Archive
SQL Basics – AGGREGATE Functions in SQL Server
Aggregate Functions provides us basic calculation over a group or a set of values. Aggregate functions are deterministic functions as they return the same value every time they are called by using a specific set of input values.
The Basic Aggregate Functions used day today in SQL Server are: COUNT, MIN, MAX, SUM, AVG.
You can use below query to create an Employee table for this demo:
USE [AdventureWorks2014]
GO
DROP TABLE IF EXISTS dbo.Employee
SELECT
P.BusinessEntityID AS EmpID, P.Title, P.FirstName, P.MiddleName, P.LastName,
E.Gender, E.MaritalStatus, E.BirthDate AS DOB, E.HireDate AS DOJ, E.JobTitle,
D.Name AS DeptName, S.Rate
INTO dbo.Employee -- Create a new table here and load query data
FROM [Person].[Person] P
INNER JOIN [HumanResources].[Employee] E
ON E.BusinessEntityID = P.BusinessEntityID
CROSS APPLY (
SELECT TOP 1 DepartmentID
FROM [HumanResources].[EmployeeDepartmentHistory] DH
WHERE DH.BusinessEntityID = E.BusinessEntityID
ORDER BY StartDate DESC) EDH
INNER JOIN [HumanResources].[Department] D
ON D.DepartmentID = EDH.DepartmentID
INNER JOIN [HumanResources].[EmployeePayHistory] S
ON S.BusinessEntityID = P.BusinessEntityID
SELECT * FROM dbo.Employee -- 316
GO
1. COUNT() function returns the number of rows in a table or a group, and returns an INT (integer).
-- To get count of all reords in a table: select COUNT(*) from dbo.Employee -- 316 -- Within Group: get count of records having Gender = 'M': select COUNT(*) from dbo.Employee WHERE Gender = 'M' -- 228 -- Using DISTINCT with COUNT: select COUNT(FirstName) from dbo.Employee -- 316 select COUNT(DISTINCT FirstName) from dbo.Employee -- 224 select COUNT(LastName) from dbo.Employee -- 316 select COUNT(DISTINCT LastName) from dbo.Employee -- 270
–> Using COUNT() function with GROUP BY
-- Get count of Employees in every Department: select DeptName, COUNT(*) as EmpCount from dbo.Employee GROUP BY DeptName
2. MIN(), MAX() and AVG() functions returns the Minimum, Maximum and Average values from a table or a group.
-- Check the Minimum, Maximum and Average salaries of all Employes: SELECT MIN(Salary) as minSal, MAX(Salary) as maxSal, AVG(Salary) as avgSal FROM dbo.Employee
–> Using MIN(), MAX(), AVG() functions with GROUP BY
-- Check Department wise Minimum, Maximum and Average salaries: SELECT DepartmentName, MIN(Salary) as minSal, MAX(Salary) as maxSal, AVG(Salary) as avgSal FROM dbo.Employee GROUP BY DepartmentName
3. SUM() function returns the Sum of all values from a table or a group.
-- Check the budget of a company to pay their Employee's salary: select SUM(Salary) as TotalSalary from dbo.Employee
–> Using SUM() function with GROUP BY
-- Check Department wise budget of salary: select DepartmentName, SUM(Salary) as TotalSalary from dbo.Employee GROUP BY DepartmentName
4. Using all Aggregate function together to get all information in a single query:
SELECT COUNT(*) as EmpCount, MIN(Salary) as minSal, MAX(Salary) as maxSal, AVG(Salary) as avgSal, SUM(Salary) as TotalSalary FROM dbo.Employee -- GROUP BY example with Aggregate functions:</strong> SELECT DepartmentName, COUNT(*) as EmpCount, MIN(Salary) as minSal, MAX(Salary) as maxSal, AVG(Salary) as avgSal, SUM(Salary) as TotalSalary FROM dbo.Employee GROUP BY DepartmentName
–> More Aggregate Functions in SQL Server are: COUNT_BIG, CHECKSUM_AGG, STDEV, STDEVP, GROUPING, GROUPING_ID, VAR, VARP. You can check them here: https://docs.microsoft.com/en-us/sql/t-sql/functions/aggregate-functions-transact-sql
