Archive
SQL Trivia – Difference between COUNT(*) and COUNT(1)
Yesterday I was having a discussion with one of the Analyst regarding an item we were going to ship in the release. And we tried to check and validate the data if it was getting populated correctly or not. To just get the count-diff of records in pre & post release I used this Query:
SELECT COUNT(*) FROM tblXYZ
To my surprise he mentioned to use COUNT(1) instead of COUNT(*), and the reason he cited was that it runs faster as it uses one column and COUNT(*) uses all columns. It was like a weird feeling, what to say… and I just mentioned “It’s not, and both are same”. He was adamant and disagreed with me. So I just kept quite and keep on using COUNT(*) 🙂
But are they really same or different? Functionally? Performance wise? or by any other means?
Let’s check both of them.
The MSDN BoL lists the syntax as COUNT ( { [ [ ALL | DISTINCT ] expression ] | * } )
So, if you specify any numeric value it come under the expression option above.
Let’s try to pass the value as 1/0, if SQL engine uses this value it would definitely throw a “divide by zero” error:
SELECT COUNT(1/0) FROM [Person].[Person]
… but it does not. Because it just ignores the value while taking counts. So, both * and 1 or any other number is same.
–> Ok, let’s check the Query plans:

and there was no difference between the Query plans created by them, both have same query cost of 50%.
–> These are very simple and small queries so the above plan might be trivial and thus may have come out same or similar.
So, let’s check more, like the PROFILE stats:
SET STATISTICS PROFILE ON SET STATISTICS IO ON SELECT COUNT(*) FROM [Sales].[SalesOrderDetail] SELECT COUNT(1) FROM [Sales].[SalesOrderDetail] SET STATISTICS PROFILE OFF SET STATISTICS IO OFF
If you check the results below, the PROFILE data of both the queries shows COUNT(*), so the SQL engine converts COUNT(1) to COUNT(*) internally.
SELECT COUNT(*) FROM [Sales].[SalesOrderDetail]
|--Compute Scalar(DEFINE:([Expr1002]=CONVERT_IMPLICIT(int,[Expr1003],0)))
|--Stream Aggregate(DEFINE:([Expr1003]=Count(*)))
|--Index Scan(OBJECT:([AdventureWorks2014].[Sales].[SalesOrderDetail].[IX_SalesOrderDetail_ProductID]))
SELECT COUNT(1) FROM [Sales].[SalesOrderDetail]
|--Compute Scalar(DEFINE:([Expr1002]=CONVERT_IMPLICIT(int,[Expr1003],0)))
|--Stream Aggregate(DEFINE:([Expr1003]=Count(*)))
|--Index Scan(OBJECT:([AdventureWorks2014].[Sales].[SalesOrderDetail].[IX_SalesOrderDetail_ProductID]))
–> On checking the I/O stats there is no difference between them:
Table 'SalesOrderDetail'. Scan count 1, logical reads 276, physical reads 1, read-ahead reads 288, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'SalesOrderDetail'. Scan count 1, logical reads 276, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Both the queries does reads of 276 pages, no matter they did logical/physical/read-ahead reads here. Check difference b/w logical/physical/read-ahead reads.
So, we can clearly and without any doubt say that both COUNT(*) & COUNT(1) are same and equivalent.
There are few other things in SQL Server that are functionally equivalent, like DECIMAL & NUMERIC datatypes, check here: Difference b/w DECIMAL & NUMERIC datatypes.
SQL Myth | Nested Transactions in SQL Server and hidden secrets
There is no concept of Nested Transactions in SQL Server, Period.
There can be workarounds but Nested Transactions is not out of the box.
–> In my [previous post] we saw a scenario where you have a Nested Transaction. And we saw issues with Rolling back the inner Transaction and handling them gracefully with the Outer Transactions, which typically looked like this:

–> Here we will see how the nested Transactions behave internally by executing these SQL statements in chunks.
1. First of all we will create a sample table and execute the code till BEGIN outerTran section:
USE [tempdb] GO CREATE TABLE dbo.TranTest (ID INT) GO CHECKPOINT GO -- Outer Transaction - BEGIN SELECT @@TRANCOUNT AS 'outerTran Begin', count(*) from dbo.TranTest -- 0, 0 BEGIN TRANSACTION outerTran INSERT INTO dbo.TranTest values(1) SELECT @@TRANCOUNT AS 'outerTran Begin', count(*) from dbo.TranTest -- 1, 1
– This was a simple one, one row got inserted with Transaction Count = 1, but its not committed yet.
– Let’s see the Transaction status by using the undocumented function fn_dblog(), how these are tracked in the DB Engine:
SELECT Operation, [Transaction ID], Description, Context FROM fn_dblog(NULL, NULL) WHERE [Transaction ID] IN ( SELECT [Transaction ID] FROM fn_dblog(NULL, NULL) WHERE [Description] like '%Tran%')

