Archive
SQL Server 2017 – ColumnStore Index enhancements and improvements over previous versions
ColumnStore Indexes were first introduced in SQL Server 2012, and this created a new way to store and retrieve the Index or Table data in an efficient manner.
–> What’s new in SQL Server 2017?
1. Online Non-Clustered ColumnStore index build and rebuild support added
2. Clustered Columnstore Indexes now support LOB columns (nvarchar(max), varchar(max), varbinary(max))
3. Columnstore index can have a non-persisted computed columns
4. The -fc option in Database Tuning Advisor (DTA) for allowing recommendations of ColumnStore indexes
–> Video on ColumnStore Index:
ColumnStore Indexes evolution from SQL Server 2012, 2014 to 2016
ColumnStore Indexes were first introduced in SQL Server 2012, and this created a new way to store and retrieve the Index or Table data in an efficient manner.
ColumnStore uses xVelocity technology that was based on Vertipaq engine, this uses a new Columnar storage technique to store data that is highly Compressed and is capable of In-memory Caching and highly parallel data scanning with Aggregation algorithms.
ColumnStore or Columnar data format does not store data in traditional RowStore fashion, instead the data is grouped and stored as one column at a time in Column Segments.
The Traditional RowStore stores data for each row and then joins all the rows and store them in Data Pages, and is still the same storage mechanism for Heap and Clustered Indexes.
Thus, a ColumnStore increases the performance by reading less data that is highly compressed, and in batches from disk to memory by further reducing the I/O.
–> To know more about ColumnStore Indexes check [MSDN BoL].
–> Let’s see the journey of ColumnStore index from SQL Server 2012 to 2016:
✔ We will start with SQL Server 2012 offering for ColumnStore Indexes:
1. A Table (Heap or BTree) can have only one NonClustered ColumnStore Index.
2. A Table with NonClustered ColumnStore Index becomes readonly and cannot be updated.
3. The NonClustered ColumnStore Index uses Segment Compression for high compression of Columnar data.
✔ With SQL Sever 2014 some new features were added, like:
1. You can create one Clustered ColumnStore Index on a Table, and no further Indexes can be created.
2. A Table with Clustered ColumnStore Index can be updated with INSERT/UPDATE/DELETE operations.
3. Both Clustered & NonClustered ColumnStore Index has new Archival Compression options i.e. COLUMNSTORE_ARCHIVE to further compress the data.
✔ Now with SQL Server 2016 new features have been added and some limitations are removed:
1. A Table will still have one NonClustered ColumnStore Index, but this will be updatable and thus the Table also.
2. Now you can create a Filtered NonClustered ColumnStore Index by specifying a WHERE clause to it.
3. A Clustered ColumnStore Index table can have one or more NonClustered RowStore Indexes.
4. Clustered ColumnStore Index can now be Unique indirectly as you can create a Primary Key Constraint on a Heap table (and also Foreign Key constraints).
5. Columnar Support for In-Memory (Hekaton) tables, as you can create one one ColumnStore Index on top of them.
–> Here is the full feature summary of ColumnStore Indexe evolution from SQL Server 2012 to 2016:

