can either visit the Microsoft [download page]
Or, try installing directly via the “Installation Center” as shown below. This will install SSMS directly online.

So, once you take appropriate action above to download SSMS 2016, the Installation kicks off like this:
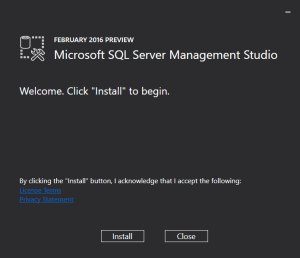
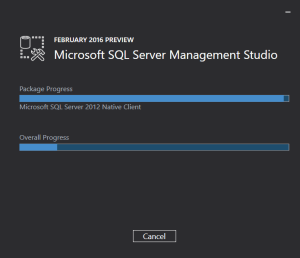
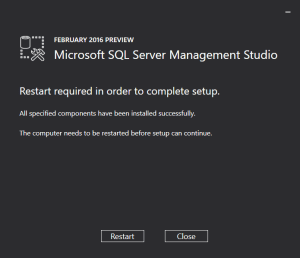
And here is the version information of SSMS 2016 after successful installation:
Microsoft SQL Server Management Studio 13.0.12000.65 Microsoft Analysis Services Client Tools 13.0.1100.213 Microsoft Data Access Components (MDAC) 10.0.10586.0 Microsoft MSXML 3.0 6.0 Microsoft Internet Explorer 9.11.10586.0 Microsoft .NET Framework 4.0.30319.42000 Operating System 6.3.10586
Tech Tip: Move your SQL server onto the cloud with Hosted Citrix VDI available unbelievable citrix xendesktop pricing and get an easy remote access to it from anywhere on any device(PC/Mac/Linux/android/iOS) powered by one of the leading providers of cloud hosting – Apps4Rent.
Check my blog posts on most of the new features released in SQL Server 2016
Good news – Microsoft makes SQL Server “Developer Edition” free for developers !
Microsoft on 31st March 2016 announced the free availability of Developer Edition of SQL Server, currently 2014. The Developer Edition is meant for development and testing only, and not for production environments or for use with production data.

With SQL Server 2014 Developer edition developers can build any kind of application on top of SQL Server. It includes all the functionality of Enterprise edition, but is licensed for use as a development and test system, not as a production server.
So, with this edition you are getting the Database Engine as well as DW/BI capabilities ( i.e. SSIS /AS /RS) for free 🙂
[Download the SQL Server 2014 Developer Edition free here]
This is a very good news for Developers, as till now the SQL Server Express edition used to be the free database for entry-level development, which has lot of limitations like:
1. Only Database Engine, no DW/BI suit (absence of SSIS/RS/AS).
2. Max size of a DataBase is set to 10GB (but you can create multiple databases)
3. No SQL Agent
4. Single CPU utilization
5. Max 1 GB RAM allocation
6. Max 16 number of instances per server
Hence this is a very good deal that you can now get full featured suit of SQL Server with Database Engine as well as with all DW/BI capabilities for free to play, develop and learn with.


![]()
Current Visitors

StatCounter …since April 2012

 Leisure blog: Creek & Trails
Leisure blog: Creek & Trails
- NMDC Hyderabad Marathon – My first 42k FM, cramps, training and fuelling
- Singapore (Part 2) – 6 days itinerary, sightseeing & attractions
- Singapore (Part 1) – Tickets, Visa, Hotel, Forex Card/Cash, Metro/Bus cards
- I got full refund of my flight tickets during COVID lockdown (AirIndia via MakeMyTrip)
- YouTube – Your Google Ads account was cancelled due to no spend
- YouTube latest update on its YPP (YouTube Partner Program) which may affect your channel
- Starting your own blog !!!
- How to file ITR (Income Tax Return) online AY 2017-18 (for simple salaried)
- Scam – Become a kin/hier and earn a fortune – via LinkedIn and Email
- Places to visit in and around Vizag (aka Visakhapatnam)