As you can see in the output above:
– The Outer BEGIN TRANSACTION statement is logged as LOP_BEGIN_XACT Operation and Description = ‘outerTran;0x01…’ for the outer Transaction.
– and INSERT statement is logged as LOP_INSERT_ROWS operation.
2. Now let’s execute the next section with the inner Transaction:
-- Inner Transaction BEGIN TRANSACTION innerTran INSERT INTO dbo.TranTest values(2) SELECT @@TRANCOUNT AS 'innerTran Begin', count(*) from dbo.TranTest -- 2, 2 COMMIT TRANSACTION innerTran SELECT @@TRANCOUNT AS 'innerTran Rollback', count(*) from dbo.TranTest -- 1, 2
– The first SELECT statement before the COMMIT statement gives count of two for the inserted rows in the table, with Transaction Count = 2.
– And after COMMIT Transaction the second SELECT statement gives Transaction count = 1.
– Let’s execute the same function and see the Transaction status:
SELECT Operation, [Transaction ID], Description, Context FROM fn_dblog(NULL, NULL) WHERE [Transaction ID] IN ( SELECT [Transaction ID] FROM fn_dblog(NULL, NULL) WHERE [Description] like '%Tran%')

– Here we don’t see any row for the inner Transaction with LOP_BEGIN_XACT Operation.
– A separate row is logged for the second INSERT statement as LOP_INSERT_ROWS operation with the same Transaction ID = ‘0000:00000992’.
Thus, this inner Transaction points to the Outer Transaction internally.
–> Now we will see what happens when we COMMIT or ROLLBACK the outer Transaction:
3.a. So, let’s COMMIT the outer Transaction first:
-- Outer Transaction - COMMIT COMMIT TRANSACTION outerTran SELECT @@TRANCOUNT AS 'outerTran Commit', count(*) from dbo.TranTest -- 0, 2 GO SELECT * FROM dbo.TranTest -- 2 GO
– After the COMMIT statement the second SELECT statement gives Transaction count = 0, and there is no active Transaction left.
– And the final SELECT lists the 2 records inserted in the outer & inner Transactions.
Now again let’s execute the same function and see the Transaction status:
SELECT Operation, [Transaction ID], Description, Context FROM fn_dblog(NULL, NULL) WHERE [Transaction ID] IN ( SELECT [Transaction ID] FROM fn_dblog(NULL, NULL) WHERE [Description] like '%Tran%')

– When COMMITTING the Outer Transaction it is logged as LOP_COMMIT_XACT Operation with the same Transaction ID = ‘0000:00000992’.
3.b. In case of ROLLBACK lets see what happens: You will need to execute all the SQL statements in Step 1 to 3 again.
-- Outer Transaction - COMMIT COMMIT TRANSACTION outerTran SELECT @@TRANCOUNT AS 'outerTran Commit', count(*) from dbo.TranTest -- 0, 2 GO SELECT * FROM dbo.TranTest -- 2 GO DROP TABLE dbo.TranTest GO
Now again let’s execute the same function and see the Transaction status:
SELECT Operation, [Transaction ID], Description, Context FROM fn_dblog(NULL, NULL) WHERE [Transaction ID] IN ( SELECT [Transaction ID] FROM fn_dblog(NULL, NULL) WHERE [Description] like '%Tran%')

