Archive
New built-in function CONCAT_WS() in SQL Server 2017
In my previous posts I discussed new Functions introduced in SQL Server vNext (or 2018), like STRING_AGG(), TRIM(), TRANSLATE().
Here in this post I’ll discuss about one more new function i.e. CONCAT_WS(), here “_WS” means “With Separator”.
This is very similar to the existing CONCAT() function introduced back in SQL Server 2012, which concatenates a variable number of arguments or string values.
The difference is the new function CONCAT_WS() accepts a delimiter specified as the 1st argument, and thus there is no need to repeat the delimiter after very String value like in CONCAT() function.
Also the new CONCAT_WS() function takes care of NULL values and do not repeat the delimiter, which you can see in 2nd example below.
Syntax:
CONCAT_WS ( separator, argument1, argument1 [, argumentN]… )
–> Example #1:
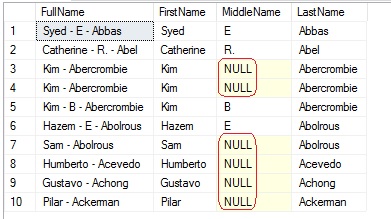
With CONCAT_WS() we will use the delimiter just once and it concatenates the names separated by ‘-‘, and do not repeat the hyphen where the middle name is NULL.
USE [AdventureWorks2014]
GO
SELECT TOP 10
CONCAT_WS(' - ', FirstName, MiddleName, LastName) as FullName,
FirstName, MiddleName, LastName
FROM [Person].[Person]
–> Example #2:
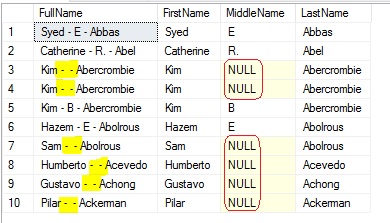
With CONCAT() the delimiter needs to be used after every argument, it concatenates the names separated by ‘-‘, do repeats the hyphen where the middle name is NULL.
SELECT TOP 10 CONCAT(FirstName, ' - ', MiddleName, ' - ', LastName) as FullName, FirstName, MiddleName, LastName FROM [Person].[Person]
New built-in function TRANSLATE() in SQL Server 2017
Microsoft looks very serious this time to move people from other databases to SQL Server. As with SQL Server 2016 & 2017 you can see lot of Built-in function added, which were present in other databases from long back, will ease database development in SQL Server.
One of this function is TRANSLATE() function, which can be used like a REPLACE() function, and would avoid using REPLACE() function multiple times in a query.
Syntax:
TRANSLATE ( inputString, characters, translations)
Note: characters and translations params should have same length.
–> Consider this example I’ve taken from MSDN:
SELECT TRANSLATE('2*[3+4]/{7-2}', '[]{}', '()()');
GO
Output:
| Input | Output |
| 2*[3+4]/{7-2} | 2*(3+4)/(7-2) |
–> If you had to do same with REPLACE() function then you would end up writing multiple & nested REPLACE() function, like:
SELECT
REPLACE(
REPLACE(
REPLACE(
REPLACE('2*[3+4]/{7-2}', '[', '('),
']', ')'),
'{', '('),
'}', ')');
GO
After working with this new feature it reminds me of IIF vs CASE statement. The IIF() function also works as a shortcut of CASE statement and cuts lot of clutter and gives you clean code.
Hope you find this small utility very handy while developing complex queries, will post more scenarios if I came across going forward, thanks !!!
New built-in function TRIM() in SQL Server 2017
If you are thinking the new TRIM() function in SQL Server 2017 is just a combination of LTRIM() & RTRIM() functions, then you are wrong :). It’s more than that and we will check it today !
– LTRIM() function is used to truncate all leading blanks, or white-spaces from the left side of the string.
– RTRIM() function is used to truncate all trailing blanks, or white-spaces from the right side of the string.
–> Now, with teh new TRIM() function you can do both, but more than that.
Usage #1: TRIM() function will truncate all leading & trailing blanks from a String:
SELECT
TRIM (' Manoj Pandey ') as col1,
LTRIM(RTRIM(' Manoj Pandey ')) as col2

Usage #2: Plus it can be used to remove specific characters from both sides of a String, like below:
SELECT TRIM ( 'm,y' FROM 'Manoj Pandey') as col1, TRIM ( 'ma,ey' FROM 'Manoj Pandey') as col2, TRIM ( 'm,a,e,y' FROM 'Manoj Pandey') as col3

Thus with the above query you can see that you can trim characters too, by providing leading & trailing characters, but should be in same sequence as your string is.
Also for Col2 & Col3 we have provided Trimming Characters in 2 different ways, but got the same output.
–> Note: I just mentioned above that the leading & trailing characters should be in same sequence. If you provide in different sequence like below you won’t get desired results.
SELECT 'Manoj Pandey' as st, TRIM ( 'a,n' FROM 'Manoj Pandey') as Col1, TRIM ( 'm,e' FROM 'Manoj Pandey') as Col2, TRIM ( 'm,o,y,e' FROM 'Manoj Pandey') as Col3

