Archive
SQL Myth | Primary Key (PK) always creates Clustered Index
… and this a default nature, which can be overrided to create a PK with a Non-Clustered Index instead of a Clustered one.
– What happens when a Primary Key is created on a table?
– If I have a PK on a table will the table be a Heap or not?
– Can I create a PK with a Non-Clustered Index? (this is a big hint)
While Interviewing candidates I’ve confronted them with these type of question, and very few were able to answer these correctly.
–> So, here we will see the default behavior of Primary Keys and how we can override it:
–> Having the “PRIMARY KEY” option inline with the column name: While creating a new table when you specify a “PRIMARY KEY” option inline with the Key Column, by-default it creates a Clustered Index on that table with a PK Constraint on that column.
USE [tempdb] GO CREATE TABLE dbo.Employee ( EmpID INT NOT NULL PRIMARY KEY, -- here EmpLogInID VARCHAR(255) NULL, EmpFirstName VARCHAR(255) NOT NULL, EmpLastName VARCHAR(255) NOT NULL, Gender BIT NOT NULL, JobTitle VARCHAR(255) NULL, BOD DATETIME NULL, DOJ DATETIME NULL, DeptID INT NOT NULL ) GO sp_help 'dbo.Employee' GO

The above image shows:
– a Unique Clustered Index created on the [EmpID] column with a name automatically suggested by the DB-engine, and
– a PK Constraint created on the same column.
–> Overriding this behavior by having a “CONSTRAINT” option: Here we will not create the PK inline with the Key Column [EmpID]. But we will:
– have a separate PK constraint created with Non-Clustered Index for [EmpID] column, and
– an another SQL statement to create a Clustered Index on the [EmpLogInID] column.
DROP TABLE dbo.Employee GO CREATE TABLE dbo.Employee ( EmpID INT NOT NULL, EmpLogInID VARCHAR(255) NULL, EmpFirstName VARCHAR(255) NOT NULL, EmpLastName VARCHAR(255) NOT NULL, Gender BIT NOT NULL, JobTitle VARCHAR(255) NULL, BOD DATETIME NULL, DOJ DATETIME NULL, DeptID INT NOT NULL CONSTRAINT [PK_Employee_EmpID] PRIMARY KEY NONCLUSTERED (EmpID ASC) -- here ) GO -- Creating the Clustered Index separately on an other column: CREATE CLUSTERED INDEX [CI_Employee_EmpLogInID] ON dbo.Employee(EmpLogInID ASC) GO sp_help 'dbo.Employee' GO

The above image shows:
– a Clustered Index (Non-Unique) created on the [EmpLogInID] column with a name we provided,
– a Non-Clustered Index (Unique) created on the [EmpID] column, and
– a PK Constraint created on the [EmpID] column with a name we provided.
So, it is advised to choose your PK & Clustered/Non-Clustered index wisely based upon a proper and justified Business logic. Please do not consider this as a Use Case, but just an example on how to deal with PKs & Indexes.
Check the video on Primary Keys:

Clustered Index will not always guarantee Sorted Rows
In my previous post I discussed about the how Clustered Index’s Data-Pages and Rows are allocated in memory (Disk). I tried to prove that that Clustered Indexes do not guarantee Physical Ordering of Rows. But instead they are Logically Ordered and Sorted.
As they are Logically Sorted and when you query a table without an “ORDER BY” clause you get Sorted Rows, but this is not what will happen always. You can also get rows in Unsorted Order, so to get Sorted rows always apply an “ORDER BY” clause. Here in this post we will see under what circumstances a table will not return Sorted rows:
–> Let’s create a simple table with a Clustered Index on it and add some records:
-- Create table with 2 columns, first beign a PK and an IDENTITY column: CREATE TABLE test2 ( i INT IDENTITY(1,1) PRIMARY KEY NOT NULL, j INT ) -- Let's insert some records in random order on second column: INSERT INTO test2 (j) SELECT 500 UNION ALL SELECT 300 UNION ALL SELECT 900 UNION ALL SELECT 100 UNION ALL SELECT 600 UNION ALL SELECT 200 -- Now we will query the table without using ORDER BY clause: SELECT * FROM test2
–> Output:

You get sorted rows, as the Execution plan shows that Clustered Index was used to fetch the records.