As the outer Transaction is ROLLEDBACKED the inner Transaction also also gets Rollebacked, and thus you can see:
– two DELETE logged rows for the two INSERTed rows above, with LOP_DELETE_ROWS Operation and Description = COMPENSATION.
– and final ROLLBACK log with LOP_ABORT_XACT Operation with the same Transaction IDs.
The above exercise shows us that SQL Server only tracks the outermost Transaction, and do not bother about the inner Transactions.
–> So what’s the Hidden Secret?
1. First one is what we saw above, no Nested Transactions.
2. COMMIT TRANSACTION has an option to apply the Transaction name, but the DB Engine simply ignores it and points to the previous BEGIN TRANSACTION statement. Thus while issuing a COMMIT TRANSACTION referencing the name of an outer transaction when there are outstanding inner transactions it only decrements the @@TRANCOUNT value by 1.
3. ROLLBACK TRANSACTION also have an option to apply the Transaction name, but you can only apply the outermost Transaction name in case of Nested Transactions. While using ROLLBACK in inner Transactions you have to use either just ROLLBACK TRANSACTION or ROLLBACK TRANSACTION SavePoint_name, only if the inner transaction are created with SAVE TRANSACTION option instead of BEGIN TRANSACTION.
4. ROLLBACK TRANSACTION SavePoint_name does not decrement @@TRANCOUNT value.
Thus it is advised be careful while using Nested Transactions, ROLLBACKS and SavePoints, or just simply ignore them.
SQL Myth | Primary Key (PK) always creates Clustered Index
… and this a default nature, which can be overrided to create a PK with a Non-Clustered Index instead of a Clustered one.
– What happens when a Primary Key is created on a table?
– If I have a PK on a table will the table be a Heap or not?
– Can I create a PK with a Non-Clustered Index? (this is a big hint)
While Interviewing candidates I’ve confronted them with these type of question, and very few were able to answer these correctly.
–> So, here we will see the default behavior of Primary Keys and how we can override it:
–> Having the “PRIMARY KEY” option inline with the column name: While creating a new table when you specify a “PRIMARY KEY” option inline with the Key Column, by-default it creates a Clustered Index on that table with a PK Constraint on that column.
USE [tempdb] GO CREATE TABLE dbo.Employee ( EmpID INT NOT NULL PRIMARY KEY, -- here EmpLogInID VARCHAR(255) NULL, EmpFirstName VARCHAR(255) NOT NULL, EmpLastName VARCHAR(255) NOT NULL, Gender BIT NOT NULL, JobTitle VARCHAR(255) NULL, BOD DATETIME NULL, DOJ DATETIME NULL, DeptID INT NOT NULL ) GO sp_help 'dbo.Employee' GO

The above image shows:
– a Unique Clustered Index created on the [EmpID] column with a name automatically suggested by the DB-engine, and
– a PK Constraint created on the same column.
–> Overriding this behavior by having a “CONSTRAINT” option: Here we will not create the PK inline with the Key Column [EmpID]. But we will:
– have a separate PK constraint created with Non-Clustered Index for [EmpID] column, and
– an another SQL statement to create a Clustered Index on the [EmpLogInID] column.
DROP TABLE dbo.Employee GO CREATE TABLE dbo.Employee ( EmpID INT NOT NULL, EmpLogInID VARCHAR(255) NULL, EmpFirstName VARCHAR(255) NOT NULL, EmpLastName VARCHAR(255) NOT NULL, Gender BIT NOT NULL, JobTitle VARCHAR(255) NULL, BOD DATETIME NULL, DOJ DATETIME NULL, DeptID INT NOT NULL CONSTRAINT [PK_Employee_EmpID] PRIMARY KEY NONCLUSTERED (EmpID ASC) -- here ) GO -- Creating the Clustered Index separately on an other column: CREATE CLUSTERED INDEX [CI_Employee_EmpLogInID] ON dbo.Employee(EmpLogInID ASC) GO sp_help 'dbo.Employee' GO

The above image shows:
– a Clustered Index (Non-Unique) created on the [EmpLogInID] column with a name we provided,
– a Non-Clustered Index (Unique) created on the [EmpID] column, and
– a PK Constraint created on the [EmpID] column with a name we provided.
So, it is advised to choose your PK & Clustered/Non-Clustered index wisely based upon a proper and justified Business logic. Please do not consider this as a Use Case, but just an example on how to deal with PKs & Indexes.
Check the video on Primary Keys:

What is ODS (Operational Data Store) and how it differs from Data Warehouse (DW)
I see lot of people discussing about ODS, and citing their own definitions and ideas about it. Some people also use the name as a synonym for a Data Warehouse or Factory Database. Thus, at times it becomes very difficult to tell or convince people while you are designing or architecting a DW/BI solution.
So, I thought to give some time to explain what actually an ODS is.
Simple definition: An Operational Data Store (ODS) is a module in the Data Warehouse that contains the most latest snapshot of Operational Data. It is designed to contain atomic or low-level data with limited history for “Real Time” or “Near Real Time” (NRT) reporting on frequent basis.
Detailed definifion:
– An ODS is basically a database that is used for being an interim area for a data warehouse (DW), it sits between the legacy systems environment and the DW.
– It works with a Data Warehouse (DW) but unlike a DW, an ODS does not contain Static data. Instead, an ODS contains data which is dynamically and constantly updated through the various course of the Business Actions and Operations.
– It is specifically designed so that it can Quickly perform simpler queries on smaller sets of data.
– This is in contrast to the structure of DW wherein it needs to perform complex queries on large sets of data.
– As the Data ages in ODS it passes out of the DW environment as it is.
–> Where does ODS fits in a DW/BI Architecture?