Like for Col3 you cannot get rid of middle characters (like ‘o’ and ‘n’) until and unless they become leading or trailing characters.
New built-in function STRING_AGG() with option “WITHIN GROUP” – SQL Server 2017
In one of my [previous post] I discussed about a new function STRING_SPLIT() introduced in SQL Server 2016, which splits a Sentence or CSV String to multiple values or rows.
Now with the latest CTP 1.x version of SQL Server vNext (I’m calling it “SQL Server 2017”) a new function is introduced to just do its reverse, i.e. Concatenate string values or expressions separated by any character.
The STRING_AGG() aggregate function takes all expressions from rows and concatenates them into a single string in a single row.
It implicitly converts all expressions to String type and then concatenates with the separator defined.
–> In the example below I’ll populate a table with States and Cities in separate rows, and then try to Concatenate Cities belonging to same States:
USE tempdb GO CREATE TABLE #tempCityState ( [State] VARCHAR(5), [Cities] VARCHAR(50) ) GO INSERT INTO #tempCityState SELECT 'CA', 'Hanford' UNION ALL SELECT 'CA', 'Fremont' UNION ALL SELECT 'CA', 'Los Anggeles' UNION ALL SELECT 'CO', 'Denver' UNION ALL SELECT 'CO', 'Aspen' UNION ALL SELECT 'CO', 'Vail' UNION ALL SELECT 'CO', 'Teluride' UNION ALL SELECT 'WA', 'Seattle' UNION ALL SELECT 'WA', 'Redmond' UNION ALL SELECT 'WA', 'Bellvue' GO SELECT * FROM #tempCityState
State Cities
CA Hanford
CA Fremont
CA Los Anggeles
CO Denver
CO Aspen
CO Vail
CO Teluride
WA Seattle
WA Redmond
WA Bellvue
–> To comma separate values under a single row you just need to apply the STRING_AGG() function:
SELECT STRING_AGG(Cities, ', ') as AllCities FROM #tempCityState -- Use "WITHIN GROUP (ORDER BY ...)" clause to concatenate them in an Order: SELECT STRING_AGG(Cities, ', ') WITHIN GROUP (ORDER BY Cities) as AllCitiesSorted FROM #tempCityState

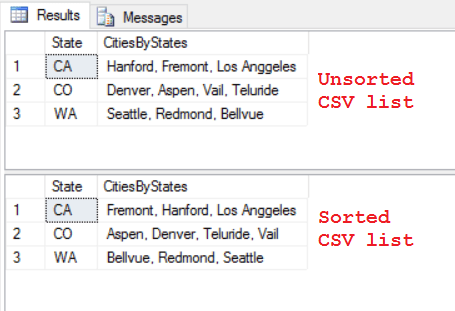
–> Now to Concatenate them by States, you just need to group them by the State, like any other aggregate function:
SELECT State, STRING_AGG(Cities, ', ') as CitiesByStates FROM #tempCityState GROUP BY State -- Use "WITHIN GROUP (ORDER BY ...)" clause to concatenate them in an Order: State, STRING_AGG(Cities, ', ') WITHIN GROUP (ORDER BY Cities) as CitiesByStatesSorted FROM #tempCityState GROUP BY State
You can check more about STRING_AGG() on MSDN.
New in-built Table-Valued Function STRING_SPLIT() in SQL Server 2016 – to split strings
Till now it was bit tricky to split a Sentence or CSV String to multiple values or rows, and we used different logic to do the same.
In my [previous post] I blogged similar logic to Split a String and Combine back by using some XML syntax.
In SQL Server 2016 this has been made simpler by using a new function STRING_SPLIT(), let’s see this with a simple example:
SELECT * FROM STRING_SPLIT('My name is Manoj Pandey', ' ')
This will split all the words in the sentence separated by a whitespace in different rows:

Here is the syntax for the same:
STRING_SPLIT ( string , separator )
Please note: that the separator should be a single character expression, so this should not be an empty string, like:
SELECT * FROM STRING_SPLIT('My name is Manoj Pandey', '')
Will result into an error:
Msg 214, Level 16, State 11, Line 3
Procedure expects parameter ‘separator’ of type ‘nchar(1)/nvarchar(1)’.
–> Let’s check one more example:
We have a comma separated Cities list for each State as a row in a table:
CREATE TABLE #tempCityState ( [State] VARCHAR(5), [Cities] VARCHAR(50) ) INSERT INTO #tempCityState SELECT 'AK', 'Nashville,Wynne' UNION ALL SELECT 'CA', 'Fremont,Hanford,Los Anggeles' UNION ALL SELECT 'CO', 'Aspen,Denver,Teluride,Vail'
Now, lets just use the simple function STRING_SPLIT() with CROSS APPLY operator, like:
SELECT [State], value FROM #tempCityState CROSS APPLY STRING_SPLIT([Cities], ',')
Will give you following output:

–> And if I compare the performance of this function with the earlier approach I mentioned in my [previous post]:
Run both the queries by enabling Actual Execution plan (Ctrl + M):
SELECT [State], value
FROM #tempCityState
CROSS APPLY STRING_SPLIT([Cities], ',')
SELECT A.[State], Split.a.value('.', 'VARCHAR(100)') AS City
FROM (SELECT [State], CAST ('<M>' + REPLACE([Cities], ',', '</M><M>') + '</M>' AS XML) AS String
FROM #tempCityState) AS A
CROSS APPLY String.nodes ('/M') AS Split(a)
ORDER BY 1,2
I can see that the STRING_SPLIT() gives me better performance compared to the other:



![]()
Current Visitors

StatCounter …since April 2012

 Leisure blog: Creek & Trails
Leisure blog: Creek & Trails
- NMDC Hyderabad Marathon – My first 42k FM, cramps, training and fuelling
- Singapore (Part 2) – 6 days itinerary, sightseeing & attractions
- Singapore (Part 1) – Tickets, Visa, Hotel, Forex Card/Cash, Metro/Bus cards
- I got full refund of my flight tickets during COVID lockdown (AirIndia via MakeMyTrip)
- YouTube – Your Google Ads account was cancelled due to no spend
- YouTube latest update on its YPP (YouTube Partner Program) which may affect your channel
- Starting your own blog !!!
- How to file ITR (Income Tax Return) online AY 2017-18 (for simple salaried)
- Scam – Become a kin/hier and earn a fortune – via LinkedIn and Email
- Places to visit in and around Vizag (aka Visakhapatnam)