–> Check more about this on [MSDN BoL].
Check the above details explained in the video below:
ColumnStore Index enhancements in SQL Server 2014
ColumnStore Indexes were first introduced in SQL Server 2012, and this created a new way to store and retrieve the Index or Table data in an efficient manner.
ColumnStore uses xVelocity technology that was based on Vertipaq engine, this uses a new Columnar storage technique to store data that is highly Compressed and is capable of In-memory Caching and highly parallel data scanning with Aggregation algorithms.
ColumnStore or Columnar data format does not store data in traditional RowStore fashion, instead the data is grouped and stored as one column at a time in Column Segments.
The Traditional RowStore stores data for each row and then joins all the rows and store them in Data Pages, and is still the same storage mechanism for Heap and Clustered Indexes.
Thus, a ColumnStore increases the performance by reading less data that is highly compressed, and in batches from disk to memory by further reducing the I/O.
–> To know more about ColumnStore Indexes check [MSDN BoL].
✔ We will start with SQL Server 2012 offering for ColumnStore Indexes:
1. A Table (Heap or BTree) can have only one NonClustered ColumnStore Index.
2. A Table with NonClustered ColumnStore Index becomes readonly and cannot be updated.
3. The NonClustered ColumnStore Index uses Segment Compression for high compression of Columnar data.
✔ With SQL Sever 2014 some new features were added, like:
1. You can create one Clustered ColumnStore Index on a Table, and no further Indexes can be created.
2. A Table with Clustered ColumnStore Index can be updated with INSERT/UPDATE/DELETE operations.
3. Both Clustered & NonClustered ColumnStore Index has new Archival Compression options i.e. COLUMNSTORE_ARCHIVE to further compress the data.
–> Check more about this on [MSDN BoL].
Columnstore Indexes in SQL Server 2012
This time the new version of SQL Server 2012 a.k.a Denali has introduced a new kind of index i.e. ColumnStore Index, which is very different from the traditional indexes. This new index differs in the way it is created, stores its table contents in specific format and provides fast retrieval of data from the new storage.
–> Before talking about ColumnStore Index, let’s first check and understand what is a ColumnStore?
ColumnStore is a data storage method that uses xVelocity technology based upon Vertipaq engine, which uses a new Columnar storage technique to store data that is highly Compressed and is capable of In-memory Caching and highly parallel data scanning with Aggregation algorithms.
Traditionally, on the other side a RowStore is the traditional and by-default way to store data for each row and then joins all the rows and store them in Data Pages, and is still the same storage mechanism for Heap and Clustered Indexes.
The ColumnStore or Columnar data format does not store data in traditional RowStore fashion, instead the data is grouped and stored as one column at a time in Column Segments.
–> Here is what happens when you try to create a ColumnStore Index on a table:
1. Existing table rows are divided into multiple RowGroups, a Row-Group can contain upto 1 million rows.
2. Each column of a RowGroup is stored in its own Segment and is compressed.
3. The individual compressed Column Segments are added to the ColumnStore.
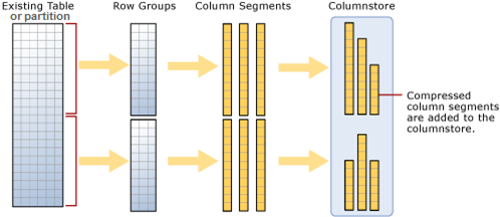
4. When new rows are inserted or existing ones are updated (in small batches, except BulkLoad) they are added to a separate Delta Store, upto a threshold of 1 million rows.
5. When a Delta-Store reaches its threshold of 1 million rows a separate process Tuple-mover invokes and closes the delta-store, compresses it & stores it into the ColumnStore index.
–> Thus, Columnstore indexes can produce faster results by doing less I/O operations by following:
1. Reading only the required columns, thus less data is read from disk to memory.
2. Heavy Column compression, which reduces the number of bytes that must be read and moved.
3. Advanced query execution technology by processing chunks of columns called batches (1000 rows) in a streamlined manner, further reducing CPU usage.
4. Stored as ColumnStore Object Pool in RAM to cache ColumnStore Index, instead of SQL Buffer Pool (for Pages)
–> Please Note: In SQL Server 2012 ColumnStore indexes has some limitations:
1. A Table (Heap or BTree) can have only one NonClustered ColumnStore Index.
2. Cannot be a Clustered Index.
3. A Table with NonClustered ColumnStore Index becomes readonly and cannot be updated.
4. Check MSDN BoL for more limitations with SQL Server 2012 version, link.
SQL Server 2012 (a.k.a. Denali) | The Fantastic 12 of 2012
SQL Server team has come up with a new series to promote its new product and create awareness among techies about what SQL Server 2012 is capable of and what new features it comes packed with. Check out the full series of The Fantastic 12 of SQL Server 2012 here.
The above link will provide you direct access to the technet blogs with detailed info on all 12 topics and videos.
The series will talk about 12 new features, which are as follows:
1. Required 9s Data Protection:
– Always On
– New support for Windows Server Core
2. Blazing-Fast Performance:
– New ColumnStore Index, [video]
– Improved Full Text Search
– Good Compression capabilities.
3. Organizational Security and Compliance:
– Data Protection (Encryption and Compression)
– Control Access (User-Defined Server Roles, Default Schema for Groups, Contained Database Authentication and Active Directory)
– Ensure Compliance (SQL Server Audit and Policy-Based Management)
4. Peace of Mind:
– Product Enhancements (Distributed Replay, System Center Alignment, System Center Advisor and No-fee Service Packs)
– Free Planning Tools
– Tailored Support and Licensing Programs (Mission Critical Support and Enrollment for Application Platform)
5. Rapid Data Exploration & Visualization:
– Self-Service Analytics (Power Pivot)
– Stunning, interactive data visualization (Power View)
6. Managed Self-Service BI:
– Gain insight and oversight (Power Pivot for SharePoint)
– Enable IT Efficiency (End user created, IT managed, Ease of administration through SharePoint and SQL Azure Reporting)
7. Credible, Consistent Data:
– BI Semantic Model
– Integration Services
– Data Quality Services
– Master Data Services
8. Scalable Analytics & Data Warehousing:
– Flexibility and Choice (Hardware and deployment options and Optimized Solutions)
– Massive Scale at Low Cost (Built-in Functionality, Support for Powerful Hardware and Parallel Data Warehouse)
– Complete BI Solution (Scalable OLAP)
9. Scale On Demand:
– Self-service Deployments
– SQL Azure Federation
– Contained Databases
– License Mobility
– Data Sync
10. Fast Time To Solution:
– Optimized Transaction processing and data warehousing
– Complete solutions co-engineered with hardware partners
– Agile to market from weeks and months to days
11. Optimized Productivity:
– SQL Server Data Tools
– T-SQL Enhancements
– Common tools
– SQL Server Management Studio
12. Extend Any Data, Anywhere:
– Support for Any Data
– Statistical Semantic Full-Text Search
– OData
– SQL Azure DataMarket
– Enhanced interop support
This “Fantastic 12” feature list is also available for download, and the PDF is here.
Check out the Webcast/Videos for all these 12 features, here.


![]()
Current Visitors

StatCounter …since April 2012

 Leisure blog: Creek & Trails
Leisure blog: Creek & Trails
- NMDC Hyderabad Marathon – My first 42k FM, cramps, training and fuelling
- Singapore (Part 2) – 6 days itinerary, sightseeing & attractions
- Singapore (Part 1) – Tickets, Visa, Hotel, Forex Card/Cash, Metro/Bus cards
- I got full refund of my flight tickets during COVID lockdown (AirIndia via MakeMyTrip)
- YouTube – Your Google Ads account was cancelled due to no spend
- YouTube latest update on its YPP (YouTube Partner Program) which may affect your channel
- Starting your own blog !!!
- How to file ITR (Income Tax Return) online AY 2017-18 (for simple salaried)
- Scam – Become a kin/hier and earn a fortune – via LinkedIn and Email
- Places to visit in and around Vizag (aka Visakhapatnam)
