Archive
Python – Delete/remove unwanted rows from a DataFrame
As you start using Python you will fall in love with it, as its very easy to solve problems by writing complex logic in very simple, short and quick way. Here we will see how to remove rows from a DataFrame based on an invalid List of items.
Let’s create a sample Pandas DataFrame for our demo purpose:
import pandas as pd
sampleData = {
'CustId': list(range(101, 111)),
'CustomerName': ['Cust'+str(x) for x in range(101, 111)]}
cdf = pd.DataFrame(sampleData)
invalidList = [102, 103, 104]
The above logic in line # 4 & 5 creates 10 records with CustID ranging from 101 to 110 and respective CustomerNames like Cust101, Cust102, etc.
In below code we will use isin() function to get us only the records present in Invalid list. So this will fetch us only 3 invalid records from the DataFrame:
df = cdf[cdf.CustId.isin(invalidList)] df
And to get the records not present in InvalidList we just need to use the “~” sign to do reverse of what we did in above step using the isin() function. So this will fetch us other 7 valid records from the DataFrame:
df = cdf[~cdf.CustId.isin(invalidList)] df
Python error – Length of passed values is 6, index implies 2 (while doing PIVOT with MultiIndex or multiple columns)
As I’m new to Python and these days using it for some Data Analysis & Metadata handling purpose, and also being from SQL background here I’m trying to use as many analysis features I use with SQL, like Group By, Aggregate functions, Filtering, Pivot, etc.
Now I had this particular requirement to PIVOT some columns based on multi-index keys, or multiple columns as shown below:

But while using PIVOT function in Python I was getting this weird error that I was not able to understand, because this error was not coming with the use of single index column.
ValueError: Length of passed values is 6, index implies 2.
Let’s create a sample Pandas DataFrame for our demo purpose:
import pandas as pd
sampleData = {
'Country': ['India', 'India', 'India','India','USA','USA'],
'State': ['UP','UP','TS','TS','CO','CO'],
'CaseStatus': ['Active','Closed','Active','Closed','Active','Closed'],
'Cases': [100, 150, 300, 400, 200, 300]}
df = pd.DataFrame(sampleData)
df
Problem/Issue:
But when I tried using the below code which uses pivot() function with multiple columns or multi-indexes it started throwing error. I was not getting error when I used single index/column below. So what could be the reason?
# Passing multi-index (or multiple columns) fails here:
df_pivot = df.pivot(index = ['Country','State'],
columns = 'CaseStatus',
values = 'Cases').reset_index()
df_pivot
Solution #1
Online checking I found that the pivot() function only accepts single column index key (do not accept multiple columns list as index). So, in this case first we would need to use set_index() function and set the list of columns as shown below:
# Use pivot() function with set_index() function:
df_pivot = (df.set_index(['Country', 'State'])
.pivot(columns='CaseStatus')['Cases']
.reset_index()
)
df_pivot
Solution #2
There is one more simple option where you can use pivot_table() function as shown below and get the desired output:
# or use pivot_table() function:
df_pivot = pd.pivot_table(df,
index = ['Country', 'State'],
columns = 'CaseStatus',
values = 'Cases')
df_pivot
Cosmos DB & PySpark – Retrieve all attributes from all Collections under all Databases
In one of my [previous post] we saw how to retrieve all attributes from the items (JSON document) of all Collections under all Databases by using C# .net code.
Here in this post we will see how we can retrieve the same information in Azure Databricks environment by using Python language instead of C# .net code.
So first of all you need to make sure that you have the Azure Cosmos DB SQL API library installed in your Databricks cluster. [Link if not done]
Then use the below script which:
1. First connects to Cosmos DB by using the CosmosClient() method.
2. Then it gets list of all Databases by using list_databases() method
3. Then iterate thru all databases and get list of all Containers by using list_containers() method.
4. Now again iterating thru all Containers and querying the items using the query_items() method.
5. The “metadataInfo” dictionary object is storing all the Keys & Values present in the Container item.
6. Then the List object with name “metadataList” stores all the Database, Container & Item level details stored in “metadataInfo” dictionary.
6. Finally we used the “metadataList” object to create a DataFrame by using createDataFrame() method.
Get the Cosmos Uri & Primary Key from the Cosmos DB Overview tab and apply in the code below:
import azure.cosmos.cosmos_client as cosmos_client
import azure.cosmos.errors as errors
import azure.cosmos.exceptions as exceptions
import azure.cosmos.http_constants as http_constants
import json
cosmosUri = "https://YourCosmosDBName.documents.azure.com:443/"
pKey = "PrimaryKey=="
client = cosmos_client.CosmosClient(cosmosUri, {'masterKey': pKey})
cosmosDBsList = client.list_databases()
#Create a list to store the metadata
metadataList = []
#Iterate over all DBs
for eachCosmosDBsList in cosmosDBsList:
#print("nDatabase Name: {}".format(eachCosmosDBsList['id']))
dbClient = client.get_database_client(eachCosmosDBsList['id'])
#Iterate over all Containers
for containersList in dbClient.list_containers():
#print("n- Container Name: {}".format(containersList['id']))
conClient = dbClient.get_container_client(containersList['id'])
#Query Container and read just TOP 1 row
for queryItems in conClient.query_items("select top 1 * from c",
enable_cross_partition_query=True):
for itemKey, itemValue in queryItems.items():
#print(itemKey, " = ", itemValue)
#Create a dictionary to store metedata info at attribute/field level
metadataInfo = {}
metadataInfo["Source"] = eachCosmosDBsList['id']
metadataInfo["Entity"] = containersList['id']
metadataInfo["Attribute"] = itemKey
metadataInfo["Value"] = itemValue
metadataList.append(metadataInfo)
#print(metadataList)
from pyspark.sql.types import *
mySchema = StructType([ StructField("Source", StringType(), True)
,StructField("Entity", StringType(), True)
,StructField("Attribute", StringType(), True)
,StructField("Value", StringType(), True)])
df = spark.createDataFrame(metadataList, schema=mySchema)
df.createOrReplaceTempView("metadataDF")
display(df)
SQL Python Error – ‘sp_execute_external_script’ is disabled on this instance of SQL Server. Use sp_configure ‘external scripts enabled’ to enable it.
You are running a Python script by using sp_execute_external_script SP but its throwing this error:
Msg 39023, Level 16, State 1, Procedure sp_execute_external_script, Line 1 [Batch Start Line 27]
‘sp_execute_external_script’ is disabled on this instance of SQL Server. Use sp_configure ‘external scripts enabled’ to enable it.
You can refer to my blog post on setting up ML with Python with SQL Server, link: https://sqlwithmanoj.com/2018/08/10/get-started-with-python-on-sql-server-run-python-with-t-sql-on-ssms/
This fix will also work with R support with SQL Server.
Get started with Python on SQL Server – Run Python with T-SQL on SSMS
With SQL Server 2016 Microsoft added Machine Learning support with R Language in SQL engine itself and called it SQL Server R Services.
Going ahead with the new SQL Server 2017 version Microsoft added Python too as part of Machine Learning with existing R Language, and thus renamed it to SQL Server Machine Learning Services.
Installation/Setup
Here are few steps to get you started with Python programming in SQL Server, so that you can run Python scripts with T-SQL scripts within SSMS:
1. Feature Selection: While installing SQL Server 2017 make sure you’ve selected below highlighted services

