Archive
XTP (eXtreme Transaction Processing) with Hekaton Tables & Native Compiled Stored Procedures – SQL Server 2014
In my previous posts [this & this] I talked about creating Memory Optimized Database, how to create In-Memory Tables & Native Compiled Stored Procedures and what happens when they are created.
Here in this post we will see how FAST actually In-Memory tables & Native Compiled Stored Procedures are, when compared with normal Disk based Tables & Simple Stored Procedures.
I’ll be using the same [ManTest] database used in my previous posts, you can refer to the DDL script [here].
–> We will create:
1. One Disk based Table & one simple Stored Procedure which will use this Disk based Table.
2. One In-Memory Table & one Native Compiled Stored Procedure which will use this In-Memory Table.
1. Let’s first create a Disk based Table and a normal Stored Procedure:
USE [ManTest]
GO
-- Create a Disk table (non-Memory Optimized):
CREATE TABLE dbo.DiskTable
(
ID INT NOT NULL
PRIMARY KEY,
VarString VARCHAR(200) NOT NULL,
DateAdded DATETIME NOT NULL
)
GO
-- Create normal Stored Procedure to load data into above Table:
CREATE PROCEDURE dbo.spLoadDiskTable @maxRows INT, @VarString VARCHAR(200)
AS
BEGIN
SET NOCOUNT ON
DECLARE @i INT = 1
WHILE @i <= @maxRows
BEGIN
INSERT INTO dbo.DiskTable VALUES(@i, @VarString, GETDATE())
SET @i = @i+1
END
END
GO
2. Now create an In-Memory table & a Native Compiled Stored Procedure to load data:
-- Create an In-Memory table:
CREATE TABLE dbo.MemOptTable
(
ID INT NOT NULL
PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 10000),
VarString VARCHAR(200) NOT NULL,
DateAdded DATETIME NOT NULL
) WITH (
MEMORY_OPTIMIZED = ON,
DURABILITY = SCHEMA_AND_DATA
)
GO
-- Create Native Compiled Stored Procedure to load data into above Table:
CREATE PROCEDURE dbo.spLoadMemOptTable @maxRows INT, @VarString VARCHAR(200)
WITH
NATIVE_COMPILATION,
SCHEMABINDING,
EXECUTE AS OWNER
AS
BEGIN ATOMIC
WITH (TRANSACTION ISOLATION LEVEL=SNAPSHOT, LANGUAGE='us_english')
DECLARE @i INT = 1
WHILE @i <= @maxRows
BEGIN
INSERT INTO dbo.MemOptTable VALUES(@i, @VarString, GETDATE())
SET @i = @i+1
END
END
GO
–> Now we will try to Load 10k record in above 2 table in various ways, as follows:
1. Load Disk based Table by T-SQL script using a WHILE loop.
2. Load the same Disk based Table by Stored Procedure which internally uses a WHILE loop.
3. Load In-Memory Table by T-SQL script using a WHILE loop.
4. Load the same In-Memory Table by Native Compiled Stored Procedure which internally uses a WHILE loop.
–> Working with Disk based Tables:
SET NOCOUNT ON
DECLARE
@StartTime DATETIME2,
@TotalTime INT
DECLARE
@i INT,
@maxRows INT,
@VarString VARCHAR(200)
SET @maxRows = 10000
SET @VarString = REPLICATE('a',200)
SET @StartTime = SYSDATETIME()
SET @i = 1
-- 1. Load Disk Table (without SP):
WHILE @i <= @maxRows
BEGIN
INSERT INTO dbo.DiskTable VALUES(@i, @VarString, GETDATE())
SET @i = @i+1
END
SET @TotalTime = DATEDIFF(ms,@StartTime,SYSDATETIME())
SELECT 'Disk Table Load: ' + CAST(@TotalTime AS VARCHAR) + ' ms (without SP)'
-- 2. Load Disk Table (with simple SP):
DELETE FROM dbo.DiskTable
SET @StartTime = SYSDATETIME()
EXEC spLoadDiskTable @maxRows, @VarString
SET @TotalTime = DATEDIFF(ms,@StartTime,SYSDATETIME())
SELECT 'Disk Table Load: ' + CAST(@TotalTime AS VARCHAR) + ' ms (with simple SP)'
–> Working with In-Memory Tables:
-- 3. Load Memory Optimized Table (without SP): SET @StartTime = SYSDATETIME() SET @i = 1 WHILE @i <= @maxRows BEGIN INSERT INTO dbo.MemOptTable VALUES(@i, @VarString, GETDATE()) SET @i = @i+1 END SET @TotalTime = DATEDIFF(ms,@StartTime,SYSDATETIME()) SELECT 'Memory Table Load: ' + CAST(@TotalTime AS VARCHAR) + ' ms (without SP)' -- 4. Load Memory Optimized Table (with Native Compiled SP): DELETE FROM dbo.MemOptTable SET @StartTime = SYSDATETIME() EXEC spLoadMemOptTable @maxRows, @VarString SET @TotalTime = DATEDIFF(ms,@StartTime,SYSDATETIME()) SELECT 'Disk Table Load: ' + CAST(@TotalTime AS VARCHAR) + ' ms (with Native Compiled SP)' GO
–> Output (Loaded 10k records):
Disk based Table Load : 28382 ms (without SP) Disk based Table SP Load : 8297 ms (with simple SP) In-Memory Table Load : 5176 ms (without SP) In-Memory Table SP Load : 174 ms (with Native Compiled SP)
So, you can clearly see the benefit and multifold increase in performance by using In-Memory Tables & Native Compiled Stored Procedures. The graph below shows performance in visual bar charts, impressive, isn’t it?