–> Now, what if this table also has a Non Clustered Index, let’s see:
-- We will create a Non Clustered Index on the same table on second column: CREATE INDEX NCI_test ON test2 (j) -- Again query the table without using ORDER BY clause: SELECT * FROM test2
–> Following is the Output of the second SELECT query above:
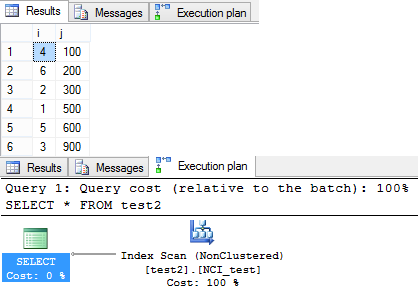
This time the query returned rows in un-ordered fashion. As you can see in the Execution plan Query optimizer preferred to do a Non Clustered Scan. Thus the records were returned in un-ordered fashion.
–> Now, If you add an ORDER BY Clause to your SELECT Query how does it return rows:
-- Added an ORDER BY Clause: SELECT * FROM test2 ORDER BY i
–> Following is the Output of the third SELECT query above:

After adding an “ORDER BY” clause the query optimizer preferd to use the Clustered Index and returns rows in Ordered fashion again.
-- Final Cleanup DROP TABLE test2
So, it is necessary to provide an “ORDER BY” clause to your Queries when you expect to get sorted results, even if the table has Clustered Index on it.
Clustered Index do “NOT” guarantee Physically Ordering or Sorting of Rows
Myth: Lot of SQL Developers I’ve worked with and interviewed have this misconception, that Clustered Indexes are Physically Sorted and Non-Clustered Index are Logically Sorted. When I ask them reasons, all come with their own different versions.
I discussed about this in my previous post long time back, where I mentioned as per the MSDN that “Clustered Indexes do not guarantee Physical Ordering of rows in a Table”. And today in this post I’m going to provide an example to prove it.
Clustered Index is the table itself as its Leaf-Nodes contains the Data-Pages of the table. The Data-Pages are nothing but Doubly Linked-List Data-Structures linked to their leading & preceding Data-Pages. The Data-Pages and rows in them are Ordered by the Clustering Key. Thus there can be only one Clustered Index on a table.
When a new Clustered Index is created on a table, it reorganizes the table’s Data-Pages Physically so that the rows are Logically sorted. But when a tables goes through updates, like INSERT/UPDATE/DELETE operations then the index gets fragmented and thus the Physical Ordering of Data-Pages gets lost. But still the Data-Pages of the Clustered Index or the Table are chained together by Doubly Linked-List in Logical Order.
We will see this behavior in the following example:
USE AdventureWorks2012
GO
CREATE TABLE test (i INT PRIMARY KEY not null, j VARCHAR(2000))
INSERT INTO test (i,j)
SELECT 1, REPLICATE('a',100) UNION ALL
SELECT 2, REPLICATE('a',100) UNION ALL
SELECT 3, REPLICATE('a',100) UNION ALL
SELECT 5, REPLICATE('a',100) UNION ALL
SELECT 6, REPLICATE('a',100)
SELECT * FROM test
DBCC IND(AdventureWorks2012, 'test', -1);
DBCC TRACEON(3604);
DBCC PAGE (AdventureWorks2012, 1, 22517, 1);
As you can see above we inserted 5 records in a table having PK as Clustering Key with following values: 1,2,3,5,6. We skipped the value 4.
–> Here is the Output of DBCC PAGE command execute in the end:
The DBCC PAGE provides very descriptive Output, but here I’ve just extracted the useful information we need.
OFFSET TABLE: Row - Offset 4 (0x4) - 556 (0x22c) --> 1=6 3 (0x3) - 441 (0x1b9) --> 1=5 2 (0x2) - 326 (0x146) --> 1=3 1 (0x1) - 211 (0xd3) --> 1=2 0 (0x0) - 96 (0x60) --> 1=1
It show the 5 rows with their memory allocated address in both decimal and hexadecimal formats, which is contiguous. Thus all the rows are Physically Ordered.
