Archive
Spark – Cannot perform Merge as multiple source rows matched…
In SQL when you are syncing a table (target) from an another table (source) you need to make sure there are no duplicates or repeated datasets in either of the Source or Target tables, otherwise you get following error:
UnsupportedOperationException: Cannot perform Merge as multiple source rows matched and attempted to modify the same target row in the Delta table in possibly conflicting ways. By SQL semantics of Merge, when multiple source rows match on the same target row, the result may be ambiguous as it is unclear which source row should be used to update or delete the matching target row. You can preprocess the source table to eliminate the possibility of multiple matches. Please refer to https://docs.microsoft.com/azure/databricks/delta/delta-update#upsert-into-a-table-using-merge
The above error says that while doing MERGE operation on the Target table there shouldn’t be any duplicates in the Source table. This check is applied implicitly by the SQL engine to avoid unnecessary updates and avoid inconsistent data.
So, to avoid this issue make sure you have de-duplication logic before the MERGE operation.
Below is a small demo to reproduce this error.
Let’s create two sample tables (Source & Target) for our demo purpose:
val df1 = Seq((1, "Brock", 30),
(2, "John", 31),
(2, "Andy", 35), //duplicate ID = 2
(3, "Jane", 25),
(4, "Maria", 30)).toDF("Id", "name", "age")
spark.sql("drop table if exists tblPerson")
df1.write.format("delta").saveAsTable("tblPerson")
val df2 = Seq((1, "Jane", 30),
(2, "John", 31)).toDF("Id", "name", "age")
spark.sql("drop table if exists tblPersonTarget")
df2.write.format("delta").saveAsTable("tblPersonTarget")
Next we will try to MERGE the tables and running the query will result in an error:
val mergeQuery =
s"""MERGE INTO tblPersonTarget As tgt
Using tblPerson as src
ON src.Id = tgt.ID
WHEN MATCHED
THEN UPDATE
SET
tgt.name = src.name,
tgt.age = src.age
WHEN NOT MATCHED
THEN INSERT (
ID,
name,
age
)
VALUES (
src.ID,
src.name,
src.age
)"""
spark.sql(mergeQuery)
To remove duplicates you can simply try removing by using window functions or some logic as per your business requirement:
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.functions._
val df2 = df1.withColumn("rn", row_number().over(window.partitionBy("Id").orderBy("name")))
val df3 = df2.filter("rn = 1")
display(df3)
Apache Spark – new Features & Improvements in Spark 3.0

