Archive
SQL Trivia – SQL Server Code names
Every time the SQL Server Product team starts working with their new version of SQL Server they give a Code Name to it, and before the final name is announced (which goes with the year name) the Code name gets popular among them, developers, users and the whole SQL community. But sometimes its very tricky and confusing to keep track of the Code Names for the older versions.
So, here is a list of SQL Server various versions I’ve compiled which lists the SQL Server release Final Name with Code Name, and other details like Year released, Version number and OS supported:
| Year | Final Name | Version | Code Name | OS Support |
| 2017 | SQL Server 2017 | 14.0 | Helsinki | Win & Linux |
| 2016 | SQL Server 2016 | 13.0 | – | Windows |
| 2014 | SQL Server 2014 | 12.0 | Hekaton | Windows |
| 2012 | SQL Server 2012 | 11.0 | Denali | Windows |
| 2010 | SQL Server 2008 R2 | 10.5 | Kilimanjaro | Windows |
| 2010 | SQL Azure DB | 10.25 | Cloud DB | Azure |
| 2008 | SQL Server 2008 | 10.0 | Katmai | Windows |
| 2005 | SQL Server Analysis Services | – | Picasso | Windows |
| 2005 | SQL Server 2005 | 9.0 | Yukon | Windows |
| 2003 | SQL Server Reporting Services | – | Rosetta | Windows |
| 2003 | SQL Server 2000 x64 (64 bit) | 8.0 | Liberty | Windows |
| 2000 | SQL Server 2000 x86 (32 bit) | 8.0 | Shiloh | Windows |
| 1999 | SQL Server 7.0 OLAP Services | – | Plato | Windows |
| 1998 | SQL Server 7.0 | 7.0 | Sphinx | Windows |
| 1996 | SQL Server 6.5 | 6.5 | Hydra | Windows |
| 1995 | SQL Server 6.0 | 6.0 | SQL95 | Windows |
| 1993 | SQL Server 4.21 | 4.21 | – | Windows |
| 1992 | SQL Server 4.2 | 4.2 | – | OS/2 |
| 1991 | SQL Server 1.1 (16 bit) | 1.1 | Pietro | OS/2 |
| 1990 | SQL Server 1.0 (16 bit) | 1.0 | Filipi | OS/2 |
You can also check my post on [SQL and its history] !!!
SQL Trivia – How to convert milliseconds to [hh:mm:ss.ms] format
Today for some reporting purpose I need to convert milliseconds to hh:mm:ss.ms format, i.e.
Hours : Minutes : Seconds . Micro-Seconds
So, I tried to create query below, of course by taking help from internet, so that I can have a sample code handy for future reference:
DECLARE @MilliSeconds INT
SET @MilliSeconds = 25289706
SELECT CONCAT(
RIGHT('0' + CAST(@MilliSeconds/(1000*60*60) AS VARCHAR(2)),2), ':', -- Hrs
RIGHT('0' + CAST((@MilliSeconds%(1000*60*60))/(1000*60) AS VARCHAR(2)),2), ':', -- Mins
RIGHT('0' + CAST(((@MilliSeconds%(1000*60*60))%(1000*60))/1000 AS VARCHAR(2)),2), '.', -- Secs
((@MilliSeconds%(1000*60*60))%(1000*60))%1000 -- Milli Secs
) AS [hh:mm:ss.ms]
-- 7 Hrs, 1 minute, 29 seconds and 706 milliseconds

SQL Trivia – Return every Nth row from Table or a result set
So few days back I got a ping from one of my reader, he was asked one question in a SQL Interview and he had a hard time to answer that:
How do you return every Nth row from Table or a result set?
He told he knew how to get top 2nd or top Nth record from a table, but was not able to come up with the logic for this problem.
I told him this can be done easily done by using Modulus “%” (percentage) operator.
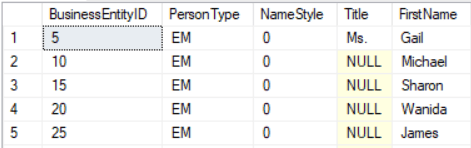
–> Below is the simple logic by using Modulus logic to get consecutive 5th position in the below record-set. Below every row with “0” value (highlighted yellow) is the 5th consecutive position:
select BusinessEntityID % 5 AS [5thPosition], * from [Person].[Person]

–> And by simply moving the above Modulus logic to the WHERE clause will give to filtered rows:
select * from [Person].[Person] where BusinessEntityID % 5 = 0
SQL Trivia – Multiple ways to get list of all tables in a database
This is one of a typical Interview Question you might face while going for an opening of a SQL Developer. This looks very simple question but its also an important question to judge a person if he/she knows SQL basics and has really worked in SQL Server or not.
–> So, here are following ways you can query the SQL Server metadata and system tables to get list of all tables in a particular database, by using:
1. sys.tables
select * from sys.tables
2. sys.objects with filter of type = ‘U’
select * from sys.objects where type = 'U'
3. sys.sysobjects with filter of type = ‘U’
select * from sys.sysobjects where type = 'U'
4. INFORMATION_SCHEMA.TABLES
select * from INFORMATION_SCHEMA.TABLES where TABLE_TYPE = 'TABLE'
5. sp_msforeachtable undocumented function
exec sp_msforeachtable 'print ''?'''
Out of all these the best option is to use the 4th one, i.e. INFORMATION_SCHEMA.TABLES views, as Microsoft itself suggest to use it instead of first three & the 5th option.
SQL Trivia – What all schemas cannot be dropped in a SQL Server database?
–> The following four built-in database schemas cannot be dropped:
1. The “dbo” schema: is the default database schema for new objects created by users having the db_owner or db_ddl_admin roles. The dbo schema is owned by the dbo user account. By default, users created with the CREATE USER Transact-SQL command have dbo as their default schema.
2. The “guest” schema: is used to contain objects that would be available to the guest user. This schema is rarely used.
3. The “sys” schema: is reserved by SQL Server for system objects such as system tables and views.
4. The “INFORMATION_SCHEMA” schema: is used by the Information Schema views, which provide ANSI standard access to metadata. This schema is contained in each database. Each information schema view contains metadata for all data objects stored in that particular database. Information schema views are based on sys catalog view definitions.
… notes from: Training Kit (Exam 70-461) Querying Microsoft SQL Server 2012


![]()
Current Visitors

StatCounter …since April 2012

 Leisure blog: Creek & Trails
Leisure blog: Creek & Trails
- NMDC Hyderabad Marathon – My first 42k FM, cramps, training and fuelling
- Singapore (Part 2) – 6 days itinerary, sightseeing & attractions
- Singapore (Part 1) – Tickets, Visa, Hotel, Forex Card/Cash, Metro/Bus cards
- I got full refund of my flight tickets during COVID lockdown (AirIndia via MakeMyTrip)
- YouTube – Your Google Ads account was cancelled due to no spend
- YouTube latest update on its YPP (YouTube Partner Program) which may affect your channel
- Starting your own blog !!!
- How to file ITR (Income Tax Return) online AY 2017-18 (for simple salaried)
- Scam – Become a kin/hier and earn a fortune – via LinkedIn and Email
- Places to visit in and around Vizag (aka Visakhapatnam)
