Archive
Self Service BI by using Power BI – Power Query (Part 1)
In my previous posts I discussed about Power BI [link], what is it, its components, features and capabilities in the new world of Self Service IB.
Self Service BI allows end users to design & deploy their own reports, analyse within an approved & supported architecture and tools portfolios. End users do not have to worry about maintaining databases, doing integrations, creating warehouses/marts, reports, etc. The Self Service BI tool provide features which are capable enough to do all these activities in an automated, quick and efficient way, and all you have to do is learn how to configure these tools.
Power BI is one such tool offered by Microsoft, you can read about it my previous posts, [link] and Microsoft Official blog, [link].
Power BI works ONLY with Excel & Office 365. It is nothing but a collection of different components which provide features as follows:
1. Power Query
2. Power Pivot
3. Power View (aka Crescent)
4. Power Map (aka GeoFlow)
5. Power Q & A (aka Natural Language Processing)
6. Office 365
7. Windows 8 App
–> Power Query is used to easily discover or gather data from various public or corporate sources, like:
| Web page | SQL Server database | IBM DB2 database | Windows Azure Marketplace |
| Excel or CSV file | Windows Azure SQL Database | MySQL database | Active Directory |
| XML file | HDInsight | SharePoint List | |
| Text file | Access database | OData feed | SAP BusinessObjects BI Universe |
| Folder | Oracle database | Hadoop Distributed File System (HDFS) |
–> Let’s see a small demo how you can use Power Query: All you need is Excel and Power Query add-In, which you can download from Microsoft official site, [link].
Below image shows various ways you can access public or corporate data from various sources from an Excel workbook:
1. Online Search
2. From File
3. From Database
4. From Other Sources
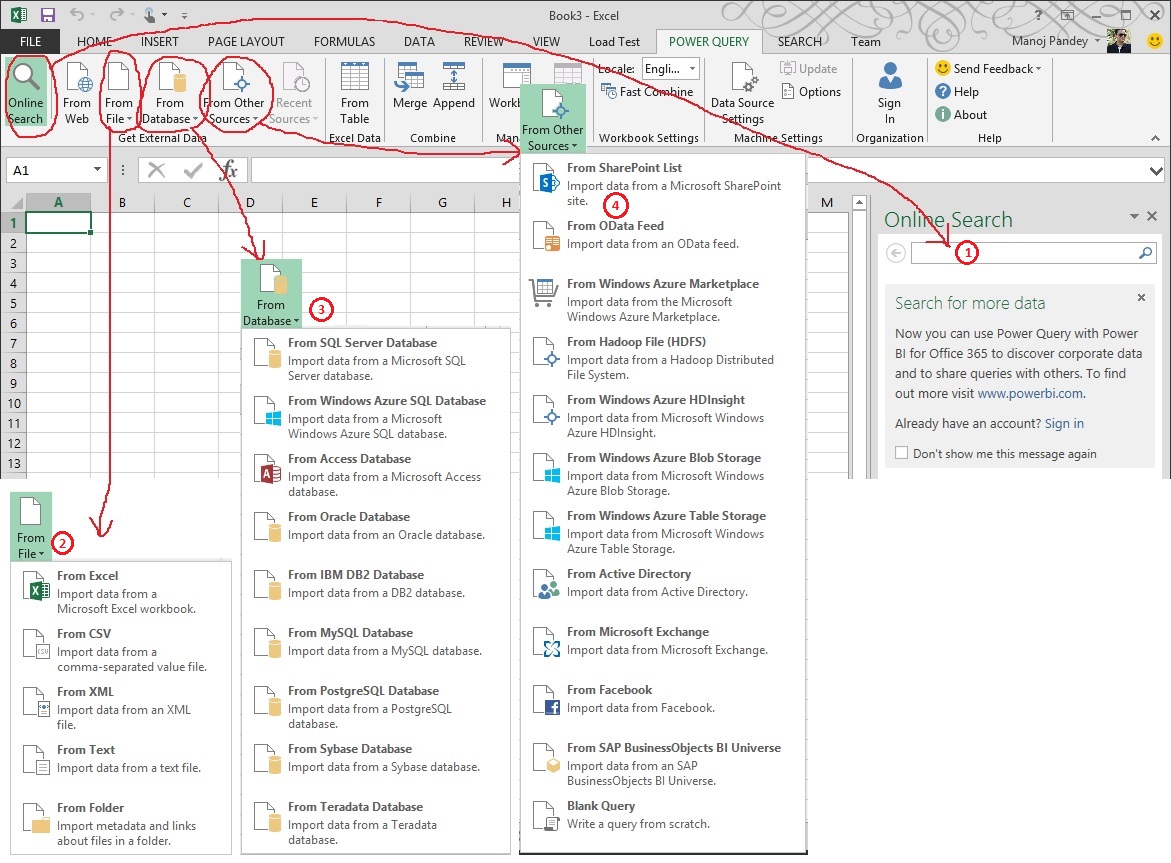
Let’s see how Online Search works. The moment you type “Olympics 2014” it populates lot of sources from where you can fetch data from:

On selecting a source it tries to connect to the public portal and displays the Source URL while fetching the data:
And finally populates the data in tabular format in an Excel worksheet:
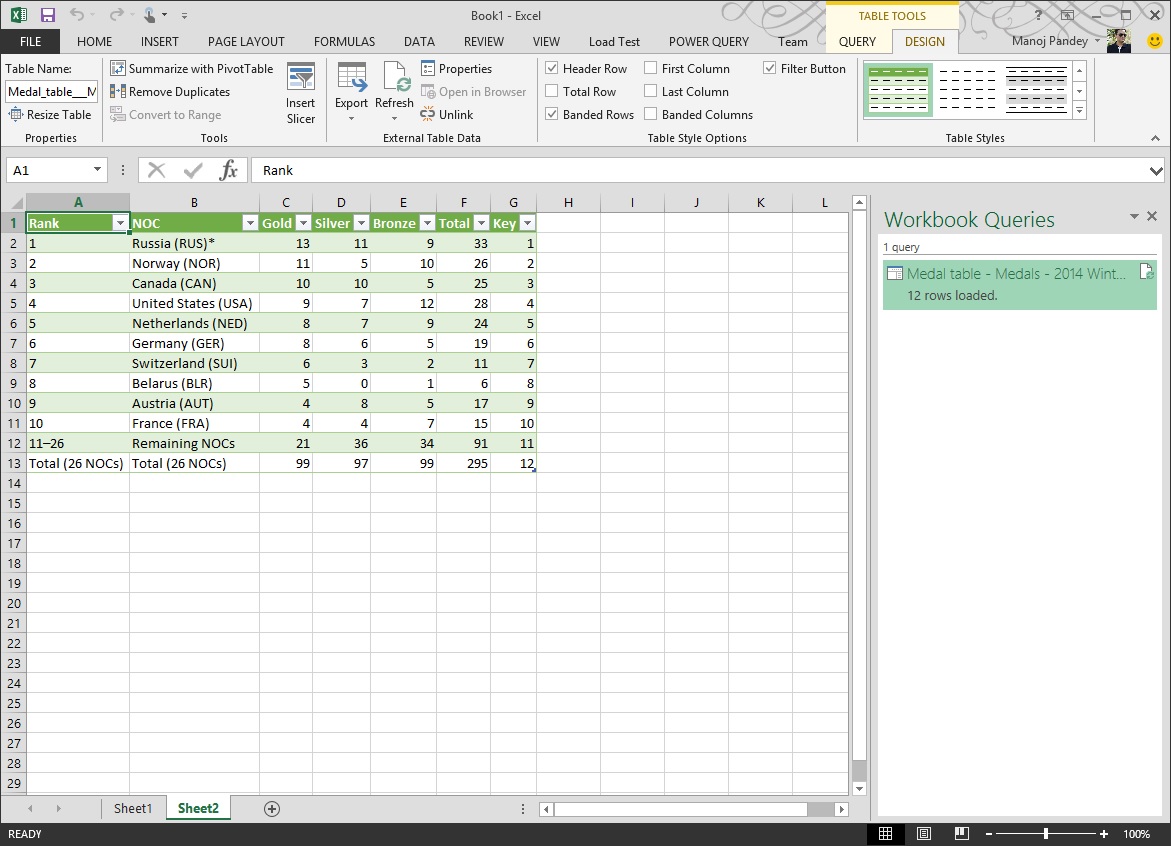
Go to Ribbon, click “Table Tools” -> Query -> Edit, this will open the “Query Editor” window where you can edit, clean the data. You can even Create Queries that you can save and use again later to refresh your data. Merge different tables in one step; rename, delete or even create fields. Transform your data before even importing it into a spreadsheet.