With Spark 3.0 release (on June 2020) there are some major improvements over the previous releases, some of the main and exciting features for Spark SQL & Scala developers are AQE (Adaptive Query Execution), Dynamic Partition Pruning and other performance optimization and enhancements.
Below I’ve listed out these new features and enhancements all together in one page for better understanding and future reference.
1. Adaptive Query Execution (AQE)
– To process large and varying amount of data in an optimized way Spark engine makes use of its Catalyst optimizer framework. It is a Cost-Based optimizer which collects statistics from column data (like cardinality/row-count, distinct values, NULL values, min/max/avg values, etc.) and helps creating better and optimized Query Execution Plans.
– But very often at runtime due to stale Statistics query plans can go suboptimal by choosing incorrect Joins and improper partitions/reducers, thus resulting in long running queries.
– Here the AQE feature allows the optimizer to create Alternate Execution Plans at runtime which are more optimal based on the current runtime statistics of the underlying data.
–> Below are the 3 improvements in AQE:
i. Coalesce Shuffle Partitions: it combines or coalesces adjacent small partitions into bigger partitions at runtime by looking at the shuffle file statistics, thus reducing the number of tasks to perform.
ii. Switch Join Strategy: converts a Sort-Merge-Join to a Broadcast-Hash-Join when the optimizer finds one table size is smaller than the broadcast threshold.
iii. Skew Join Optimization: Data Skew happens due to uneven distribution of data among partitions. Due to this in a JOIN query some partitions grow significantly bigger than the other partitions, and corresponding Tasks takes much longer time to finish than other smaller Tasks, this slows down the whole query performance. This feature reads the shuffle file statistics at runtime, detects this skew, and breaks the bigger partitions into smaller ones with the size of similar other smaller partitions, which are now optimal to be joined to the corresponding partition of the other table.
More details on: Databricks post on AQE | Spark JIRA 31412 | Baidu Case Study Video
2. Dynamic Partition Pruning
– In a Star schema while querying multiple Fact & Dimension tables with JOINs there are times when we apply filter on a Dimension table, but unnecessary data from the Fact tables is also scanned by the Spark query engine, resulting in slow query performance.
– This could have been avoided by Pruning such partitions at Fact tables side too, but this information is unknown to the Query engine at runtime.
– The idea is to make queries more performant by reducing the I/O operations so that only the required partitions are scanned, so developers tend to add similar filters manually at Fact tables side, this strategy is also known as Static Partition Pruning.
–> Now with the new feature of Dynamic Partition Pruning the filter at Dimension side is automatically pushed to the Fact table side (called Filter Pushdown) which Prunes more unwanted partitions, allowing Query engine to read only specific partitions and return results faster.
More details on: Databricks post & video on DPP | Spark JIRA 11150
3. JOIN Hints
– At times due to various reasons Spark query engine compiler is unable to make the best choice of what JOIN to choose, so developers can use appropriate JOIN hints to influence the optimizer to choose a better plan.
– In previous version of Spark i.e. 2.x only Broadcast Join hint was supported, but now with Spark 3.0 other Join hints are also supported, as follows:
– Broadcast Hash join (BROADCAST, BROADCASTJOIN, MAPJOIN)
– Shuffle Sort Merge join (MERGE, SHUFFLE_MERGE, MERGEJOIN)
– Shuffle Hash join (SHUFFLE_HASH)
– Shuffle Nested Loop join (SHUFFLE_REPLICATE_NL)
-- Spark-SQL
SELECT /*+ SHUFFLE_MERGE(Employee) */ * FROM Employee E
INNER JOIN Department D ON E.DeptID = D.DeptID;
-- Scala
val DF_shuffleMergeJoin =
DF_Employee.hint("SHUFFLE_MERGE").join(DF_Department,"DeptID")
More details on: Apache Spark Docs on JOIN Hints
4. SQL new features and improvements
– EXPLAIN FORMATTED Header, Footer & Subqueries
– 35 new built-in Functions
– sinh, cosh, tanh, asinh, acosh, atanh
– any, every, some
– bit_and, bit_or, bit_count, bit_xor
– bool_and, bool_or
– count_if
– date_part
– extract
– forall
– from_csv
– make_date, make_interval, make_timestamp
– map_entries, map_filter, map_zip_with
– max_by, min_by
– schema_of_csv, to_csv
– transform_keys, transform_values
– typeof
– version
– xxhash64
5. Other changes
– spark.sql.ansi.enabled = true: Force users to stop using the reserved keywords of ANSI SQL as identifiers.
– spark.sql.storeAssignmentPolicy = ANSI
– Compatible with Scala 2.12
– TRIM function argument order is reversed now
– Type coercion is performed per ANSI SQL standards when inserting new values into a column
For rest of other new features & enhancements please check Apache Spark 3.0 release notes.
Apache Spark – RDD, DataFrames, Transformations (Narrow & Wide), Actions, Lazy Evaluation (Part 3)

