Archive
SQL DBA – Change RECOVERY mode & SHRINK all databases at once in SQL Server
There are times when you are left with no or very less space in you SQL Server VM disks, and the main cause of this is not only the lot amount of data coming in but the heavy processing your database Server is doing, and thus filling up the entire log space.
SQL Server provides you some effective commands to shrink the database files which got inflated due to heavy processing and to make room for new data.
ALTER DATABASE <db_name> SET RECOVERY SIMPLE; DBCC SHRINKFILE (N'<log_file_name>' , 100);
But this works with one database at a time, so what if you have lots of databases? It will be tiring and time consuming to visit each DB, get the database file names and apply the shrink command. Its even slow to do the same via SSMS GUI.
Note: Do not change the recovery mode in a PROD environment unless it is really required.
With the below T-SQL statements you can generate scripts for all the databases and can run to change all database settings at once:
-- Generate SQL Script to change Recovery mode to 'SIMPLE' for all DBs: SELECT 'ALTER DATABASE [' + name + '] SET RECOVERY SIMPLE;' as SimpleRecovery4AllDBs FROM sys.databases WHERE recovery_model_desc <> 'SIMPLE' -- Generate SQL Script to Shrink log files of all DBs: SELECT 'USE ' + DB_Name(database_id) + '; DBCC SHRINKFILE (N''' + name + ''' , 100);' as ShrinkAllDBs FROM sys.master_files WHERE database_id > 4 and [type] = 1
Please let me know if you have any other way to do the same (and in more effective way) !!!
Clustered Index do “NOT” guarantee Physically Ordering or Sorting of Rows
Myth: Lot of SQL Developers I’ve worked with and interviewed have this misconception, that Clustered Indexes are Physically Sorted and Non-Clustered Index are Logically Sorted. When I ask them reasons, all come with their own different versions.
I discussed about this in my previous post long time back, where I mentioned as per the MSDN that “Clustered Indexes do not guarantee Physical Ordering of rows in a Table”. And today in this post I’m going to provide an example to prove it.
Clustered Index is the table itself as its Leaf-Nodes contains the Data-Pages of the table. The Data-Pages are nothing but Doubly Linked-List Data-Structures linked to their leading & preceding Data-Pages. The Data-Pages and rows in them are Ordered by the Clustering Key. Thus there can be only one Clustered Index on a table.
When a new Clustered Index is created on a table, it reorganizes the table’s Data-Pages Physically so that the rows are Logically sorted. But when a tables goes through updates, like INSERT/UPDATE/DELETE operations then the index gets fragmented and thus the Physical Ordering of Data-Pages gets lost. But still the Data-Pages of the Clustered Index or the Table are chained together by Doubly Linked-List in Logical Order.
We will see this behavior in the following example:
USE AdventureWorks2012
GO
CREATE TABLE test (i INT PRIMARY KEY not null, j VARCHAR(2000))
INSERT INTO test (i,j)
SELECT 1, REPLICATE('a',100) UNION ALL
SELECT 2, REPLICATE('a',100) UNION ALL
SELECT 3, REPLICATE('a',100) UNION ALL
SELECT 5, REPLICATE('a',100) UNION ALL
SELECT 6, REPLICATE('a',100)
SELECT * FROM test
DBCC IND(AdventureWorks2012, 'test', -1);
DBCC TRACEON(3604);
DBCC PAGE (AdventureWorks2012, 1, 22517, 1);
As you can see above we inserted 5 records in a table having PK as Clustering Key with following values: 1,2,3,5,6. We skipped the value 4.
–> Here is the Output of DBCC PAGE command execute in the end:
The DBCC PAGE provides very descriptive Output, but here I’ve just extracted the useful information we need.
OFFSET TABLE: Row - Offset 4 (0x4) - 556 (0x22c) --> 1=6 3 (0x3) - 441 (0x1b9) --> 1=5 2 (0x2) - 326 (0x146) --> 1=3 1 (0x1) - 211 (0xd3) --> 1=2 0 (0x0) - 96 (0x60) --> 1=1
It show the 5 rows with their memory allocated address in both decimal and hexadecimal formats, which is contiguous. Thus all the rows are Physically Ordered.
