SQL Server 2022 preview announced, some awesome new features !!!
SQL Server 2022 is coming !!!
On 2nd November 2021 in MS Ignite 2021 event Microsoft announced the preview of new version of SQL Server i.e. SQL Server 2022.
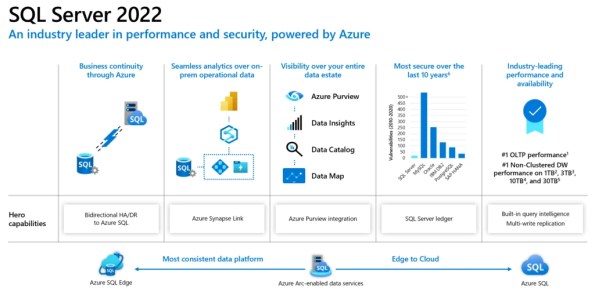
SQL Server 2022 will be more focused on Azure-enabled cloud and big data space, here are some excerpts from the announcements:
1. Azure Synapse link integration with SQL for ETL free and real time reporting & analytics: Here you can setup a Synapse Link relationship between SQL Pool in Azure Synapse and SQL Server as a data source and link required tables in Synapse Workspace. You can create PowerBI reports on top of these tables available in Synapse Workspace with real time data, without requiring you to write/setup an ETL from SQL Server to Synapse SQL Pool. This will also let you combine/JOIN datasets from different sources, data lake, files, etc. Similarly Data Scientists can create ML Models by using Synapse Spark Pools with PySpark language.
2. Azure Purview integration: with also work with SQL Server, for data discovery and data governance. Here you can use Purview to scan and capture SQL Server metadata for data catalog, classify the data (PII, non-PII, etc), and even control access rights on SQL Server.
3. Bi-directional HA/DR between SQL Server and Azure SQL MI: Now you can use Azure SQL Managed Instance as a Disaster Recovery site for your SQL Server workloads. You can setup Disaster Recovery as a Managed Service with Azure SQL Managed Instance (SQL MI). A Distributed Availability Group is created automatically with a new Azure SQL MI as READ_ONLY replica. This way you you can do failover from SQL Server to Azure SQL MI, and also back from Azure SQL MI to SQL Server.
4. QueryStore and IQP enhancements: Parameter Sensitive Plan optimization for handling Parameter Sniffing issues. Now the SQL optimizer will cache multiple plans for a Stored Procedure which uses different parameter values having big gap in cardinality providing consistent query performance. Enhancements on Cardinality-Estimation & Max-DOP feedback, and support for read replicas from Availability Groups.
5. SQL Server Ledger: Built on Blockchain technology, this feature will allow you to create and setup smart contracts on SQL Server itself. With ledger based immutable record of data you can make sure the data modified over time is not tampered with, and will be helpful in Banking, Retail, e-commerce, Supply Chain and many more industries.
6. Scalable SQL Engine and new features coming:
– Buffer Pool parallel scan
– Improvements on tempDB latch contention (System page GAM/SGAM concurrency)
– In-Memory (Hekaton) OLTP enhancements
– Multi-write replication with last writer wins
– Redesigned and improved SPANSHOT backups
– Polybase (REST API) for connecting to various files formats (parquet, JSON, csv) in Data lake, Delta tables, ADLS, S3, etc.
– Backup/Restore to S3 storage
– JSON enhancements and new functions
– New Time series T-SQL functions
For more details on SQL Server 2022 please check here” Microsoft official SQL Server Blog.
SQL DBA – Integration Services evaluation period has expired
I got an email from one SQL Server developer that he is not able to use import/export wizard and it is failing with below error:
TITLE: SQL Server Import and Export Wizard --------------------------------------
Data flow execution failed. Error 0xc0000033:
{5CCE2348-8B9F-4FD0-9AFA-9EA6D19576A7}: Integration Services evaluation period has
expired. Error 0xc0000033: {5CCE2348-8B9F-4FD0-9AFA-9EA6D19576A7}: Integration
Services evaluation period has expired. ------------------------------
ADDITIONAL INFORMATION: Integration Services evaluation period has expired.
({5CCE2348-8B9F-4FD0-9AFA-9EA6D19576A7}) ----------------------------------------
–> Investigate:
As per the above error message its clear that the SQL Server Instance that you had installed was under Evaluation of 180 days, because you didn’t applied any Product Key. So, now how can you make it usable again? All you need is a Product key of SQL Server and installation media to start an upgrade so that you can apply the new Product Key there.
–> Fix:
1. Open the SQL Server Installation Center and click on Maintenance link, and then click on Edition Upgrade:

2. Now on the Upgrade window Click Next and you will reach the Product Key page, apply the Key and click Next:

3. On the Select Instance page, select the SQL Instance that you want to fix and Click next. It will take some time and finally you will see a final window and click Upgrade:

4. Finally you will see the successful window, click on Close button:

5. Now Restart the SQL Server Service for this Instance, and you will see it running fine.
–> Finally, go back to SSMS and now you can connect to the SQL Instance.
Spark – Cannot perform Merge as multiple source rows matched…
In SQL when you are syncing a table (target) from an another table (source) you need to make sure there are no duplicates or repeated datasets in either of the Source or Target tables, otherwise you get following error:
UnsupportedOperationException: Cannot perform Merge as multiple source rows matched and attempted to modify the same target row in the Delta table in possibly conflicting ways. By SQL semantics of Merge, when multiple source rows match on the same target row, the result may be ambiguous as it is unclear which source row should be used to update or delete the matching target row. You can preprocess the source table to eliminate the possibility of multiple matches. Please refer to https://docs.microsoft.com/azure/databricks/delta/delta-update#upsert-into-a-table-using-merge
The above error says that while doing MERGE operation on the Target table there shouldn’t be any duplicates in the Source table. This check is applied implicitly by the SQL engine to avoid unnecessary updates and avoid inconsistent data.
So, to avoid this issue make sure you have de-duplication logic before the MERGE operation.
Below is a small demo to reproduce this error.
Let’s create two sample tables (Source & Target) for our demo purpose:
val df1 = Seq((1, "Brock", 30),
(2, "John", 31),
(2, "Andy", 35), //duplicate ID = 2
(3, "Jane", 25),
(4, "Maria", 30)).toDF("Id", "name", "age")
spark.sql("drop table if exists tblPerson")
df1.write.format("delta").saveAsTable("tblPerson")
val df2 = Seq((1, "Jane", 30),
(2, "John", 31)).toDF("Id", "name", "age")
spark.sql("drop table if exists tblPersonTarget")
df2.write.format("delta").saveAsTable("tblPersonTarget")
Next we will try to MERGE the tables and running the query will result in an error:
val mergeQuery =
s"""MERGE INTO tblPersonTarget As tgt
Using tblPerson as src
ON src.Id = tgt.ID
WHEN MATCHED
THEN UPDATE
SET
tgt.name = src.name,
tgt.age = src.age
WHEN NOT MATCHED
THEN INSERT (
ID,
name,
age
)
VALUES (
src.ID,
src.name,
src.age
)"""
spark.sql(mergeQuery)
To remove duplicates you can simply try removing by using window functions or some logic as per your business requirement:
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.functions._
val df2 = df1.withColumn("rn", row_number().over(window.partitionBy("Id").orderBy("name")))
val df3 = df2.filter("rn = 1")
display(df3)
Python – Delete/remove unwanted rows from a DataFrame
As you start using Python you will fall in love with it, as its very easy to solve problems by writing complex logic in very simple, short and quick way. Here we will see how to remove rows from a DataFrame based on an invalid List of items.
Let’s create a sample Pandas DataFrame for our demo purpose:
import pandas as pd
sampleData = {
'CustId': list(range(101, 111)),
'CustomerName': ['Cust'+str(x) for x in range(101, 111)]}
cdf = pd.DataFrame(sampleData)
invalidList = [102, 103, 104]
The above logic in line # 4 & 5 creates 10 records with CustID ranging from 101 to 110 and respective CustomerNames like Cust101, Cust102, etc.
In below code we will use isin() function to get us only the records present in Invalid list. So this will fetch us only 3 invalid records from the DataFrame:
df = cdf[cdf.CustId.isin(invalidList)] df
And to get the records not present in InvalidList we just need to use the “~” sign to do reverse of what we did in above step using the isin() function. So this will fetch us other 7 valid records from the DataFrame:
df = cdf[~cdf.CustId.isin(invalidList)] df
Python error – Length of passed values is 6, index implies 2 (while doing PIVOT with MultiIndex or multiple columns)
As I’m new to Python and these days using it for some Data Analysis & Metadata handling purpose, and also being from SQL background here I’m trying to use as many analysis features I use with SQL, like Group By, Aggregate functions, Filtering, Pivot, etc.
Now I had this particular requirement to PIVOT some columns based on multi-index keys, or multiple columns as shown below:

But while using PIVOT function in Python I was getting this weird error that I was not able to understand, because this error was not coming with the use of single index column.
ValueError: Length of passed values is 6, index implies 2.
Let’s create a sample Pandas DataFrame for our demo purpose:
import pandas as pd
sampleData = {
'Country': ['India', 'India', 'India','India','USA','USA'],
'State': ['UP','UP','TS','TS','CO','CO'],
'CaseStatus': ['Active','Closed','Active','Closed','Active','Closed'],
'Cases': [100, 150, 300, 400, 200, 300]}
df = pd.DataFrame(sampleData)
df
Problem/Issue:
But when I tried using the below code which uses pivot() function with multiple columns or multi-indexes it started throwing error. I was not getting error when I used single index/column below. So what could be the reason?
# Passing multi-index (or multiple columns) fails here:
df_pivot = df.pivot(index = ['Country','State'],
columns = 'CaseStatus',
values = 'Cases').reset_index()
df_pivot
Solution #1
Online checking I found that the pivot() function only accepts single column index key (do not accept multiple columns list as index). So, in this case first we would need to use set_index() function and set the list of columns as shown below:
# Use pivot() function with set_index() function:
df_pivot = (df.set_index(['Country', 'State'])
.pivot(columns='CaseStatus')['Cases']
.reset_index()
)
df_pivot
Solution #2
There is one more simple option where you can use pivot_table() function as shown below and get the desired output:
# or use pivot_table() function:
df_pivot = pd.pivot_table(df,
index = ['Country', 'State'],
columns = 'CaseStatus',
values = 'Cases')
df_pivot


![]()
Current Visitors

StatCounter …since April 2012

 Leisure blog: Creek & Trails
Leisure blog: Creek & Trails
- NMDC Hyderabad Marathon – My first 42k FM, cramps, training and fuelling
- Singapore (Part 2) – 6 days itinerary, sightseeing & attractions
- Singapore (Part 1) – Tickets, Visa, Hotel, Forex Card/Cash, Metro/Bus cards
- I got full refund of my flight tickets during COVID lockdown (AirIndia via MakeMyTrip)
- YouTube – Your Google Ads account was cancelled due to no spend
- YouTube latest update on its YPP (YouTube Partner Program) which may affect your channel
- Starting your own blog !!!
- How to file ITR (Income Tax Return) online AY 2017-18 (for simple salaried)
- Scam – Become a kin/hier and earn a fortune – via LinkedIn and Email
- Places to visit in and around Vizag (aka Visakhapatnam)