image credits: Databricks
RDD (Resilient Distributed Dataset)
Spark works on the concept of RDDs i.e. “Resilient Distributed Dataset”. It is an Immutable, Fault Tolerant collection of objects partitioned across several nodes. With the concept of lineage RDDs can rebuild a lost partition in case of any node failure.
– In Spark initial versions RDDs was the only way for users to interact with Spark with its low-level API that provides various Transformations and Actions.
– With Spark 2.x new DataFrames and DataSets were introduced which are also built on top of RDDs, but provide more high-level structured APIs and more benefits over RDDs.
– But at the Spark core ultimately all Spark computation operations and high-level DataFrames APIs are converted into low-level RDD based Scala bytecode, which are executed in Spark Executors.
–> RDDs can be created in various ways, like:
1. Reading a file from local file system:
val FileRDD = spark.read.textFile("/mnt/test/hello.txt")
FileRDD.collect()
2. from a local collection by using parallelize method”
val myCol = "My Name is Manoj Pandey".split(" ")
val myRDD = spark.sparkContext.parallelize(myCol, 2)
myRDD.collect().foreach(println)
3. Transforming an existing RDD:
val myCol = "My Name is Manoj Pandey. I stay in Hyderabad".split(" ")
val myRDD = spark.sparkContext.parallelize(myCol, 2)
val myRDD2 = myRDD.filter(s => s.contains("a"))
myRDD2.collect().foreach(println)
–> One should only use RDDs if working with raw and unstructured data, or don’t worry about schema and optimization & performance benefits available with DataFrames.
DataFrames
Just like RDDs, DataFrames are also Immutable collection of objects distributed/partitioned across several nodes. But unlike RDD, a DataFrame is like a table in RDBMS organized into columns and rows, columns with specific schema and datatypes like integer, date, string, timestamp, etc.
– DataFrames also provides optimization & performance benefits with the help of Catalyst Optimizer.
– As mentioned above the Spark Catalyst Optimizer always converts a DataFrame to low-level RDD transformations.
1. A simple example to create a DataFrame by reading a CSV file:
val myDF = spark
.read
.option("inferSchema", "true")
.option("header", "true")
.csv("""/dbfs/csv/hello.csv""")
display(myDF)
2. Creating a DataFrame by using Seq collection and using toDF() method:
val myDF = Seq(("Male", "Brock", 30),
("Male", "John", 31),
("Male", "Andy", 35),
("Female", "Jane", 25),
("Female", "Maria", 30)).toDF("gender", "name", "age")
display(myDF)
3. Creating a new DataFrame from an existing DataFrame by using groupBy() method over it:
import org.apache.spark.sql.functions._
val myDF = Seq(("Male", "Brock", 30),
("Male", "John", 31),
("Male", "Andy", 35),
("Female", "Jane", 25),
("Female", "Maria", 30)).toDF("gender", "name", "age")
val DFavg = myDF.groupBy("gender").agg(avg("age"))
display(DFavg)
4. Creating a DataFrame from an existing RDD:
val myCol = "My Name is Manoj Pandey".split(" ")
val myRDD = spark.sparkContext.parallelize(myCol, 2)
val myDF = myRDD.toDF()
display(myDF)
5. DataFrames can also be converted to Tables or Views (temp-Tables) so that you can use Spark SQL queries instead of applying Scala Transformations:
myDF.createOrReplaceTempView("tblPerson")
display(spark.sql("""
select gender, AVG(age) as AVGAge
from tblPerson
group by gender
"""))
Transformations
In Spark RDDs and DataFrames are immutable, so to perform several operations on the data present in a DataFrame, it is transformed to a new DataFrame without modifying the existing DataFrame.
–> There are two types of Transformations:
1. Narrow Transformations: applies on a single partition, for example: filter(), map(), contains() can operate in single partition and no data exchange happens here between partitions.
2. Wide Transformations: applies on a multiple partitions, for example: groupBy(), reduceBy(), orderBy() requires to read other partitions and exchange data between partitions which is called shuffle and Spark has to write data to disk.
Lazy Evaluation
Both the above Narrow & Wide Transformation types are lazy in nature, means that until and unless any action is performed over these transformations the execution of all these transformations is delayed and Lazily evaluated. Due to this delay the Spark execution engine gets a whole view of all the chained transformations and ample time to optimize your query.
Actions
As Transformations don’t execute anything on their own, so to execute the chain of Transformations Spark needs some Actions to perform and triggers the Transformations.
Some examples of Actions are: count(), collect(), show(), save(), etc. to perform different operations like: to collect data of objects, show calculated data in a console, and write data to a file or target data sources.
Apache Spark – main Components & Architecture (Part 2)
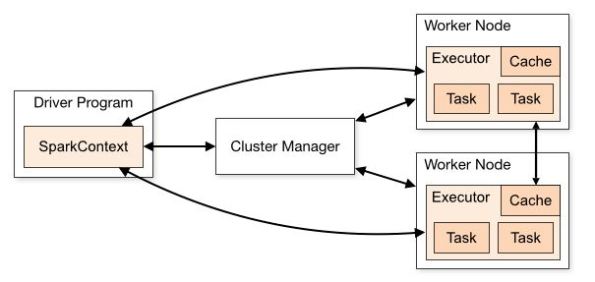
1. Spark Driver:
– The Driver program can run various operations in parallel on a Spark cluster.
– It is responsible to communicate with the Cluster Manager for allocation of resources for launching Spark Executors.
– And in parallel it instantiates SparkSession for the Spark Application.
– The Driver program splits the Spark Application into one or more Spark Jobs, and each Job is transformed into a DAG (Directed Acyclic Graph, aka Spark execution plan). Each DAG internally has various Stages based upon different operations to perform, and finally each Stage gets divided into multiple Tasks such that each Task maps to a single partition of data.
– Once the Cluster Manager allocates resources, the Driver program works directly with the Executors by assigning them Tasks.
2. Spark Session:
– A SparkSession provides a single entry point to interact with all Spark functionalities and the underlying core Spark APIs.
– For every Spark Application you’ve to create a SparkSession explicitly, but if you are working from an Interactive Shell the Spark Driver instantiates it implicitly for you.
– The role of SparkSession is also to send Spark Tasks to the executors to run.
3. Cluster Manager:
– Its role is to manage and allocate resources for the cluster nodes on which your Spark application is running.
– It works for Spark Driver and provides information about available Executor nodes and schedule Spark Tasks on them.
– Currently Spark supports built-in standalone cluster manager, Hadoop YARM, Apache Mesos and Kubernetes.
4. Spark Executor:
– By now you would have known what are Executors.
– These executes Tasks for an Spark Application on a Worker Node and keep communication with the Spark Driver.
– An Executor is actually a JVM running on a Worker node.
Apache Spark – Introduction & main features (Part 1)

