Archive
2018 blogging in review (Happy New Year – 2019 !!!)
Happy New Year 2019… from SQL with Manoj !!!
As WordPress.com stats helper monkeys have stopped preparing annual report for any of their blogs, so I’ve prepared my own Annual Report for this year again.
–> Here are some Crunchy numbers from 2018

SQL with Manoj 2018 Stats
The Louvre Museum has 8.5 million visitors per year. This blog was viewed about 793,171 times by 542,918 unique visitors in 2018. If it were an exhibit at the Louvre Museum, it would take about 17 days for that many people to see it.
There were 68 pictures uploaded, taking up a total of ~6 MB. That’s about ~6 pictures every month.
This blog also got its highest ever hits/views per day (i.e. 3,552 hits) on Sept 25th this year.
–> All-time posts, views, and visitors
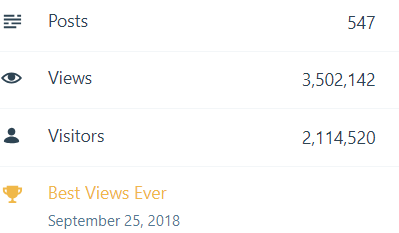
SQL with Manoj all time views
–> Posting Patterns
In 2018, there were 26 new posts, growing the total archive of this blog to 546 posts.
LONGEST STREAK: 6 post in Feb 2018
–> Attractions in 2018
These are the top 5 posts that got most views in 2018:
1. Download & Install SQL Server Management Studio (SSMS) 2016 (62,101 views)
2. SQL Server 2016 RTM full & final version available – Download now (31,705 views)
3. Getting started with SQL Server 2014 | Download and Install Free & Full version (20,443 views)
4. SQL Basics – Difference b/w WHERE, GROUP BY and HAVING clause (16,113 views)
5. SQL Basics – Difference b/w TRUNCATE, DELETE and DROP? (13,189 views)
–> How did they find me?
The top referring sites and search engines in 2018 were:
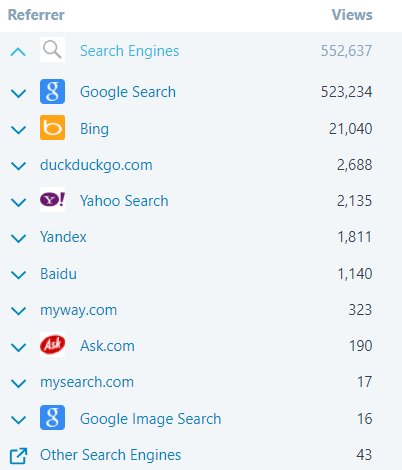
SQL with Manoj 2018 Search Engines referrers
–> Where did they come from?
Out of 210 countries, top 5 visitors came from India, United States, United Kingdom, Canada and Australia:
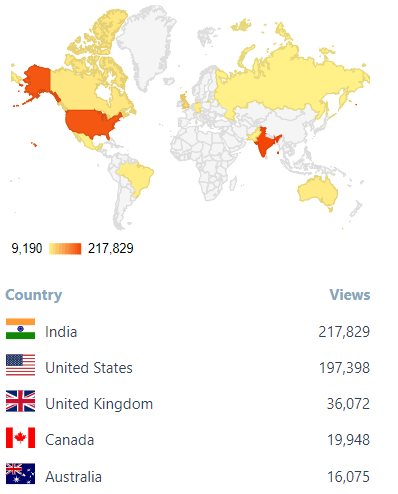
SQL with Manoj 2018 top Countries visitors
–> Followers: 407
WordPress.com: 160
Email: 247
Facebook Page: 1,358
–> Alexa Rank (lower the better)
Global Rank: 221,534
US Rank: 139,012
India Rank: 46,758
Estimated Monthly Revenue: $1,320
Actual Monthly Revenue: $300

SQL with Manoj 2018 Alexa ranking
Alexa history shows how the alexa rank of sqlwithmanoj.com has varied in the past, which in turn also tells about the site visitors.
–> 2019 New Year Resolution
– Write at least 1 blog post every week
– Write on new feaures in SQL Server 2017 & 2019
– Also explore and write blog post on Azure Data Platform
– Post at least 1 video every week on my YouTube channel
That’s all for 2018, see you in year 2019, all the best !!!
Connect me on Facebook, Twitter, LinkedIn, YouTube, Google, Email
Hadoop/HDFS storage types, formats and internals – Text, Parquet, ORC, Avro
HDFS or Hadoop Distributed File System is the distributed file system provided by the Hadoop Big Data platform. The primary objective of HDFS is to store data reliably even in the presence of node failures in the cluster. This is facilitated with the help of data replication across different racks in the cluster infrastructure. These files stored in HDFS system are used for further data processing by different data processing engines like Hadoop Map-Reduce, Hive, Spark, Impala, Pig etc.
–> Here we will talk about different types of file formats supported in HDFS:
1. Text (CSV, TSV, JSON): These are the flat file format which could be used with the Hadoop system as a storage format. However these format do not contain the self inherited Schema. Thus with this the developer using any processing engine have to apply schema while reading these file formats.
2. Parquet: file format is the Columnar oriented format in the Hadoop ecosystem. Parquet stores the binary data column wise, which brings following benefits:
– Less storage, efficient Compression resulting in Storage optimization, as the same data type is residing adjacent to each other. That helps in compressing the data better hence provide storage optimization.
– Increased query performance as entire row needs not to be loaded in the memory.
Parquet file format can be used with any Hadoop ecosystem like: Hive, Impala, Pig, Spark, etc.
3. ORC: stands for Optimized Row Columnar, which is a Columnar oriented storage format. ORC is primarily used in the Hive world and gives better performance with Hive based data retrievals because Hive has a vectorized ORC reader. Schema is self contained in the file as part of the footer. Because of the column oriented nature it provide better compression ratio and faster reads.
4. Avro: is the Row oriented storage format, and make a perfect use case for write heavy applications. The schema is self contained with in the file in the form of JSON, which help in achieving efficient schema evolution.
–> Now, Lets take a deep dive and look at these file format through a series of videos below:
Author/Speaker Bio: Viresh Kumar is a v-blogger and an expert in Big Data, Hadoop and Cloud world. He has an experience of ~14 years in the Data Platform industry.
Book: Hadoop – The Definitive Guide: Storage and Analysis at Internet Scale


![]()
Current Visitors

StatCounter …since April 2012

 Leisure blog: Creek & Trails
Leisure blog: Creek & Trails
- NMDC Hyderabad Marathon – My first 42k FM, cramps, training and fuelling
- Singapore (Part 2) – 6 days itinerary, sightseeing & attractions
- Singapore (Part 1) – Tickets, Visa, Hotel, Forex Card/Cash, Metro/Bus cards
- I got full refund of my flight tickets during COVID lockdown (AirIndia via MakeMyTrip)
- YouTube – Your Google Ads account was cancelled due to no spend
- YouTube latest update on its YPP (YouTube Partner Program) which may affect your channel
- Starting your own blog !!!
- How to file ITR (Income Tax Return) online AY 2017-18 (for simple salaried)
- Scam – Become a kin/hier and earn a fortune – via LinkedIn and Email
- Places to visit in and around Vizag (aka Visakhapatnam)