Now, let’s insert the value “4” that we skipped initially:
INSERT INTO test (i,j)
SELECT 4, REPLICATE('a',100)
SELECT * FROM test
DBCC IND(AdventureWorks2012, 'test', -1);
DBCC TRACEON(3604);
DBCC PAGE (AdventureWorks2012, 1, 22517, 1);
–> Here is the new Output of DBCC PAGE command execute in the end:
OFFSET TABLE: Row - Offset 5 (0x5) - 556 (0x22c) --> 1=6 4 (0x4) - 441 (0x1b9) --> 1=5 3 (0x3) - 671 (0x29f) --> 1=4 <-- new row added here 2 (0x2) - 326 (0x146) --> 1=3 1 (0x1) - 211 (0xd3) --> 1=2 0 (0x0) - 96 (0x60) --> 1=1
As you can see very clearly in the output above that the memory allocation address for the new row with PK value = “4” is 671, which is not in between and greater than the address of the last row i.e. 556. The memory address of the last 2 rows is unchanged (441 & 556) and the new row is not accommodated in between as per the sort order but at the end. There is no Physical Ordering and the new row is Logically Chained with other rows and thus is Logically and Ordered, similar to the image below:
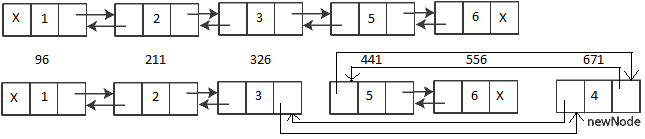
Myth Busted: Hope the above exercise clears that Clustered Indexes do not guarantee the Physical Ordering of Rows & Data Pages.
-- Final Cleanup DROP TABLE test
Clustered vs NonClustered Indexes… and data sorting in SQL Server
This post on difference between Clustered Index & Non Clustered Index is a prequel to my blog post on requirement & use of Clustered index & NonClustered index, [link].
As per MS BOL (MSDN) in SQL Server, indexes are organized as B-trees. Each page in an index B-tree is called an index node. The top node of the B-tree is called the root node. The bottom level of nodes in the index is called the leaf nodes. Any index levels between the root and the leaf nodes are collectively known as intermediate levels.
In Clustered index: (MSDN)
1. The Leaf nodes contain the Data pages of the underlying table.
2. The Root and Intermediate level nodes contain Index pages holding Index rows.
3. Each Index row contains a Key value and a pointer to either an Intermediate level page in the B-tree, or a Data row in the Leaf level of the Index. The Pages in each level of the Index are linked in a Doubly-linked list.
4. The Pages in the Data chain and the rows in them are ordered on the value of the Clustered Index key.
5. There can be only one Clustered Index on a table.
6. Does not support Included column, because they already contain all the columns which are not in the index as Included columns.
In NonClustered Index: (MSDN)
1. The Leaf layer of a NonClustered index is made up of Index pages instead of Data pages.
2. Each Index row in the NonClustered index contains the NonClustered Key value and a row locator. This locator points to the Data row in the Clustered index or Heap having the Key value.
2.a. If the table is a Heap, which means it does not have a Clustered index, the row locator is a pointer to the row.
2.b. If the table has a Clustered index, or the index is on an Indexed view, the row locator is the Clustered index Key for the row. SQL Server retrieves the data row by searching the Clustered index using the Clustered index Key stored in the Leaf row of the NonClustered index.
3. The Data rows of the underlying table are not sorted and stored in order based on their nonclustered keys.
4. Each table can have up to 249 & 999 nonclustered indexes on SQL Server 2005 & 2008 respectively.
Indexing & data Sorting: (MSDN)
As per MS BOL, a Clustered Index only reorganizes the data pages so that the rows are logically sorted in Clustered Index order. The pages are not guaranteed to be ordered physically. SQL Server doesn’t necessarily store the data physically on the disk in clustered-index order, but while creating an index, SQL Server attempts to physically order the data as close to the logical order as possible. Each page in an index’s leaf level has a pointer to the page that logically precedes the current page and to the page that logically follows the current page, thereby creating a doubly linked list. The sysindexes table contains the address of the first leaf-level page. Because the data is guaranteed to be logically in clustered-index order, SQL Server can just start at the first page and follow the index pointers from one page to the next to retrieve the data in order.
