Archive
SQL Planner, a monitoring tool for SQL Server for DBAs & Developers
SQL Planner is a Microsoft SQL Server monitoring Software product that helps DBA or Developer to identify issues (for ex. High CPU, Memory, Disk latency, Expensive query, Waits, Storage shortage, etc) and root cause analysis with a fast and deep level of analytical reports. Historical data is stored in the repository database for as many days as you want.
About SQL Planner monitoring tool, watch the intro here:
SQL Planner has several features under one roof:
– SQL Server Monitoring
– SQL Server Backup Restore Solution
– SQL Server Index Defragmentation Report and Solution
– SQL server Scripting solution
– DBA Handover Notes Management
Features and Capabilities:
SQL Planner is mainly built for the Monitoring feature and has several metrics as below, their details are available here:
– CPU & Memory Usage reports, Expensive Query and Procedure
– Nice visualization on CPU , Memory , IO usage , expensive query details
– Performance counters Reports
– IO Usage Analysis
– Deadlock & Blockers analysis
– Always On Monitoring
– SQL Server Waits analysis
– SQL Server Agent Job Analysis
– Missing Index analysis
– Storage analysis
– SQL Error Log Scan & Report
– Receiving Alerts: There are 50+ criteria when the Notification is sent via email and
maintained in SQL Planner dashboard too, more details here.
– Handover Notes Management
Cost:
Absolutely forever free to students , teachers and for developer/ DBA in development environment.
Some screenshots of the tool capabilities:
See Execution Plans running with Live Query Statistics – SQL Server 2016
In SQL Server 2016 Live Query Statistics is going to be the most used feature among Developers & DBAs to check the live Execution Plan of an active Query running in parallel.
The Live Query/Execution Plan will provide Real-time insights into the Query Execution process as the Control flows from one Operator to the another. It will display the overall Query Progress and Operator-level Run-time Execution Stats such as:
1. Number of Rows processed
2. Completion Estimate
3. Operator progress – Elapsed time & Percentage done for each Operator
4. Elapsed time & Percentage done for overall Query progress
–> The feature can be enable from the Toolbar, just besides the “Actual Execution Plan” icon:

–> The Live Execution plan running can be seen in below animated image:
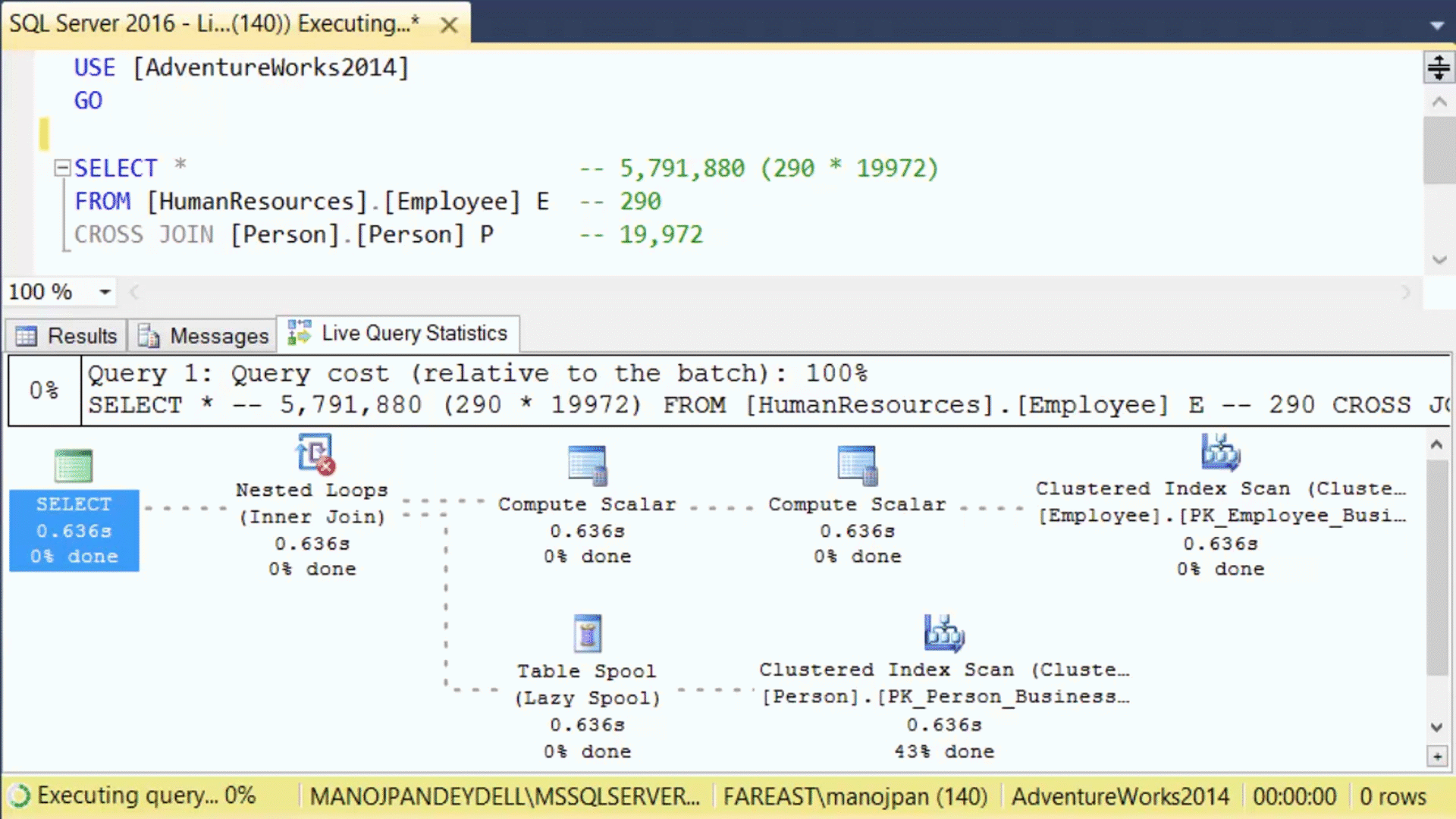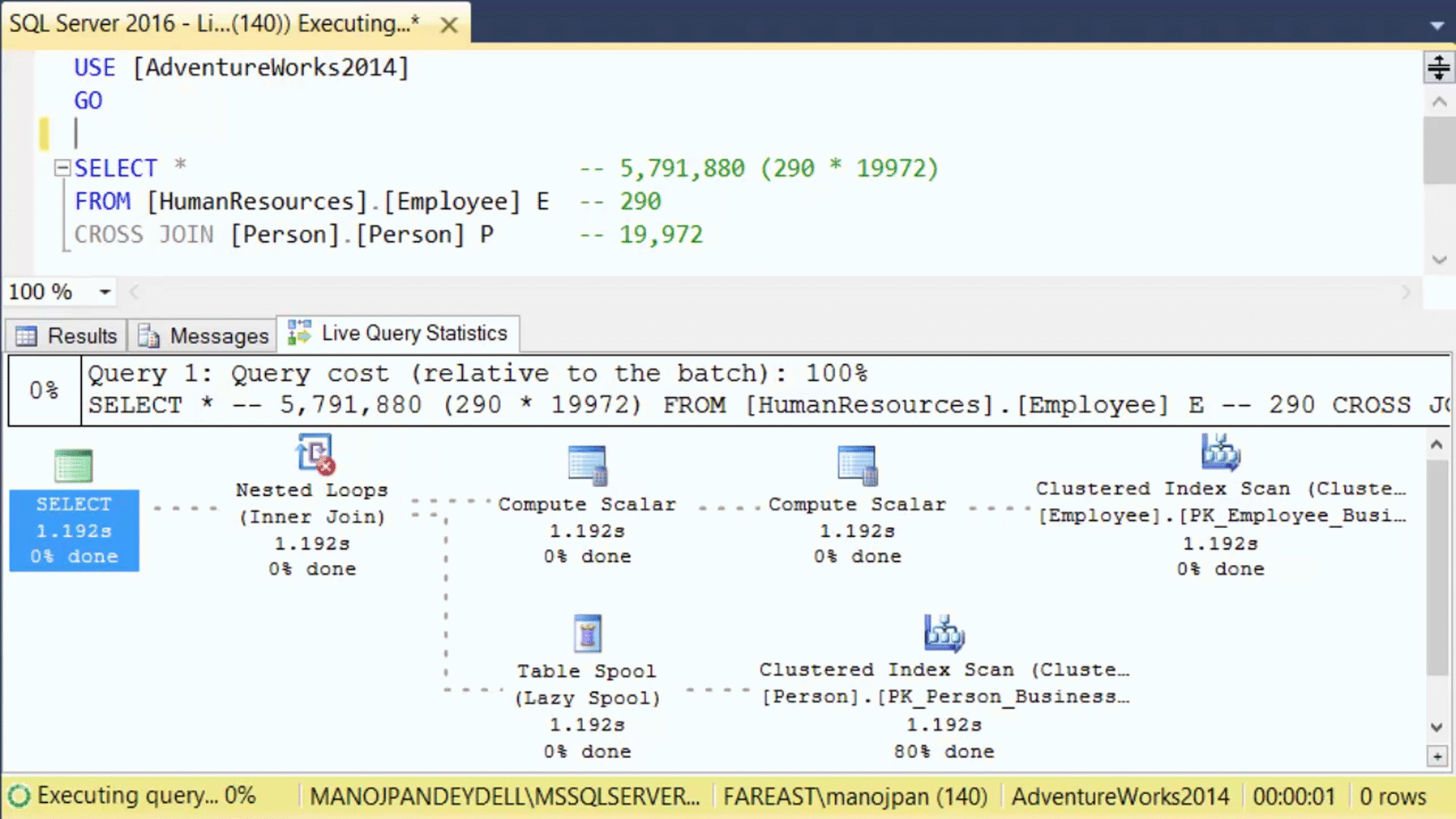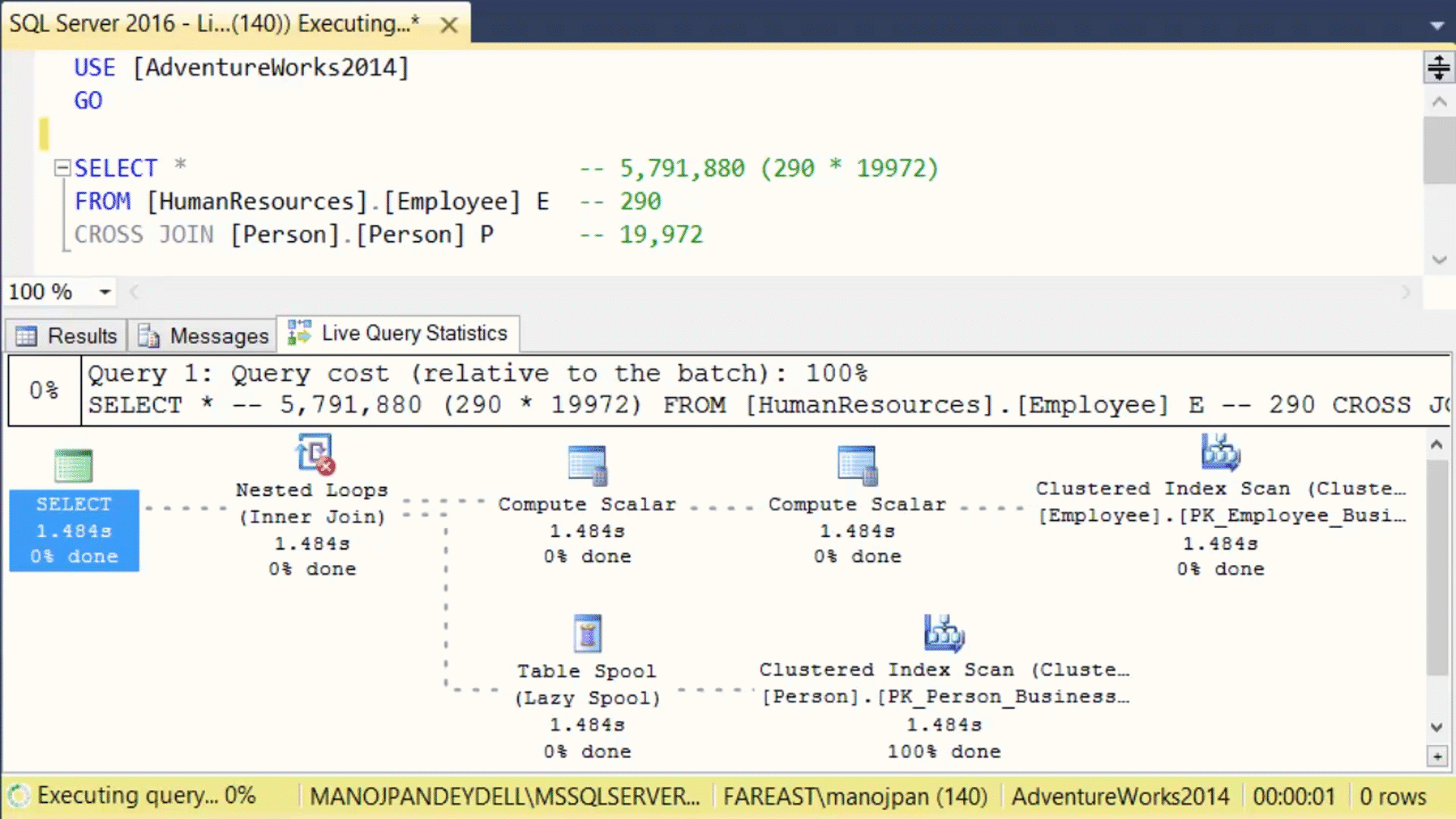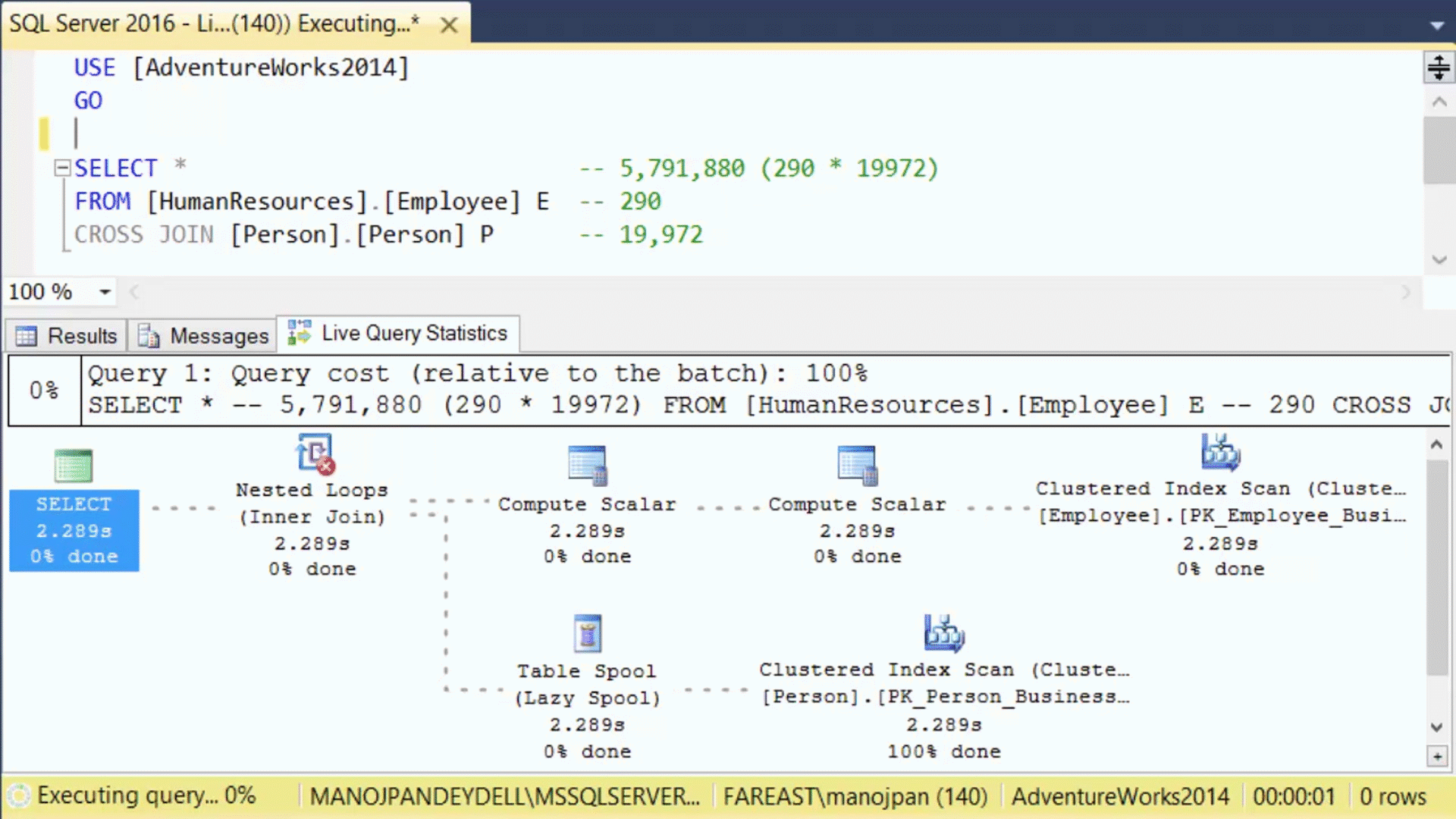
The dotted moving lines above shows the Operators currently in execution. As soon as the Operator finishes execution these dotted lines will change to solid lines.
Thus, by using this feature the user will not have to wait for a Query to complete its execution and then see the Execution plan stats. As soon as the user will run the Query, the Live Execution Plan will also start