–> Classes of ODS (Types):
Bill Inmon defines 5 classes of ODS shown in image below:
– Class-1 ODS would simply involve Direct Replication of Operational Data (without Transformations), being very Quick.
– Whereas Class-5 ODS would involve high Integration and Aggregation of data (highly Transformed), being a very time-consuming process.

Clustered Index will not always guarantee Sorted Rows
In my previous post I discussed about the how Clustered Index’s Data-Pages and Rows are allocated in memory (Disk). I tried to prove that that Clustered Indexes do not guarantee Physical Ordering of Rows. But instead they are Logically Ordered and Sorted.
As they are Logically Sorted and when you query a table without an “ORDER BY” clause you get Sorted Rows, but this is not what will happen always. You can also get rows in Unsorted Order, so to get Sorted rows always apply an “ORDER BY” clause. Here in this post we will see under what circumstances a table will not return Sorted rows:
–> Let’s create a simple table with a Clustered Index on it and add some records:
-- Create table with 2 columns, first beign a PK and an IDENTITY column: CREATE TABLE test2 ( i INT IDENTITY(1,1) PRIMARY KEY NOT NULL, j INT ) -- Let's insert some records in random order on second column: INSERT INTO test2 (j) SELECT 500 UNION ALL SELECT 300 UNION ALL SELECT 900 UNION ALL SELECT 100 UNION ALL SELECT 600 UNION ALL SELECT 200 -- Now we will query the table without using ORDER BY clause: SELECT * FROM test2
–> Output:

You get sorted rows, as the Execution plan shows that Clustered Index was used to fetch the records.
–> Now, what if this table also has a Non Clustered Index, let’s see:
-- We will create a Non Clustered Index on the same table on second column: CREATE INDEX NCI_test ON test2 (j) -- Again query the table without using ORDER BY clause: SELECT * FROM test2
–> Following is the Output of the second SELECT query above:
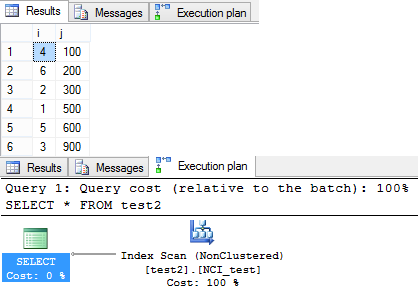
This time the query returned rows in un-ordered fashion. As you can see in the Execution plan Query optimizer preferred to do a Non Clustered Scan. Thus the records were returned in un-ordered fashion.
–> Now, If you add an ORDER BY Clause to your SELECT Query how does it return rows:
-- Added an ORDER BY Clause: SELECT * FROM test2 ORDER BY i
–> Following is the Output of the third SELECT query above:

After adding an “ORDER BY” clause the query optimizer preferd to use the Clustered Index and returns rows in Ordered fashion again.
-- Final Cleanup DROP TABLE test2
So, it is necessary to provide an “ORDER BY” clause to your Queries when you expect to get sorted results, even if the table has Clustered Index on it.


![]()
Current Visitors

StatCounter …since April 2012

 Leisure blog: Creek & Trails
Leisure blog: Creek & Trails
- NMDC Hyderabad Marathon – My first 42k FM, cramps, training and fuelling
- Singapore (Part 2) – 6 days itinerary, sightseeing & attractions
- Singapore (Part 1) – Tickets, Visa, Hotel, Forex Card/Cash, Metro/Bus cards
- I got full refund of my flight tickets during COVID lockdown (AirIndia via MakeMyTrip)
- YouTube – Your Google Ads account was cancelled due to no spend
- YouTube latest update on its YPP (YouTube Partner Program) which may affect your channel
- Starting your own blog !!!
- How to file ITR (Income Tax Return) online AY 2017-18 (for simple salaried)
- Scam – Become a kin/hier and earn a fortune – via LinkedIn and Email
- Places to visit in and around Vizag (aka Visakhapatnam)