So its not guaranteed about the physical ordering of records/rows if a table has Clustered Index on it. It is a common misconsecption among people that Clustered Index sorts data physically & Non Clustered Index sorts data logically.
Also discussed this topic on MSDN’s TSQL forum and got several expert comments & answers: http://social.msdn.microsoft.com/Forums/en-US/transactsql/thread/1c98a7ee-7e60-4730-a38c-f0e3f0deddba
More Info on ordering: https://sqlwithmanoj.com/2013/06/02/clustered-index-do-not-guarantee-physically-ordering-or-sorting-of-rows/
Clustered Indexes, Non Clustered Indexes & why?
Creating Indexes on tables reduces the query retrieval time and increase the efficiency of SQL queries or statements fired against a database in SQL Server. Indexes are just like a Table of Contents in front side of the book or Index section at the back side of the book.
There are mainly 2 types of Indexes, CLUSTERED & NON-CLUSTERED index which can be created on a table.
– Clustered indexes are similar to a telephone directory where you search a person’s name alphabetically and get his phone number there only.
– Non Clustered indexes are similar to the Index of a book where you get the page number of the item you were searching for. Then turn to that page and read what you were looking for.
According to MS BOL one can create only one Clustered index & as many 249 Non Clustered indexes on a single table.
But why there is a need to create these indexes, what causes the fast retrival of data from the tables.
Let’s check this by creating a large table and creating these Indexes one by one and checking as we go one:
USE [AdventureWorks] GO select * from Sales.SalesOrderDetail -- Total 121317 records select * from Production.Product -- Total 504 records SELECT s.SalesOrderDetailID, s.SalesOrderID, s.ProductID, p.Name as ProductName, s.ModifiedDate INTO IndexTestTable FROM Sales.SalesOrderDetail s JOIN Production.Product p on p.ProductID = s.ProductID GO -- Test the table without any Indexes which is also a HEAP SELECT TOP 10 * FROM IndexTestTable --//////////////////////////////////////////////// --// Scenario 1 : When there is no Clustered Index --//////////////////////////////////////////////// SET STATISTICS PROFILE ON SET STATISTICS TIME ON SELECT SalesOrderDetailID FROM IndexTestTable WHERE SalesOrderDetailID = 60000 SET STATISTICS TIME OFF SET STATISTICS PROFILE OFF GO
CPU time = 15 ms, elapsed time = 17 ms. SELECT [SalesOrderDetailID] FROM [IndexTestTable] WHERE [SalesOrderDetailID]=@1 |--Table Scan(OBJECT:([AdventureWorks].[dbo].[IndexTestTable]), WHERE:([AdventureWorks].[dbo].[IndexTestTable].[SalesOrderDetailID]=[@1]))
It does a Table SCAN and takes 15ms of CPU time and elapsed time of 17ms. As the table is a HEAP so it will always SCAN the for matching rows in the entire table. To do a SEEK there must be an ordering of rows which can be done by putting a Primary key column which automatically creates a CLUSTERED INDEX OR creating a CLUSTERED INDEX explicitly shown below would do the ordering.