showing all the Operators and their progress. This will help users in checking the long running queries where actually they are taking time, and help debugging Query performance issues.
You can also check the full demo here in this video:

Enable Query Store on a Database – SQL Server 2016
… continuing from my [previous post] on Query Store.
Here we will see how can we enable it on a Database:
–> Right click on the Database you want to enable Query Store and select Properties. Now select the new feature Query Store at the bottom left side as shown below:

Set the Enable option to True, and click OK.
–> Alternative: You can also enable the Query Store by this simple ALTER DATABASE Statement:
USE [TestManDB] GO ALTER DATABASE [TestManDB] SET QUERY_STORE = ON GO
–> After enabling the Query Store you can check the Database, expand it in Object Explorer, you will see a new folder with the same name “Query Store”, on expanding it you will see 4 reports, as shown in below snapshot:

–> You can check more about Query Store on MSDN BoL [here] with more coverage on what information/stats it captures and how you can Query them.
Index Usage Stats – Indexes Used, Unused and Updated
While working on Performance Optimization and Index tuning many Developers ends up in creating some (or even many) unnecessary Indexes based upon various SQL Queries. Some or many of those Indexes might not be used at all by the SQL Query Optimizer. But even if they are used you may have to Trade-off with your ETL performance going down, as the CRUD (CREATE, READ, UPDATE, DELETE) operations are going to taking more time to update those new Indexes.
So, while creating new Indexes you will have to plan very carefully, decide and balance out things so that your Data retrieval is fast and on the same hand your ETLs are also not affected much.
SQL Server provides some DMVs (Dynamic Management Views) and DMFs (Dynamic Management Functions) to get this information from SQL engine.