–> Final Cleanup
DROP PROCEDURE dbo.spLoadDiskTable DROP TABLE dbo.DiskTable DROP PROCEDURE dbo.spLoadMemOptTable DROP TABLE dbo.MemOptTable GO
Update: Know more about In-Memory tables:
Clustered Index do “NOT” guarantee Physically Ordering or Sorting of Rows
Myth: Lot of SQL Developers I’ve worked with and interviewed have this misconception, that Clustered Indexes are Physically Sorted and Non-Clustered Index are Logically Sorted. When I ask them reasons, all come with their own different versions.
I discussed about this in my previous post long time back, where I mentioned as per the MSDN that “Clustered Indexes do not guarantee Physical Ordering of rows in a Table”. And today in this post I’m going to provide an example to prove it.
Clustered Index is the table itself as its Leaf-Nodes contains the Data-Pages of the table. The Data-Pages are nothing but Doubly Linked-List Data-Structures linked to their leading & preceding Data-Pages. The Data-Pages and rows in them are Ordered by the Clustering Key. Thus there can be only one Clustered Index on a table.
When a new Clustered Index is created on a table, it reorganizes the table’s Data-Pages Physically so that the rows are Logically sorted. But when a tables goes through updates, like INSERT/UPDATE/DELETE operations then the index gets fragmented and thus the Physical Ordering of Data-Pages gets lost. But still the Data-Pages of the Clustered Index or the Table are chained together by Doubly Linked-List in Logical Order.
We will see this behavior in the following example:
USE AdventureWorks2012
GO
CREATE TABLE test (i INT PRIMARY KEY not null, j VARCHAR(2000))
INSERT INTO test (i,j)
SELECT 1, REPLICATE('a',100) UNION ALL
SELECT 2, REPLICATE('a',100) UNION ALL
SELECT 3, REPLICATE('a',100) UNION ALL
SELECT 5, REPLICATE('a',100) UNION ALL
SELECT 6, REPLICATE('a',100)
SELECT * FROM test
DBCC IND(AdventureWorks2012, 'test', -1);
DBCC TRACEON(3604);
DBCC PAGE (AdventureWorks2012, 1, 22517, 1);
As you can see above we inserted 5 records in a table having PK as Clustering Key with following values: 1,2,3,5,6. We skipped the value 4.
–> Here is the Output of DBCC PAGE command execute in the end:
The DBCC PAGE provides very descriptive Output, but here I’ve just extracted the useful information we need.
OFFSET TABLE: Row - Offset 4 (0x4) - 556 (0x22c) --> 1=6 3 (0x3) - 441 (0x1b9) --> 1=5 2 (0x2) - 326 (0x146) --> 1=3 1 (0x1) - 211 (0xd3) --> 1=2 0 (0x0) - 96 (0x60) --> 1=1
It show the 5 rows with their memory allocated address in both decimal and hexadecimal formats, which is contiguous. Thus all the rows are Physically Ordered.
Now, let’s insert the value “4” that we skipped initially:
INSERT INTO test (i,j)
SELECT 4, REPLICATE('a',100)
SELECT * FROM test
DBCC IND(AdventureWorks2012, 'test', -1);
DBCC TRACEON(3604);
DBCC PAGE (AdventureWorks2012, 1, 22517, 1);
–> Here is the new Output of DBCC PAGE command execute in the end:
OFFSET TABLE: Row - Offset 5 (0x5) - 556 (0x22c) --> 1=6 4 (0x4) - 441 (0x1b9) --> 1=5 3 (0x3) - 671 (0x29f) --> 1=4 <-- new row added here 2 (0x2) - 326 (0x146) --> 1=3 1 (0x1) - 211 (0xd3) --> 1=2 0 (0x0) - 96 (0x60) --> 1=1
As you can see very clearly in the output above that the memory allocation address for the new row with PK value = “4” is 671, which is not in between and greater than the address of the last row i.e. 556. The memory address of the last 2 rows is unchanged (441 & 556) and the new row is not accommodated in between as per the sort order but at the end. There is no Physical Ordering and the new row is Logically Chained with other rows and thus is Logically and Ordered, similar to the image below:
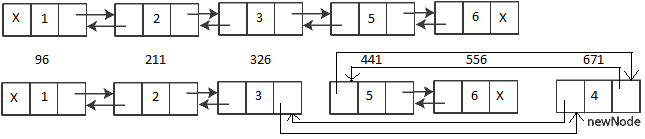
Myth Busted: Hope the above exercise clears that Clustered Indexes do not guarantee the Physical Ordering of Rows & Data Pages.
