Archive
Informatica – The first character in a name cannot be a number (error)
Today while creating a mapping by using import method & template I got a pop-up with following error message in Designer:
03/30/2016 16:30:55 **** Importing Source Definition: tblCustomerResults ...
: The first character in a name cannot be a number.
** Failed to Import: tblCustomerResults
03/30/2016 16:30:55 **** Importing Target Definition: tblCustomerResults ...
: A column with the name 120_-_Unknown already exists.
Please enter a unique name.
** Failed to Import: tblCustomerResults
03/30/2016 16:30:56 **** Importing Mapping: mACQtblCustomerResults ...
: Could not find Transformation definition for: tblCustomerResults
** Failed to Import: mACQtblCustomerResults
With the above error its quiet evident that Informatica do not support column names that starts with a number. But to confirm I checked online and found it to be true and one of the biggest limitation in Informatica.
As a workaround:
1. I dropped the Source Connection pointing to the Original source.
2. I created the Source table in my Database and re-created the Source Connection pointing to this table.
3. Save and export the Source XML.
4. Finally Import the mapping by using same template and the new Source XML, successful 🙂
I also found that this limitation is not only with columns, but also with Source Table Name, Database Definition (DBD) name, Repository Folders, etc.
Informatica – WRT_8229, Multiple-step OLE DB operation generated errors. Check each OLE DB status value, if available. No work was done.
Working with Informatica is fun, but challenging at times, don’t know if this is the same other ETL tools, like SSIS, etc.
Today, while running a Workflow I was getting an error on a session, and due to this the rows were not getting inserted from Source to Target table. The error is as follows:
Severity: ERROR
Timestamp: 1/25/2016 3:37:43 PM
Node: node03_AZxyzxyzxyzxyz
Thread: WRITER_1_*_1
Process ID: 7180
Message Code: WRT_8229
Message: Database errors occurred: Microsoft OLE DB Provider for SQL Server: Multiple-step OLE DB operation generated errors. Check each OLE DB status value, if available. No work was done.
Database driver error…
Function Name : Execute Multiple
SQL Stmt : INSERT INTO dbo.Contact (Id,Name,Description,CreatedBy,CreatedOn,ModifiedBy,ModifieOn,RowCheckSum) VALUES ( ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)

I check all the place and at last found that the last column “RowCheckSum” as mentioned in the error above, was not present in my Target table.
So, I just went ahead and added this column with simple “ALTER TABLE ADD COLUMN” statement.
And post this fix, my Workflow ran without any issues, and I got the table populated as expected.
Informatica – There is no Integration Service found for this workflow (error)
Today while executing a new Informatica Workflow that I designed I got a pop-up with following error message:
“There is no Integration Service found for this workflow”

The Workflow was not getting kicked off and there was nothing else showing up other than the error message box.
Thus, I did a bit research and as the error message indicates found that the Workflow needs to be linked to an Integration Service so that the data movement could be enabled from Source to the Target.
The Informatica Integration Service (or infasvcs) acts as a controller for entire workflow execution. Integration Service gets into action whenever a workflow is kicked off (either manually or by schedule). It reads Workflow, Session/Task and Mapping information from Repository Database and performs the execution as per transformations defined.
–> Right-click on the Workflow Designer and this opens up following window, which shows the Integration Service text box empty, below:

… you just need to click on the button adjacent to it (circled, above), which opens up following window:
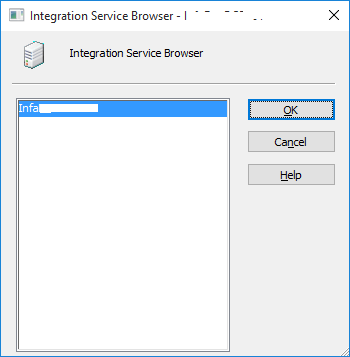
… here, you just need to select the Integration Services listed and click OK. Post this you will see the text box populated with the Integration Service name.
–> But if you want this to be assigned for more than one Workflow or to be executed with different Integration Service than you can go with this approach:
Close all the Workflow Folders.
And in main-menu click Services –> Assign Integration Service

… this will open following window below, and here you can select more than one Workflow and select Integration Services for them:

Informatica – ERROR: Workflow [FOLDER_NAME:WORKFLOW_NAME[version 1]] is disabled. Please check the Integration Service log for more information.
Today I got an email alert for the Informatica Workflow that was working properly suddenly gave following error:
ERROR: Workflow [FOLDER_NAME:WORKFLOW_NAME[version 1]] is disabled.
Please check the Integration Service log for more information.
The Workflow was not getting kicked off and there was nothing else showing up in the logs other than this error.
I did a bit of research and as the error message indicates I found that one setting might be enabled that can disable the Workflow.
–> I opened the Workflow Designer, opened the Workflow in the Designer window. Right-click on the Workflow Designer canvas and this opens up following window, which shows up as below:
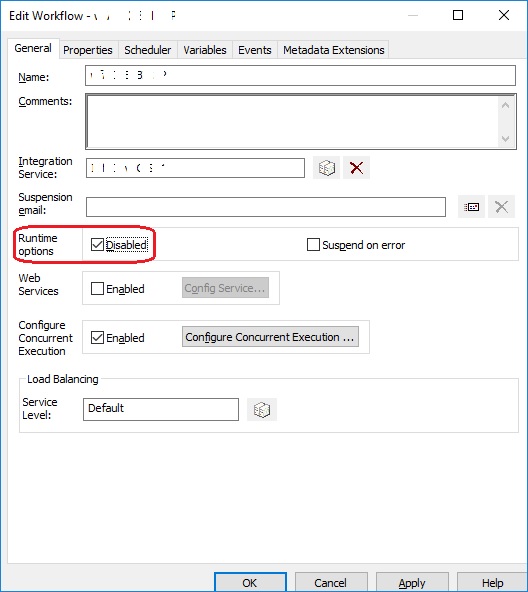
… here as you can see that the setting “Runtime Options, Disabled” is checked/enabled (circled, above). This means that the Workflow is currently in disabled state. Just un-check this option and save it by clicking on the Apply button.
Now re-run the Workflow and it should run now without any issues.



![]()
Current Visitors

StatCounter …since April 2012

 Leisure blog: Creek & Trails
Leisure blog: Creek & Trails
- NMDC Hyderabad Marathon – My first 42k FM, cramps, training and fuelling
- Singapore (Part 2) – 6 days itinerary, sightseeing & attractions
- Singapore (Part 1) – Tickets, Visa, Hotel, Forex Card/Cash, Metro/Bus cards
- I got full refund of my flight tickets during COVID lockdown (AirIndia via MakeMyTrip)
- YouTube – Your Google Ads account was cancelled due to no spend
- YouTube latest update on its YPP (YouTube Partner Program) which may affect your channel
- Starting your own blog !!!
- How to file ITR (Income Tax Return) online AY 2017-18 (for simple salaried)
- Scam – Become a kin/hier and earn a fortune – via LinkedIn and Email
- Places to visit in and around Vizag (aka Visakhapatnam)