Now, let’s insert the value “4” that we skipped initially:
INSERT INTO test (i,j)
SELECT 4, REPLICATE('a',100)
SELECT * FROM test
DBCC IND(AdventureWorks2012, 'test', -1);
DBCC TRACEON(3604);
DBCC PAGE (AdventureWorks2012, 1, 22517, 1);
–> Here is the new Output of DBCC PAGE command execute in the end:
OFFSET TABLE: Row - Offset 5 (0x5) - 556 (0x22c) --> 1=6 4 (0x4) - 441 (0x1b9) --> 1=5 3 (0x3) - 671 (0x29f) --> 1=4 <-- new row added here 2 (0x2) - 326 (0x146) --> 1=3 1 (0x1) - 211 (0xd3) --> 1=2 0 (0x0) - 96 (0x60) --> 1=1
As you can see very clearly in the output above that the memory allocation address for the new row with PK value = “4” is 671, which is not in between and greater than the address of the last row i.e. 556. The memory address of the last 2 rows is unchanged (441 & 556) and the new row is not accommodated in between as per the sort order but at the end. There is no Physical Ordering and the new row is Logically Chained with other rows and thus is Logically and Ordered, similar to the image below:
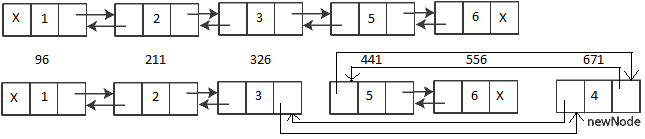
Myth Busted: Hope the above exercise clears that Clustered Indexes do not guarantee the Physical Ordering of Rows & Data Pages.
-- Final Cleanup DROP TABLE test
SET STATISTICS IO and TIME – What are Logical, Physical and Read-Ahead Reads?
In my previous post [link] I talked about SET STATISTICS IO and Scan Count.
Here in this post I will go ahead and talk about Page Reads, i.e Logical Reads and Physical Reads.
–> Type of Reads and their meaning:
– Logical Reads: are the number of 8k Pages read from the Data Cache. These Pages are placed in Data Cache by Physical Reads or Read-Ahead Reads.
– Physical Reads: are the Number of 8k Pages read from the Disk if they are not in Data Cache. Once in Data Cache they (Pages) are read by Logical Reads and Physical Reads do not (or minimally) happen for same set of queries.
– Read-Ahead Reads: are the number of 8k Pages pre-read from the Disk and placed into the Data Cache. These are a kind of advance Physical Reads, as they bring the Pages in advance to the Data Cache where the need for Data/Index pages in anticipated by the query.
–> Let’s go by some T-SQL Code examples to make it more simple to understand:
USE [AdventureWorks2012] GO -- We will crate a new table here and populate records from AdventureWorks's Person.Person table: SELECT BusinessEntityID, Title, FirstName, MiddleName, LastName, Suffix, EmailPromotion, ModifiedDate INTO dbo.Person FROM [Person].[Person] GO -- Let's Clear up the Data Cache or memory-buffer: DBCC FREEPROCCACHE DBCC DROPCLEANBUFFERS GO -- Run the following block of T-SQL statements: SET STATISTICS IO ON SET STATISTICS TIME ON SELECT * FROM dbo.Person SELECT * FROM dbo.Person SET STATISTICS IO OFF SET STATISTICS TIME OFF GO
Output Message: (19972 row(s) affected) Table 'Person'. Scan count 1, logical reads 148, physical reads 0, read-ahead reads 148, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 31 ms, elapsed time = 297 ms. (19972 row(s) affected) Table 'Person'. Scan count 1, logical reads 148, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 16 ms, elapsed time = 186ms.
The Output Message above shows different number of Reads for both the queries when ran twice.
– On first execution of the Query, the Data Cache was empty so the query had to do a Physical Read. But as the optimizer already knows that all records needs to be fetched, so by the time query plan is created the DB Engine pre-fetches all records into memory by doing Read-Ahead Read operation. Thus, here we can see zero Physical Reads and 148 Read-Ahead Reads. After records comes into Data Cache, the DB Engine pulls the Records from Logical Reads operation, which is again 148.
– On second execution of the Query, the Data Cache is already populated with the Data Pages so there is no need to do Physical Reads or Read-Ahead Reads. Thus, here we can see zero Physical & Read-Ahead Reads. As the records are already in Data Cache, the DB Engine pulls the Records from Logical Reads operation, which is same as before 148.
Note: You can also see the performance gain by Data Caching, as the CPU Time has gone down to 16ms from 31ms and Elapsed Time to 186ms from 297ms.
–> At our Database end we can check how many Pages are in the Disk for the Table [dbo].[Person].
Running below DBCC IND statement will pull number of records equal to number of Pages it Cached above, i.e. 148:
DBCC IND('AdventureWorks2012','Person',-1)
GO
The above statement pulls up 149 records, 1st record is the IAM Page and rest 148 are the Data Pages of the Table that were Cached into the buffer pool.