This way you can get your data ‘analysis ready’ with Power Query !!!
SQL Tip – Disable or Enable all Indexes of a table at once
There are times when you need to DISABLE all Indexes of a table, like when there is a need to INSERT/UPDATE huge records in a table. As you have to INSERT huge records in a table the whole INSERT process could take more time to maintain/process Indexes on that table. Thus before inserting records its good to DISABLE all Non-Clustered indexes and post processing Re-Enable them.
USE [AdventureWorks2014] GO -- Disable Index -- Syntax: ALTER INDEX [idx_name] ON [table_name] DISABLE; ALTER INDEX [IX_Person_LastName_FirstName_MiddleName] ON [Person].[Person] DISABLE; GO -- Enable Index -- Syntax: ALTER INDEX [idx_name] ON [table_name] REBUILD; ALTER INDEX [IX_Person_LastName_FirstName_MiddleName] ON [Person].[Person] REBUILD; GO
Please note: to Enable you need to use REBUILD option, there is no ENABLE option just like DISABLE in above DDL statements.
–> Generate Queries of ALTER DDL scripts to:
– Disable all Indexes:
SELECT o.name, 'ALTER INDEX ' + QUOTENAME(i.name) + ' ON ' + QUOTENAME(SCHEMA_NAME(o.[schema_id])) + '.' + QUOTENAME(o.name) + ' DISABLE;' FROM sys.indexes i INNER JOIN sys.objects o ON o.object_id = i.object_id WHERE o.is_ms_shipped = 0 AND i.index_id >= 1 AND o.name = 'Person'
– Enable all Indexes:
SELECT o.name, 'ALTER INDEX ' + QUOTENAME(i.name) + ' ON ' + QUOTENAME(SCHEMA_NAME(o.[schema_id])) + '.' + QUOTENAME(o.name) + ' REBUILD;' FROM sys.indexes i INNER JOIN sys.objects o ON o.object_id = i.object_id WHERE o.is_ms_shipped = 0 AND i.index_id >= 1 AND o.name = 'Person'
Maintaining Uniqueness with Clustered ColumnStore Index | SQL Server 2014
Column Store indexes were introduced in SQL Server 2012 with a flavor of Non-Clustered index i.e. “Non-Clustered ColumnStore” index. However there is a big limitation that the underlying table becomes read-only as soon as you create one.
In SQL Server 2014 this behavior is unchanged and addition to this you can also create ColumnStore index as a Clustered index. And the good thing is that the table having “Clustered ColumnStore” index can also be updated. However there is one more big limitation here that there is no Clustered Key with this type if index, thus risking the Uniqueness in the table.
–> Here we will see this limitation and a workaround which can be used in some scenarios:
USE tempdb GO -- Create a simple table with 3 columns having 1st column to contain Unique values: CREATE TABLE dbo.TableWithCCI ( PKCol int NOT NULL, Foo int, Bar int ) GO -- Now create a "Clustered ColumnStore" index on this table: CREATE CLUSTERED COLUMNSTORE INDEX CCI_TableWithCCI ON dbo.TableWithCCI GO
Notice: While creating this index there is no provision to provided the “Clustering Key”, as this index includes all of the columns in the table, and stores the entire table by compressing the data and store by column.
On checking the metadata (by ALT+F1) of the table, you will see NULL under the index_keys column:

– Now let’s check this feature of absence of Uniquenes. We will enter 2 records with same value:
insert into dbo.TableWithCCI select 1,2,3 insert into dbo.TableWithCCI select 1,22,33 GO SELECT * FROM dbo.TableWithCCI GO
You will see 2 records with same duplicate value.
– Now, let’s create another Unique index to enforce this constraint:
CREATE UNIQUE INDEX UX_TableWithCCI ON dbo.TableWithCCI(PKCol) GO
We get an error that you cannot create more indexes if you have a Clustered ColumnStore index:
Msg 35303, Level 16, State 1, Line 25
CREATE INDEX statement failed because a nonclustered index cannot be created on a table that has a clustered columnstore index. Consider replacing the clustered columnstore index with a nonclustered columnstore index.
–> Workaround: As a workaround we can create an Indexed/Materialized View on top this table, with Clustering Key as the PK (1st column of the table/view):
CREATE VIEW dbo.vwTableWithCCI WITH SCHEMABINDING AS SELECT PKCol, Foo, Bar FROM dbo.TableWithCCI GO -- Delete duplicate records entered previously: DELETE FROM dbo.TableWithCCI GO -- Create a Unique Clustered Index on top of the View to Materialize it: CREATE UNIQUE CLUSTERED INDEX IDX_vwTableWithCCI ON dbo.vwTableWithCCI(PKCol) GO
– Now let’s try to enter duplicate records again and see if these can be entered or not:
insert into dbo.TableWithCCI select 1,2,3 insert into dbo.TableWithCCI select 1,22,33 GO
– As expected we get an error after we inserted 1st records and tried to insert the 2nd duplicate record:
(1 row(s) affected)
Msg 2601, Level 14, State 1, Line 48
Cannot insert duplicate key row in object ‘dbo.vwTableWithCCI’ with unique index ‘IDX_vwTableWithCCI’. The duplicate key value is (1).
The statement has been terminated.
–> Not sure why Microsoft has put this limitation of not maintaining the Uniqueness with these indexes. While using this workaround you need to consider this approach if possible. Like in some scenarios where the table is very big and there are frequent updates (INSERT/UPDATE/DELETES) this approach of maintaining another Indexed-View would be expensive. So this approach should be evaluated before implementing.
-- Final Cleanup: DROP VIEW dbo.vwTableWithCCI GO DROP TABLE dbo.TableWithCCI GO
I look forward in new versions of SQL Server to address this limitation.
You can also refer to MSDN BOL [here] for checking all limitations with ColumnStore Indexes.
[Update as of May-2015] with SQL Server 2016 you can make unique Clustered ColumnStore Index indirectly by creating Primary/Unique Key Constraint on a heap with a Non-Clustered Index, [check here].
Update: Know on ColumnStore Indexes as of SQL Server 2016:
Microsoft AZURE | The Cloud for Modern Business

Microsoft Azure is an Open and Flexible cloud platform that enables you to quickly Build, Deploy and Manage applications across a global network of Microsoft-managed Data-Centers. You can build applications using any language, tool or framework. And you can Integrate your public cloud applications with your existing IT environment.
–> Microsoft AZURE provides you:
1. Always up. Always on: Delivers a 99.95% monthly SLA and enables you to build and run highly available applications without focusing on the infrastructure.
2. Open: Enables you to use any language, framework, or tool to build applications. Features and services are exposed using open REST protocols.
3. Unlimited servers. Unlimited storage: Enables you to easily scale your applications to any size. It is a fully automated self-service platform that allows you to provision resources within minutes. Elastically grow or shrink your resource usage based on your needs.
4. Powerful Capabilities: Delivers a flexible cloud platform that can satisfy any application need. It enables you to reliably host and scale out your application code within compute roles.
–> Solutions Microsoft AZURE provides:
1. Virtual Machines: On-demand infrastructure that scales and adapts to your changing business needs.
2. Web: Secure and flexible development, deployment, and scaling options for any sized Web application.
3. Mobile: Fast and easy to build mobile apps that scale. Within minutes, you can store data in the cloud, authenticate users, and push notifications to millions of devices.
4. Dev & Test: Develop and test applications faster, at reduced cost, and with the flexibility to deploy in the cloud or on-premises.
5. Big Data: Reveal new insights and drive better decision making with Azure HDInsight, a Big Data solution powered by Apache Hadoop. Surface those insights from all types of data to business users through Microsoft Excel.
6. Media: Azure Media Services allows you to build scalable, cost effective, end-to-end media distribution solutions that can stream media to Adobe Flash, Android, iOS, Windows, and other devices and platforms.
7. Storage, Backup & Recovery: Scalable, durable cloud storage, backup, and recovery solutions for any data. It works with the infrastructure you already have to cost-effectively enhance your business continuity strategy and provide storage required by your cloud applications.
8. Identity & Access Management: Azure Active Directory delivers an enterprise ready cloud identity service enabling a single sign-on experience across cloud and on-premises applications. It allows multi-factor authentication for added security and compliance.
–> Current AZURE footprint:

–> For more information please visit Microsoft AZURE:
– Official Site: http://azure.microsoft.com/en-us/
– Official Blog: http://azure.microsoft.com/blog/
Book Review – Getting Started with SQL Server 2014 Administration
I started working on SQL Server with version 2000 (back in yr2005), then upgraded to 2005 (in yr2008), skipped 2008 version, jumped to 2008 R2 (in yr2011), then 2012 (in yr2012) and now finally 2014 very recently.
Now “SQL Server 2014” looks very competitive if you compare it with other vendors in terms of DB Engine, BI Suite, Administration, Cloud Computing, and the latest In-Memory processing, all bundled in a single suit.
–> SQL Server 2014 is packed with new and robust features like:
1. In-Memory OLTP
2. Updatable ColumnStore Indexes for Data Warehouse
3. Enhanced AlwaysOn, Azure VMs for Availability replicas
4. Managed Backup to Azure
5. SQL Server Data Files in Azure
6. Encrypted Backups
7. Delayed durability
8. Buffer Pool Extension (with SSD)
9. Incremental Stats
“Getting Started with SQL Server 2014 Administration” book is authorized by Gethyn Ellis {B|L|T} and covers most of these features in Detail and in simple steps. I’ve also talked about some of these features on my previous blog post [link], and will be writing in future also.

–> The book contains following chapters:
Chapter 1: SQL Server 2014 and Cloud
Chapter 2: Backup and Restore Improvements
Chapter 3: In-Memory Optimized Tables
Chapter 4: Delayed Durability
Chapter 5: AlwaysOn Availability Groups
Chapter 6: Performance Improvements
The book starts (Chapter-1) by giving an introduction to the Cloud and how Microsoft Azure SQL Database enables your SQL Server database on Cloud in easy & graphical steps, which includes:
1.1. Creating Azure SQL DB
1.2. Integrating Azure Stirage
1.3. Creating Azure VMs
On Chapter-2 its talks about Backup & Restore improvements in 2014, which includes:
2.1. Database backups/restore to a URL and Azure Storage
2.2. SQL Server Managed Backup to Microsoft Azure
2.3. Encrypted Backups
Chapter-3 tells you about new In-Memory functionality by creating:
3.1. In-Memory Tables & Indexes
3.2. Native compiled Stored Procedures
Chapter-4 discuss about Delayed Durability and how it can help improve performance by using in-memory transaction log feature, which delays writing transaction log entries to disk.
Chapter-5 talks about enhancements to AlwaysOn Availability Groups and following:
5.1. Using Microsoft Azure Virtual Machines as replicas
5.2. Building AlwaysOn Availability Groups
5.3. Creating/Troubleshooting Availability Group
Last Chapter-6 talks about lot of improvements in Performance, which includes:
6.1. Partition switching and indexing, now it is possible for individual partitions of partitioned tables to be rebuilt.
6.2. Updatable and new Clustered ColumnStore Indexes.
6.3. Buffer pool extensions, will allow you to make use of SSD (Solid-State Drives) as extra RAM on your DB server, thus by providing an extension to the Database Engine buffer pool, which can significantly improve the I/O throughput.
6.4. New Cardinality estimator and better query plans.
6.5. Update Statistics incrementally instead of a full Scan.
PROS: The book covers most of the new features in SQL Server 2014, so it is good for DBAs and Developers who already have prior experience in SQL Server 2012 Admin and Dev. Overall a good book which gives good insights into SQL Server 2014, Azure and new features.
CONS: Not on negative side, but for newbies and junior DBAs I would suggest to get hold of some basic DBA book and stuff first then graduate to this book.
Download/Buy book Here [Packt Publishing].


![]()
Current Visitors

StatCounter …since April 2012

 Leisure blog: Creek & Trails
Leisure blog: Creek & Trails
- NMDC Hyderabad Marathon – My first 42k FM, cramps, training and fuelling
- Singapore (Part 2) – 6 days itinerary, sightseeing & attractions
- Singapore (Part 1) – Tickets, Visa, Hotel, Forex Card/Cash, Metro/Bus cards
- I got full refund of my flight tickets during COVID lockdown (AirIndia via MakeMyTrip)
- YouTube – Your Google Ads account was cancelled due to no spend
- YouTube latest update on its YPP (YouTube Partner Program) which may affect your channel
- Starting your own blog !!!
- How to file ITR (Income Tax Return) online AY 2017-18 (for simple salaried)
- Scam – Become a kin/hier and earn a fortune – via LinkedIn and Email
- Places to visit in and around Vizag (aka Visakhapatnam)