SQL Basics – Data Types in SQL Server (Video)
–> Here is the notepad file I used in the above video for your reference:
– Numerics:
bit – 1, 0, NULL
tinyInt – 1 byte 0 to 255
smallInt – 2 bytes -32,767 to +32,767
int – 4 bytes -2,147,483,647 to +2,147,483,647
bigint – 8 bytes -9,223,372,036,854,775,808 to +9,223,372,036,854,775,808
decimal(p,s)/numeric(p,s) -10^38 +1 to +10^38 +1
smallMoney -214,748.3648 to +214,748.3648
money -922,337,203,685,477.5808 to +922,337,203,685,477.5808
– Flaoting point
float & real
– Date & Time (Temporal)
date – YYYY-MM-DD
time – hh:mm:ss[.nnnnnnn]
smallDatetime – YYYY-MM-DD hh:mm:ss
datetime – YYYY-MM-DD hh:mm:ss[.nnn]
datetime2 – YYYY-MM-DD hh:mm:ss[.nnnnnnn]
– Character Strings
char – 1 to 8000 chars, 8000 btyes
nchar – 1 to 4000 chars, 8000 btyes
varchar – 1 to 8000 chars, 8000 btyes
nvarchar – 1 to 4000 chars, 8000 btyes
[n]varchar(max) – 2GB
here prefix “n” is unicode to store international languages and take double space.
– binary Strings
binary – 1 to 8000 bytes
varbinary – 1 to 8000 bytes
varbinary(max) – 2GB
image – 2GB
– Other Datatypes
cursor
timestamp
xml
uniqueIdentifier – GUID
Spatial Types (geography, geometry)
sql_variant
… etc
SQL Basics – Difference between WHERE, GROUP BY and HAVING clause
All these three Clauses are a part/extensions of a SQL Query, are used to Filter, Group & re-Filter rows returned by a Query respectively, and are optional. Being Optional they play very crucial role while Querying a database.
–> Here is the logical sequence of execution of these clauses:
1. WHERE clause specifies search conditions for the rows returned by the Query and limits rows to a meaningful set.
2. GROUP BY clause works on the rows returned by the previous step #1. This clause summaries identical rows into a single/distinct group and returns a single row with the summary for each group, by using appropriate Aggregate function in the SELECT list, like COUNT(), SUM(), MIN(), MAX(), AVG(), etc.
3. HAVING clause works as a Filter on top of the Grouped rows returned by the previous step #2. This clause cannot be replaced by a WHERE clause and vice-versa.
As these clauses are optional thus a minimal SQL Query looks like this:
SELECT * FROM [Sales].[SalesOrderHeader]
This Query returns around 32k (thousand) rows form SalesOrderHeader table. Thus, if somebody wants to do some analysis on this big row-set it would be very difficult and time consuming for him.
–> Use Case: Let’s say a Sales department wants to get a list of such Customers who bought more number of items last year, so that they can sell more some stuff to them this year. How they will go ahead?
1. Using WHERE clause: First of all they will need to apply filter on above ~32k rows and get list of Orders that were made last year (i.e. in 2014) to limit the row-set, like:
SELECT * FROM [Sales].[SalesOrderHeader] WHERE OrderDate >= '2014-01-01 00:00:00.000' AND OrderDate < '2015-01-01 00:00:00.000'
This Query still gives ~12k records and its still difficult to identify such Customers who have more orders.
2. Using GROUP BY clause: Here we need to group the Customers with their number of Orders, like:
SELECT CustomerID, COUNT(*) AS OrderNos FROM [Sales].[SalesOrderHeader] WHERE OrderDate >= '2014-01-01 00:00:00.000' AND OrderDate < '2015-01-01 00:00:00.000' GROUP BY CustomerID