2. Configure “external scripts enabled”: Post installation run below SQL statements to enable this option
sp_configure 'external scripts enabled' GO sp_configure 'external scripts enabled', 1; GO RECONFIGURE; GO sp_configure 'external scripts enabled' GO
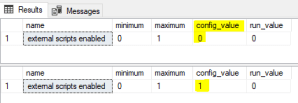
3. Restart SQL Server service: by “services.msc” program from command prompt, and run below SQL statement, this should show run _value = 1
sp_configure 'external scripts enabled' GO

If still you don’t see run _value = 1, then try restarting the Launchpad service mentioned below in Step #4.
4. Launchpad Service: Make sure this service is running, in “services.msc” program from command prompt. Restart the service, and it should be in Running state.
Its a service to launch Advanced Analytics Extensions Launchpad process that enables integration with Microsoft R Open using standard T-SQL statements. Disabling this service will make Advanced Analytics features of SQL Server unavailable.

Post restarting this service, it should return run _value = 1 on running the query mentioned at Step #3
Run Python from SSMS
So as you’ve installed SQL Server with ML services with Python & R, and enabled the components, now you can try running simple “Hello World!” program to test it:
EXEC sp_execute_external_script
@language = N'Python',
@script = N'print(''Hello Python !!! from T-SQL'')'
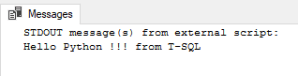
Let’s do simple math here:
EXEC sp_execute_external_script @language = N'Python', @script = N' x = 5 y = 6 a = x * y b = x + y print(a) print(b)'
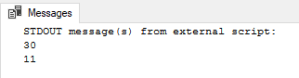
If you still face issues you can go through addition configuration steps mentioned in [MSDN Docs link].


![]()
Current Visitors

StatCounter …since April 2012

 Leisure blog: Creek & Trails
Leisure blog: Creek & Trails
- NMDC Hyderabad Marathon – My first 42k FM, cramps, training and fuelling
- Singapore (Part 2) – 6 days itinerary, sightseeing & attractions
- Singapore (Part 1) – Tickets, Visa, Hotel, Forex Card/Cash, Metro/Bus cards
- I got full refund of my flight tickets during COVID lockdown (AirIndia via MakeMyTrip)
- YouTube – Your Google Ads account was cancelled due to no spend
- YouTube latest update on its YPP (YouTube Partner Program) which may affect your channel
- Starting your own blog !!!
- How to file ITR (Income Tax Return) online AY 2017-18 (for simple salaried)
- Scam – Become a kin/hier and earn a fortune – via LinkedIn and Email
- Places to visit in and around Vizag (aka Visakhapatnam)