Apache Spark is an open source, unified analytics engine, designed for distributed big data processing and machine learning.
Although Apache Hadoop was still there to cater for Big Data workloads, but its Map-Reduce (MR) framework had some inefficiencies and was hard to manage & administer.
– A typical Hadoop program involves multiple iterative MR jobs which loads data to disk and reads again in every iteration, thus involves latency and performance issues.
– Hadoop also provides SQL like ad-hoc querying capability thru Pig & Hive, but due to MR it involves writing/reading data to/from disks, which makes it much slower and gives a bad experience when you need quick data retrieval.
– Thus the creators of Hadoop MR at UC Berkeley lab took this problem as an opportunity and came up with a project called Spark, which was written in Scala and is 10-100 times faster compared to Hadoop MR.
The main features of Spark are:
1. Speed: It is much more faster in processing and crunching large scale data compared to traditional databases engines and MapReduce Hadoop jobs. With in-memory storage and computation of data it provides high performance batch & streaming processing. Not only this but features like DAG scheduler, Query Optimizer, Tungsten execution engine, etc. makes Spark blazingly fast.
2. Modularity & Generality: For different kind of workloads Spark provides multiple components in its core like SQL, Structured Streaming, MLlib for Machine Learning, and GraphX (all as separate modules but unified under one engine).
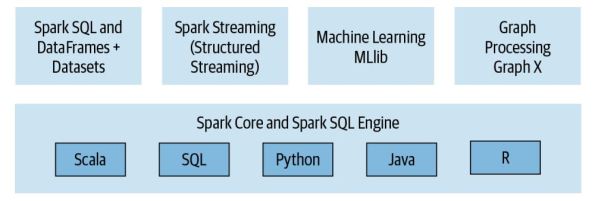
3. Ease of use (Polyglot): To write your apps Spark provides multiple programming languages of your choice which you are comfortable with, like Scala, SQL, Python, Java & R. It also provides n number of APIs & libraries for you to quickly build your apps without going through a steep learning curve.
4. Extensibility: With Spark you can read data from multiple heterogeneous sources like HDFS, HBase, Apache Hive, Azure Blob Storage, Amazon S3, Apache Kafka, Kinesis, Cassandra, MongoDB, etc. and other traditional databases (RDBMSs). Spark also supports reading various file formats, such as CSV, Text, JSON, Parquet, ORC, Avro, etc. and from RDBMS tables.

5. Resilient (Fault Tolerant): Spark works on the concept of RDDs i.e. “Resilient Distributed Dataset”. It is a Fault Tolerant collection of objects partitioned across several nodes. With the concept of lineage RDDs can rebuild a lost partition in case of any node failure.
6. Runs Anywhere: Spark runs on multiple platforms like standalone cluster manager, Hadoop Yarn, Apache Mesos and Kubernetes.



![]()
Current Visitors

StatCounter …since April 2012

 Leisure blog: Creek & Trails
Leisure blog: Creek & Trails
- NMDC Hyderabad Marathon – My first 42k FM, cramps, training and fuelling
- Singapore (Part 2) – 6 days itinerary, sightseeing & attractions
- Singapore (Part 1) – Tickets, Visa, Hotel, Forex Card/Cash, Metro/Bus cards
- I got full refund of my flight tickets during COVID lockdown (AirIndia via MakeMyTrip)
- YouTube – Your Google Ads account was cancelled due to no spend
- YouTube latest update on its YPP (YouTube Partner Program) which may affect your channel
- Starting your own blog !!!
- How to file ITR (Income Tax Return) online AY 2017-18 (for simple salaried)
- Scam – Become a kin/hier and earn a fortune – via LinkedIn and Email
- Places to visit in and around Vizag (aka Visakhapatnam)