--// Create Clustered Index on SalesOrderDetailID column CREATE UNIQUE CLUSTERED INDEX IDX_UCI_SalesOrderDetailID ON IndexTestTable (SalesOrderDetailID) GO --// Check with Clustered Index SET STATISTICS PROFILE ON SET STATISTICS TIME ON SELECT SalesOrderDetailID FROM IndexTestTable WHERE SalesOrderDetailID = 60000 SET STATISTICS TIME OFF SET STATISTICS PROFILE OFF GO
CPU time = 0 ms, elapsed time = 1 ms. SELECT [SalesOrderDetailID] FROM [IndexTestTable] WHERE [SalesOrderDetailID]=@1 |--Clustered Index Seek(OBJECT:([AdventureWorks].[dbo].[IndexTestTable].[IDX_UCI_SalesOrderDetailID]), SEEK:([AdventureWorks].[dbo].[IndexTestTable].[SalesOrderDetailID]=[@1]) ORDERED FORWARD)
Now as shown above this does a Clustered Index SEEK after the creation of CLUSTERED Index. After creating an Index the CPU time is reduced to 0ms from 15ms and Elapsed time to 1ms from 17ms. The following queries will also do the SEEK operation:
SELECT SalesOrderDetailID FROM IndexTestTable WHERE SalesOrderDetailID > 60000 SELECT SalesOrderDetailID FROM IndexTestTable WHERE SalesOrderDetailID > 60000 AND SalesOrderDetailID < 70000 SELECT SalesOrderDetailID FROM IndexTestTable WHERE SalesOrderDetailID BETWEEN 60000 AND 70000 --//////////////////////////////////////////////////// --// Scenario 2 : When there is no Non-Clustered Index --//////////////////////////////////////////////////// SET STATISTICS PROFILE ON SET STATISTICS TIME ON SELECT SalesOrderDetailID FROM IndexTestTable WHERE SalesOrderID = 65000 AND ProductID = 711 SET STATISTICS TIME OFF SET STATISTICS PROFILE OFF GO
CPU time = 16 ms, elapsed time = 15 ms. SELECT [SalesOrderDetailID] FROM [IndexTestTable] WHERE [SalesOrderID]=@1 AND [ProductID]>@2 |--Clustered Index Scan(OBJECT:([AdventureWorks].[dbo].[IndexTestTable].[IDX_UCI_SalesOrderDetailID]), WHERE:([AdventureWorks].[dbo].[IndexTestTable].[SalesOrderID]=[@1] AND [AdventureWorks].[dbo].[IndexTestTable].[ProductID]>CONVERT_IMPLICIT(int,[@2],0)))
Now, for every situation or query the query optimizer will not do SEEK. In first query the INDEX was created on SalesOrderDetailID column, so it will not do a SEEK if query is applied on other columns. You would need to create a another INDEX for those columns. But you can create only one CLUSTERED INDEX. But yes you can also create as many as 249 NONCLUSTERED INDEXES on a table, as shown below.
--// Create Non-Clustered Index on SalesOrderID & ProductID columns CREATE NONCLUSTERED INDEX IDX_NCI_SalesOrderID_ProductID ON IndexTestTable (SalesOrderID, ProductID) GO --// Check with Non Clustered Index SET STATISTICS PROFILE ON SET STATISTICS TIME ON SELECT SalesOrderDetailID FROM IndexTestTable WHERE SalesOrderID = 65000 AND ProductID = 711 SET STATISTICS TIME OFF SET STATISTICS PROFILE OFF GO
CPU time = 0 ms, elapsed time = 1 ms. SELECT [SalesOrderDetailID] FROM [IndexTestTable] WHERE [SalesOrderID]=@1 AND [ProductID]>@2 |--Index Seek(OBJECT:([AdventureWorks].[dbo].[IndexTestTable].[IDX_NCI_SalesOrderID_ProductID]), SEEK:([AdventureWorks].[dbo].[IndexTestTable].[SalesOrderID]=[@1] AND [AdventureWorks].[dbo].[IndexTestTable].[ProductID] > CONVERT_IMPLICIT(int,[@2],0)) ORDERED FORWARD)
It does an Index SEEK, not Clustered Index SEEK. So this time it uses the NONCLUSTERED Index to SEEK the matching rows.
--////////////////////////////////////////////////////////////////////////// --// Scenario 3 : When there is no Non-Clustered Index with Included Columns --////////////////////////////////////////////////////////////////////////// SET STATISTICS PROFILE ON SET STATISTICS TIME ON SELECT ProductName FROM IndexTestTable WHERE SalesOrderID = 65000 AND ProductID = 711 SET STATISTICS TIME OFF SET STATISTICS PROFILE OFF GO
CPU time = 0 ms, elapsed time = 1 ms.
SELECT [ProductName] FROM [IndexTestTable] WHERE [SalesOrderID]=@1 AND [ProductID]=@2
|--Nested Loops(Inner Join, OUTER REFERENCES:([AdventureWorks].[dbo].[IndexTestTable].[SalesOrderDetailID]))
|--Index Seek(OBJECT:([AdventureWorks].[dbo].[IndexTestTable].[IDX_NCI_SalesOrderID_ProductID]),
SEEK:([AdventureWorks].[dbo].[IndexTestTable].[SalesOrderID]=(65000)
AND [AdventureWorks].[dbo].[IndexTestTable].[ProductID]=(711)) ORDERED FORWARD)
|--Clustered Index Seek(OBJECT:([AdventureWorks].[dbo].[IndexTestTable].[IDX_UCI_SalesOrderDetailID]),
SEEK:([AdventureWorks].[dbo].[IndexTestTable].[SalesOrderDetailID]=
[AdventureWorks].[dbo].[IndexTestTable].[SalesOrderDetailID]) LOOKUP ORDERED FORWARD)
It still does an Index SEEK, no problem. Please note that it uses both the Indexes CLUSTERED & NONCLUSTERED.