–> We can also check at the Data-Cache end how many 8k Pages are in the Data-Cache, before-Caching and after-Caching:
-- Let's Clear up the Data Cache again: DBCC FREEPROCCACHE DBCC DROPCLEANBUFFERS GO -- Run this DMV Query, this time it will run on Cold Cache, and will return information from the pre-Cache'd data: ;WITH s_obj as ( SELECT OBJECT_NAME(OBJECT_ID) AS name, index_id ,allocation_unit_id, OBJECT_ID FROM sys.allocation_units AS au INNER JOIN sys.partitions AS p ON au.container_id = p.hobt_id AND (au.type = 1 OR au.type = 3) UNION ALL SELECT OBJECT_NAME(OBJECT_ID) AS name, index_id, allocation_unit_id, OBJECT_ID FROM sys.allocation_units AS au INNER JOIN sys.partitions AS p ON au.container_id = p.partition_id AND au.type = 2 ), obj as ( SELECT s_obj.name, s_obj.index_id, s_obj.allocation_unit_id, s_obj.OBJECT_ID, i.name IndexName, i.type_desc IndexTypeDesc FROM s_obj INNER JOIN sys.indexes i ON i.index_id = s_obj.index_id AND i.OBJECT_ID = s_obj.OBJECT_ID ) SELECT COUNT(*) AS cached_pages_count, obj.name AS BaseTableName, IndexName, IndexTypeDesc FROM sys.dm_os_buffer_descriptors AS bd INNER JOIN obj ON bd.allocation_unit_id = obj.allocation_unit_id INNER JOIN sys.tables t ON t.object_id = obj.OBJECT_ID WHERE database_id = DB_ID() AND obj.name = 'Person' AND schema_name(t.schema_id) = 'dbo' GROUP BY obj.name, index_id, IndexName, IndexTypeDesc ORDER BY cached_pages_count DESC; -- Run following Query, this will populate the Data Cache: SELECT * FROM dbo.Person -- Now run the previous DMV Query again, this time it will run on Cache'd Data and will return information of the Cache'd Pages:
Query Output: -> First DMV Query Run: cached_pages_count BaseTableName IndexName IndexTypeDesc 2 Person NULL HEAP -> Second DMV Query Run: cached_pages_count BaseTableName IndexName IndexTypeDesc 150 Person NULL HEAP
So, by checking the above Output you can clearly see that only 2 Pages were there before-Caching.
And after executing the Query on table [dbo].[Person] the Data Pages got Cache’d into the buffer pool. And on running the same DMV query again you get the number of Cache’d Pages in the Data Cache, i.e same 148 Pages (150-2).
-- Final Cleanup DROP TABLE dbo.Person GO
>> Check & Subscribe my [YouTube videos] on SQL Server.
ISNULL vs COALESCE – expressions/functions in SQL Server
ISNULL & COALESCE with some common features makes them equivalent, but some features makes them work and behave differently, shown below.
– Similarity
Both can be use to build/create a CSV list as shown below:
USE [AdventureWorks] GO DECLARE @csv VARCHAR(2000) SELECT @csv = ISNULL(@csv + ', ', '') + FirstName FROM Person.Contact WHERE ContactID <= 10 ORDER BY FirstName select @csv set @csv=NULL SELECT @csv = COALESCE(@csv + ', ', '') + FirstName FROM Person.Contact WHERE ContactID <= 10 ORDER BY FirstName select @csv
Both will give the same output:
Carla, Catherine, Frances, Gustavo, Humberto, Jay, Kim, Margaret, Pilar, Ronald
– Difference #1
ISNULL accepts only 2 parameters. The first parameter is checked for NULL value, if it is NULL then the second parameter is returned, otherwise it returns first parameter.
COALESCE accepts two or more parameters. One can apply 2 or as many parameters, but it returns only the first non NULL parameter, example below.
DECLARE @str1 VARCHAR(10), @str2 VARCHAR(10) -- ISNULL() takes only 2 arguments SELECT ISNULL(@str1, 'manoj') AS 'IS_NULL' -- manoj -- COALESCE takes multiple arguments and returns first non-NULL argument SELECT COALESCE(@str1, @str2, 'manoj') AS 'COALESCE' -- manoj -- ISNULL() equivalent of COALESCE, by nesting of ISNULL() SELECT ISNULL(@str1, ISNULL(@str2, 'manoj')) AS 'IS_NULL eqv' -- manoj
– Difference #2
ISNULL does not implicitly converts the datatype if both parameters datatype are different.
On the other side COALESCE implicitly converts the parameters datatype in order of higher precedence.