–> To know how the Indexes are getting used we can use sys.dm_db_index_usage_stats DMV and this will provide us information on how many times the Index was used for SEEK, SCAN & LOOKUP operations. Check the Query and its output below:
SELECT DB_NAME(database_id) AS DATABASE_NAME, OBJECT_NAME(ius.object_id) AS TABLE_NAME, ids.name AS INDEX_NAME, ius.user_seeks AS SEEK_COUNT, ius.user_scans AS SCAN_COUNT, ius.user_lookups AS LOOKUP_COUNT, ius.user_seeks + ius.user_scans + ius.user_lookups AS TOTAL_USAGE, ius.last_user_seek AS LAST_SEEK_COUNT, ius.last_user_scan AS LAST_SCAN_COUNT, ius.last_user_lookup AS LAST_LOOKUP_COUNT FROM sys.dm_db_index_usage_stats AS ius INNER JOIN sys.indexes AS ids ON ids.object_id = ius.object_id AND ids.index_id = ius.index_id WHERE OBJECTPROPERTY(ius.object_id,'IsUserTable') = 1 ORDER BY DATABASE_NAME, TOTAL_USAGE

–> Now if we want to know the maintenance overhead on the new Indexes we created, like every time a related Table is updated the Indexes are also updated. We can check by using sys.dm_db_index_operational_stats DMF and it will show how many INSERT, UPDATE & DELETE operations are happening on particular indexes. Check the Query and its output below:
SELECT DB_NAME(database_id) AS DATABASE_NAME, OBJECT_NAME(ios.object_id) AS TABLE_NAME, idx.name AS INDEX_NAME, ios.leaf_insert_count AS INSERT_COUNT, ios.leaf_update_count AS UPDATE_COUNT, ios.leaf_delete_count AS DELETE_COUNT, ios.leaf_insert_count + ios.leaf_update_count + ios.leaf_delete_count AS TOTAL_COUNT FROM sys.dm_db_index_operational_stats (NULL,NULL,NULL,NULL ) ios INNER JOIN sys.indexes AS idx ON idx.object_id = ios.object_id AND idx.index_id = ios.index_id WHERE OBJECTPROPERTY(ios.object_id,'IsUserTable') = 1 ORDER BY DATABASE_NAME, TOTAL_COUNT

–> So, by using these two Dynamic Management Views/Functions you can know:
1. What is the affect (maintenance overhead) of Indexes you created, and
2. Are the Indexes really used or not so that you can DROP them.
Please Note: that these stats could be wrong at times because of several reasons, like:
1. If SQL Server (MSSQLSERVER) service is re-started these counters are initialized to 0.
2. When a Database is detached or is shut down (for example, because AUTO_CLOSE is set to ON), all rows associated with the database are removed.
3. Index Rebuild resets these counters to 0 (Bug logged in MS Connect, link).
Memory Optimized Indexes | Hash vs Range Indexes – SQL Server 2014
In SQL Server 2014 for In-Memory tables there are lot of changes in DDLs compared with normal Disk Based Tables. In-Memory Tables related changes we’ve seen in previous posts, check [here]. Here we will see Memory Optimized Index related changes and few important things to take care before designing your Tables and Indexes.
–> Some of the main points to note are:
1. Indexes on In-Memory tables must be created inline with CREATE TABLE DDL script only.
2. These Indexes are not persisted on Disk and reside only in memory, thus they are not logged. As these Indexes are not persistent so they are re-created whenever SQL Server is restarted. Thus In-Memory tables DO NOT support Clustered Indexes.
3. Only two types of Indexes can be created on In-Memory tables, i.e. Non Clustered Hash Index and Non Clustered Index (aka Range Index). So there is no bookmark lookup.
4. These Non Clustered Indexes are inherently Covering, and all columns are automatically INCLUDED in the Index.
5. Total there can be MAX 8 Non Clustered Indexes created on an In-Memory table.
–> Here we will see how Query Optimizer uses Hash & Range Indexes to process query and return results:
1. Hash Indexes: are used for Point Lookups or Seeks. Are optimized for index seeks on equality predicates and also support full index scans. Thus these will only perform better when the predicate clause contains only equality predicate (=).