This query still returns ~10k records, and I’ve go through the entire list of records to identify such records. Is there any way where I can still filter out the unwanted records with lesser count?
3. USING HAVING clause: This will works on top of GROUP BY clause to filter the grouped records onCOUNT(*) AS OrderNos column values (like a WHERE clause), like:
SELECT CustomerID, COUNT(*) AS OrderNos FROM [Sales].[SalesOrderHeader] WHERE OrderDate >= '2014-01-01 00:00:00.000' AND OrderDate < '2015-01-01 00:00:00.000' GROUP BY CustomerID HAVING COUNT(*) > 10

Thus, by using all these these clauses we can reduce and narrow down the row-set to do some quick analysis.
Check this video tutorial on WHERE clause and difference with GROUP BY & HAVING clause.
SQL Basics – What are Row Constructors?
Constructors, as the name suggests means to create an instance of an Object in any Object Oriented Programming language.
Here in SQL Server or T-SQL, ROW Constructor or Table Value Constructor means to create a row set by using the VALUES() clause. This allows multiple rows of data to be specified in a single DML statement. And this VALUES() clause can be used with the SELECT, INSERT and MERGE statements.
In the examples below we will see how they can be used and are helpful at times:
Usage #1. You can create a simple set of rows with a SELECT FROM statement:
SELECT * FROM ( VALUES (1, 'cust 1', '(111) 111-1111', 'address 1'), (2, 'cust 2', '(222) 222-2222', 'address 2'), (3, 'cust 3', '(333) 333-3333', 'address 3'), (4, 'cust 4', '(444) 444-4444', 'address 4'), (5, 'cust 5', '(555) 555-5555', 'address 5') ) AS C (CustID, CustName, phone, addr);
Usage #2. You can use it with INSERT statement while inserting rows in a table:
CREATE TABLE dbo.Customer ( CustID INT, CustName VARCHAR(100), phone VARCHAR(20), addr VARCHAR(500) ) INSERT INTO dbo.Customer (CustID, CustName, phone, addr) VALUES (1, 'cust 1', '(111) 111-1111', 'address 1'), (2, 'cust 2', '(222) 222-2222', 'address 2'), (3, 'cust 3', '(333) 333-3333', 'address 3'), (4, 'cust 4', '(444) 444-4444', 'address 4'), (5, 'cust 5', '(555) 555-5555', 'address 5');
Usage #3. You can create mixed row-sets from manually entered values and from other tables:
SELECT * FROM ( VALUES (1, 'cust 1', '(111) 111-1111', 'address 1'), (2, 'cust 2', '(222) 222-2222', 'address 2'), (3, 'cust 3', '(333) 333-3333', 'address 3'), (4, 'cust 4', '(444) 444-4444', 'address 4'), ((SELECT CustID FROM dbo.Customer WHERE CustID IN (5)), (SELECT CustName FROM dbo.Customer WHERE CustID IN (5)), (SELECT phone FROM dbo.Customer WHERE CustID IN (5)), (SELECT addr FROM dbo.Customer WHERE CustID IN (5)) ) ) AS C (CustID, CustName, phone, addr);
Usage #4. You can use them with JOINS, without need to create #Temp-Table or Table-Variable to store temporary data:
SELECT C.CustName, O.ProductName FROM dbo.Customer C LEFT JOIN ( VALUES (101, 1, 'Apple'), (102, 3, 'Orange'), (103, 5, 'Banana') ) AS O (OrderID ,CustID, ProductName) ON O.CustID = C.CustID
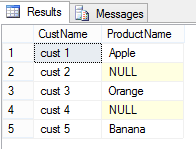
Usage #5. You can use them with MERGE statement, again without need to create #Temp-Table or Table-Variable to store temporary data:
MERGE INTO dbo.Customer as Target USING ( VALUES (5, 'cust 5', '(555) 555-5555', 'address 5 updated'), (6, 'cust 6', '(666) 666-6666', 'address 6') ) AS Source (CustID, CustName, phone, addr) ON Target.CustID = Source.CustID WHEN MATCHED THEN UPDATE SET Target.CustName = Source.CustName, Target.phone = Source.phone, Target.addr = Source.addr WHEN NOT MATCHED BY Target THEN INSERT ( CustID, CustName, phone, addr ) VALUES ( Source.CustID, Source.CustName, Source.phone, Source.addr ); select * from dbo.Customer;

Thus, Row Constructors or Table Value Constructors are very handy when dealing with fixed set of row sets used for temporary purpose, without need of creating and storing them in #Temp-Tables or Table-Variables.
–> Final Cleanup
DROP TABLE dbo.Customer
SQL DBA – Move user Database (.mdf & .ldf files) to another drive
Here in this post we will see how to move user created Database to an another drive from the default drive.
–> The first 2 ways I’ve discussed in my other blog posts, please check the links below:
1. Detach & Attach task, video
2. Backup & Restore task, link, video
3. By using ALTER command, Syntax below:
ALTER DATABASE SET OFFLINE;
GO— Manually move the file(s) to the new location.
ALTER DATABASE Database name
MODIFY FILE (
NAME = ‘Database name’,
FILENAME = ‘New Location’
)
GOALTER DATABASE Database name SET ONLINE;
GO
–> Script used in above video:
Step #1. Create a new Database in SSMS with name “ManDB”.
Step #2. Check the current location of database:
select * from ManDB.sys.database_files --ManDB D:\Program Files (x86)\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\DATA\ManDB.mdf --ManDB_log D:\Program Files (x86)\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\DATA\ManDB_log.ldf
Step #3. Take the database offline, so that we can move files from one drive to another:
ALTER DATABASE ManDB SET OFFLINE; GO
Step #4. Move the file(s) to the new location manually.
Step #5. Change the system catalog settings:
ALTER DATABASE ManDB MODIFY FILE ( NAME = 'ManDB', FILENAME = 'E:\SQLDBs\ManDB.mdf' ) GO ALTER DATABASE ManDB MODIFY FILE ( NAME = 'ManDB_log', FILENAME = 'E:\SQLDBs\ManDB_log.ldf' ) GO
Step #6. Take the database back online:
ALTER DATABASE ManDB SET ONLINE; GO
Step #7. Check the new location:
select * from ManDB.sys.database_files --ManDB E:\SQLDBs\ManDB.mdf --ManDB_log E:\SQLDBs\ManDB_log.ldf


![]()
Current Visitors

StatCounter …since April 2012

 Leisure blog: Creek & Trails
Leisure blog: Creek & Trails
- NMDC Hyderabad Marathon – My first 42k FM, cramps, training and fuelling
- Singapore (Part 2) – 6 days itinerary, sightseeing & attractions
- Singapore (Part 1) – Tickets, Visa, Hotel, Forex Card/Cash, Metro/Bus cards
- I got full refund of my flight tickets during COVID lockdown (AirIndia via MakeMyTrip)
- YouTube – Your Google Ads account was cancelled due to no spend
- YouTube latest update on its YPP (YouTube Partner Program) which may affect your channel
- Starting your own blog !!!
- How to file ITR (Income Tax Return) online AY 2017-18 (for simple salaried)
- Scam – Become a kin/hier and earn a fortune – via LinkedIn and Email
- Places to visit in and around Vizag (aka Visakhapatnam)