-- ISNULL Does not do Implicit conversion select ISNULL(10, getdate()) as 'IS_NULL' -- Errors out
Error Message: Msg 257, Level 16, State 3, Line 1 Implicit conversion from data type datetime to int is not allowed. Use the CONVERT function to run this query.
-- COALESCE Does Implicit conversion and gets converted to higher precedence datatype.
select COALESCE(10, getdate()) as 'COALESCE' -- 1900-01-11 00:00:00.000, outputs 10 but convert it to datetime [datetime > int]
select COALESCE(getdate(),10) as 'COALESCE' -- {Current date} 2010-12-23 23:36:31.110
select COALESCE(10, 'Manoj') as 'COALESCE' -- 10 [int > varchar]
select COALESCE('Manoj',10) as 'COALESCE' -- Errors out, it does an implicit conversion, but cannot change 'Manoj' to Integer.
Error Message: Msg 245, Level 16, State 1, Line 1 Conversion failed when converting the varchar value 'Manoj' to data type int.
– Difference #3
Similar to above point ISNULL always returns the value with datatype of first parameter.
Contrary to this, COALESCE returns the datatype value according to the precedence and datatype compatibility.
DECLARE @str VARCHAR(5) SET @str = NULL -- ISNULL returns truncated value after its fixed size, here 5 SELECT ISNULL(@str, 'Half Full') AS 'IS_NULL' -- Half -- COALESCE returns full length value, returns full 12 char string SELECT COALESCE(@str, 'Half Full') AS 'COALESCE' -- Half Full
– Difference #4
According to MS BOL, ISNULL and COALESCE though equivalent, can behave differently. An expression involving ISNULL with non-null parameters is considered to be NOT NULL, while expressions involving COALESCE with non-null parameters is considered to be NULL. Thus to index expressions involving COALESCE with non-null parameters, the computed column can be persisted using the PERSISTED column attribute.
-- ISNULL() is allowed in computed columns with Primary Key CREATE TABLE T1 ( col1 INT, col2 AS ISNULL(col1, 1) PRIMARY KEY) -- COALESCE() is not allowed in non-persisted computed columns with Primary Key CREATE TABLE T2 ( col1 INT, col2 AS COALESCE(col1, 1) PRIMARY KEY)
Error Message: Msg 1711, Level 16, State 1, Line 1 Cannot define PRIMARY KEY constraint on column 'col2' in table 'T2'. The computed column has to be persisted and not nullable. Msg 1750, Level 16, State 0, Line 1 Could not create constraint. See previous errors.
-- COALESCE() is only allowed as persisted computed columns with Primary Key CREATE TABLE T2 ( col1 INT, col2 AS COALESCE(col1, 1) PERSISTED PRIMARY KEY) -- Clean up DROP TABLE T1 DROP TABLE T2
MSDN BOL links:
ISNULL: http://msdn.microsoft.com/en-us/library/ms184325.aspx
COALESCE: http://msdn.microsoft.com/en-us/library/ms190349.aspx
http://code.msdn.microsoft.com/SQLExamples/Wiki/View.aspx?title=ISNULL_COALESCE
SET ANSI_NULLS, QUOTED_IDENTIFIER, ANSI_PADDING – SQL Server
You have to create a Stored-Procedure and you need a template. You expand the Object Explorer go to Database -> Programmability -> “Stored Procedure” -> (right click) -> select “New Stored Procedure”.
A new editor opens up with lot of commented & flawless code. There you see some predefined statements.
Sometimes while working with Stored Procedures and other SQL Scripts a those few statements makes you confusing and clueless. Most of the time people remove them or just ignore them, but one should know why are they placed there. The 2 mains SET statements that are placed by default are described below with examples:
–// SET ANSI_NULLS (http://msdn.microsoft.com/en-us/library/ms188048.aspx)
Specifies ISO compliant behavior of the Equals (=) and Not Equal To (<>) comparison operators when they are used with null values.