2. Range Indexes: are used for Range Scans and Ordered Scans. Are optimized for index scans on inequality predicates, such as greater than or less than, as well as sort order. Thus these will only preform better when the predicate clause contains only inequality predicates (>, <, =, BETWEEN).
–> Let’s check this by some hands-on code. We will create 2 similar In-Memory tables, one with Range Index and another with Hash Index:
-- Create In-Memory Table with simple NonClustered Index (a.k.a Range Index):
CREATE TABLE dbo.MemOptTable_With_NC_Range_Index
(
ID INT NOT NULL
PRIMARY KEY NONCLUSTERED,
VarString VARCHAR(200) NOT NULL,
DateAdded DATETIME NOT NULL
) WITH (
MEMORY_OPTIMIZED = ON,
DURABILITY = SCHEMA_AND_DATA
)
GO
-- Create In-Memory Table with NonClustered Hash Index:
CREATE TABLE dbo.MemOptTable_With_NC_Hash_Index
(
ID INT NOT NULL
PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 10000),
VarString VARCHAR(200) NOT NULL,
DateAdded DATETIME NOT NULL
) WITH (
MEMORY_OPTIMIZED = ON,
DURABILITY = SCHEMA_AND_DATA
)
GO
–> Now we will Insert about 10k records on both the tables, so that we have good numbers of records to compare:
DECLARE @i INT = 1
WHILE @i <= 10000
BEGIN
INSERT INTO dbo.MemOptTable_With_NC_Range_Index
VALUES(@i, REPLICATE('a', 200), GETDATE())
INSERT INTO dbo.MemOptTable_With_NC_Hash_Index
VALUES(@i, REPLICATE('a', 200), GETDATE())
SET @i = @i+1
END
–> Now check the Execution Plan by using equality Operator (=) on both the tables:
SELECT * FROM MemOptTable_With_NC_Hash_Index WHERE ID = 5000 -- 4% SELECT * FROM MemOptTable_With_NC_Range_Index WHERE ID = 5000 -- 96%
You will see in the Execution Plan image below that Equality Operator with Hash Index Costs you only 4%, but Range Index Costs you 96%.

–> Now check the Execution Plan by using inequality Operator (BETWEEN) on both the tables:
SELECT * FROM MemOptTable_With_NC_Hash_Index WHERE ID BETWEEN 5000 AND 6000 -- 99% SELECT * FROM MemOptTable_With_NC_Range_Index WHERE ID BETWEEN 5000 AND 6000 -- 1%
You will see in the Execution Plan image below that Inequality Operator with Range Index Costs you only 1%, but Hash Index Costs you 99%.

So, while designing In-Memory Tables and Memory Optimized Indexes you will need to see in future that how you will be going to query that table. It also depends upon various scenarios and conditions, so always keep note of these things in advance while designing your In-Memory Tables.
Update: Know more about In-Memory tables:


![]()
Current Visitors

StatCounter …since April 2012

 Leisure blog: Creek & Trails
Leisure blog: Creek & Trails
- NMDC Hyderabad Marathon – My first 42k FM, cramps, training and fuelling
- Singapore (Part 2) – 6 days itinerary, sightseeing & attractions
- Singapore (Part 1) – Tickets, Visa, Hotel, Forex Card/Cash, Metro/Bus cards
- I got full refund of my flight tickets during COVID lockdown (AirIndia via MakeMyTrip)
- YouTube – Your Google Ads account was cancelled due to no spend
- YouTube latest update on its YPP (YouTube Partner Program) which may affect your channel
- Starting your own blog !!!
- How to file ITR (Income Tax Return) online AY 2017-18 (for simple salaried)
- Scam – Become a kin/hier and earn a fortune – via LinkedIn and Email
- Places to visit in and around Vizag (aka Visakhapatnam)