But when you change the WHERE clause and increase the range of selected items then it does a Index SCAN.
SET STATISTICS PROFILE ON SET STATISTICS TIME ON SELECT ProductName FROM IndexTestTable WHERE SalesOrderID > 57916 AND ProductID > 900 SET STATISTICS TIME OFF SET STATISTICS PROFILE OFF GO
CPU time = 32 ms, elapsed time = 709 ms. SELECT [ProductName] FROM [IndexTestTable] WHERE [SalesOrderID]>@1 AND [ProductID]>@2 |--Clustered Index Scan(OBJECT:([AdventureWorks].[dbo].[IndexTestTable].[IDX_UCI_SalesOrderDetailID]), WHERE:([AdventureWorks].[dbo].[IndexTestTable].[SalesOrderID]>(57916) AND [AdventureWorks].[dbo].[IndexTestTable].[ProductID]>(900)))
--// Create NONCLUSTERED Covering Index on SalesOrderID, ProductID with Included Columns on SalesOrderDetailID CREATE NONCLUSTERED INDEX IDX_NCCI_IndexTestTable_SalesOrderID_ProductID ON IndexTestTable (SalesOrderID, ProductID) INCLUDE (ProductName) GO SET STATISTICS PROFILE ON SET STATISTICS TIME ON SELECT ProductName FROM IndexTestTable WHERE SalesOrderID > 57916 AND ProductID > 900 SET STATISTICS TIME OFF SET STATISTICS PROFILE OFF GO
CPU time = 0 ms, elapsed time = 654 ms. SELECT [ProductName] FROM [IndexTestTable] WHERE [SalesOrderID]>@1 AND [ProductID]>@2 |--Index Seek(OBJECT:([AdventureWorks].[dbo].[IndexTestTable].[IDX_NCCI_IndexTestTable_SalesOrderID_ProductID]), SEEK:([AdventureWorks].[dbo].[IndexTestTable].[SalesOrderID] > (57916)), WHERE:([AdventureWorks].[dbo].[IndexTestTable].[ProductID]>(900)) ORDERED FORWARD)
Now, again the query optimizer uses Index SEEK, but it uses the new NONCLUSTERED INDEX with INCLUDED column.
-- Final Cleanup DROP TABLE IndexTestTable
Related MS BOL links: http://msdn.microsoft.com/en-us/library/aa933131%28v=sql.80%29.aspx
BOL links for CLUSTERED Index vs NONCLUSTERED Index:-
http://www.devtoolshed.com/content/clustered-index-vs-non-clustered-index-sql-server
http://www.mssqlcity.com/FAQ/General/clustered_vs_nonclustered_indexes.htm
http://forums.devx.com/showthread.php?t=19018


![]()
Current Visitors

StatCounter …since April 2012

 Leisure blog: Creek & Trails
Leisure blog: Creek & Trails
- NMDC Hyderabad Marathon – My first 42k FM, cramps, training and fuelling
- Singapore (Part 2) – 6 days itinerary, sightseeing & attractions
- Singapore (Part 1) – Tickets, Visa, Hotel, Forex Card/Cash, Metro/Bus cards
- I got full refund of my flight tickets during COVID lockdown (AirIndia via MakeMyTrip)
- YouTube – Your Google Ads account was cancelled due to no spend
- YouTube latest update on its YPP (YouTube Partner Program) which may affect your channel
- Starting your own blog !!!
- How to file ITR (Income Tax Return) online AY 2017-18 (for simple salaried)
- Scam – Become a kin/hier and earn a fortune – via LinkedIn and Email
- Places to visit in and around Vizag (aka Visakhapatnam)