Syntax: SET ANSI_NULLS { ON | OFF }
create table #tempTable (sn int, ename varchar(50)) insert into #tempTable select 1, 'Manoj' UNION ALL select 2, 'Pankaj' UNION ALL select 3, NULL UNION ALL select 4, 'Lokesh' UNION ALL select 5, 'Gopal' SET ANSI_NULLS ON select * from #tempTable where ename is NULL -- (1 row(s) affected)
sn ename
3 NULL
select * from #tempTable where ename = NULL -- (0 row(s) affected) select * from #tempTable where ename <> NULL -- (0 row(s) affected) SET ANSI_NULLS OFF select * from #tempTable where ename is NULL -- (1 row(s) affected) select * from #tempTable where ename = NULL -- (1 row(s) affected)
sn ename
3 NULL
select * from #tempTable where ename is not NULL -- (4 row(s) affected) select * from #tempTable where ename <> NULL -- (4 row(s) affected)
sn ename
1 Manoj
2 Pankaj
4 Lokesh
5 Gopal
drop table #tempTable
–// SET QUOTED_IDENTIFIER (http://msdn.microsoft.com/en-us/library/ms174393.aspx)
Causes SQL Server to follow the ISO rules regarding quotation mark delimiting identifiers and literal strings. Identifiers delimited by double quotation marks can be either Transact-SQL reserved keywords or can contain characters not generally allowed by the Transact-SQL syntax rules for identifiers.
When SET QUOTED_IDENTIFIER is ON, identifiers can be delimited by double quotation marks, and literals must be delimited by single quotation marks.
When SET QUOTED_IDENTIFIER is OFF, identifiers cannot be quoted and must follow all Transact-SQL rules for identifiers.
Syntax: SET QUOTED_IDENTIFIER { ON | OFF }
-- Example 1 SET QUOTED_IDENTIFIER ON create table "#tempTable" (sn int, ename varchar(50)) -- Command(s) completed successfully. SET QUOTED_IDENTIFIER OFF create table "#tempTable" (sn int, ename varchar(50)) -- Incorrect syntax near '#tempTable'. drop table #tempTable -- Example 2 SET QUOTED_IDENTIFIER ON select "'My Name is Manoj'" as Col1, "Let's play" as Col2 -- Invalid column name ''My Name is Manoj''. Invalid column name 'Let's play'. SET QUOTED_IDENTIFIER OFF select "'My Name is Manoj'" as Col1, "Let's play" as Col2 -- (1 row(s) affected)
Col1 Col2
'My Name is Manoj' Let's play
-- Example 3 SET QUOTED_IDENTIFIER ON select '''My Name is Manoj''' as Col1, 'Let''s play' as Col2 -- (1 row(s) affected)
Col1 Col2
'My Name is Manoj' Let's play
SET QUOTED_IDENTIFIER OFF select '''My Name is Manoj''' as Col1, 'Let''s play' as Col2 -- (1 row(s) affected)
Col1 Col2
'My Name is Manoj' Let's play
–// SET ANSI_PADDING (http://msdn.microsoft.com/en-us/library/ms187403.aspx)
Controls the way the column stores values shorter than the defined size of the column, and the way the column stores values that have trailing blanks in char, varchar, binary, and varbinary data.
Syntax: SET ANSI_PADDING { ON | OFF }
-- Example 1 SET ANSI_PADDING ON create table #tempTable1 (charcol char(20), varcharcol varchar(20)) insert into #tempTable1 select 'Manoj', 'Manoj' UNION ALL select 'Pandey', 'Pandey' select '['+charcol+']' as charcol, '['+varcharcol+']' as varcharcol from #tempTable1
charcol varcharcol
[Manoj ] [Manoj]
[Pandey ] [Pandey]
-- Example 2 SET ANSI_PADDING OFF create table #tempTable2 (charcol char(20), varcharcol varchar(20)) insert into #tempTable2 select 'Manoj', 'Manoj' UNION ALL select 'Pandey', 'Pandey' select '['+charcol+']' as charcol, '['+varcharcol+']' as varcharcol from #tempTable2
charcol varcharcol
[Manoj] [Manoj]
[Pandey] [Pandey]
drop table #tempTable1 drop table #tempTable2
Other SET statements MSDN BOL: http://msdn.microsoft.com/en-us/library/ms190356.aspx


![]()
Current Visitors

StatCounter …since April 2012

 Leisure blog: Creek & Trails
Leisure blog: Creek & Trails
- NMDC Hyderabad Marathon – My first 42k FM, cramps, training and fuelling
- Singapore (Part 2) – 6 days itinerary, sightseeing & attractions
- Singapore (Part 1) – Tickets, Visa, Hotel, Forex Card/Cash, Metro/Bus cards
- I got full refund of my flight tickets during COVID lockdown (AirIndia via MakeMyTrip)
- YouTube – Your Google Ads account was cancelled due to no spend
- YouTube latest update on its YPP (YouTube Partner Program) which may affect your channel
- Starting your own blog !!!
- How to file ITR (Income Tax Return) online AY 2017-18 (for simple salaried)
- Scam – Become a kin/hier and earn a fortune – via LinkedIn and Email
- Places to visit in and around Vizag (aka Visakhapatnam)