-- Final Cleanup DROP TABLE test
SET STATISTICS IO and TIME – What are Logical, Physical and Read-Ahead Reads?
In my previous post [link] I talked about SET STATISTICS IO and Scan Count.
Here in this post I will go ahead and talk about Page Reads, i.e Logical Reads and Physical Reads.
–> Type of Reads and their meaning:
– Logical Reads: are the number of 8k Pages read from the Data Cache. These Pages are placed in Data Cache by Physical Reads or Read-Ahead Reads.
– Physical Reads: are the Number of 8k Pages read from the Disk if they are not in Data Cache. Once in Data Cache they (Pages) are read by Logical Reads and Physical Reads do not (or minimally) happen for same set of queries.
– Read-Ahead Reads: are the number of 8k Pages pre-read from the Disk and placed into the Data Cache. These are a kind of advance Physical Reads, as they bring the Pages in advance to the Data Cache where the need for Data/Index pages in anticipated by the query.
–> Let’s go by some T-SQL Code examples to make it more simple to understand:
USE [AdventureWorks2012] GO -- We will crate a new table here and populate records from AdventureWorks's Person.Person table: SELECT BusinessEntityID, Title, FirstName, MiddleName, LastName, Suffix, EmailPromotion, ModifiedDate INTO dbo.Person FROM [Person].[Person] GO -- Let's Clear up the Data Cache or memory-buffer: DBCC FREEPROCCACHE DBCC DROPCLEANBUFFERS GO -- Run the following block of T-SQL statements: SET STATISTICS IO ON SET STATISTICS TIME ON SELECT * FROM dbo.Person SELECT * FROM dbo.Person SET STATISTICS IO OFF SET STATISTICS TIME OFF GO
Output Message: (19972 row(s) affected) Table 'Person'. Scan count 1, logical reads 148, physical reads 0, read-ahead reads 148, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 31 ms, elapsed time = 297 ms. (19972 row(s) affected) Table 'Person'. Scan count 1, logical reads 148, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 16 ms, elapsed time = 186ms.
The Output Message above shows different number of Reads for both the queries when ran twice.
– On first execution of the Query, the Data Cache was empty so the query had to do a Physical Read. But as the optimizer already knows that all records needs to be fetched, so by the time query plan is created the DB Engine pre-fetches all records into memory by doing Read-Ahead Read operation. Thus, here we can see zero Physical Reads and 148 Read-Ahead Reads. After records comes into Data Cache, the DB Engine pulls the Records from Logical Reads operation, which is again 148.
– On second execution of the Query, the Data Cache is already populated with the Data Pages so there is no need to do Physical Reads or Read-Ahead Reads. Thus, here we can see zero Physical & Read-Ahead Reads. As the records are already in Data Cache, the DB Engine pulls the Records from Logical Reads operation, which is same as before 148.
Note: You can also see the performance gain by Data Caching, as the CPU Time has gone down to 16ms from 31ms and Elapsed Time to 186ms from 297ms.
–> At our Database end we can check how many Pages are in the Disk for the Table [dbo].[Person].
Running below DBCC IND statement will pull number of records equal to number of Pages it Cached above, i.e. 148:
DBCC IND('AdventureWorks2012','Person',-1)
GO
The above statement pulls up 149 records, 1st record is the IAM Page and rest 148 are the Data Pages of the Table that were Cached into the buffer pool.
–> We can also check at the Data-Cache end how many 8k Pages are in the Data-Cache, before-Caching and after-Caching:
-- Let's Clear up the Data Cache again: DBCC FREEPROCCACHE DBCC DROPCLEANBUFFERS GO -- Run this DMV Query, this time it will run on Cold Cache, and will return information from the pre-Cache'd data: ;WITH s_obj as ( SELECT OBJECT_NAME(OBJECT_ID) AS name, index_id ,allocation_unit_id, OBJECT_ID FROM sys.allocation_units AS au INNER JOIN sys.partitions AS p ON au.container_id = p.hobt_id AND (au.type = 1 OR au.type = 3) UNION ALL SELECT OBJECT_NAME(OBJECT_ID) AS name, index_id, allocation_unit_id, OBJECT_ID FROM sys.allocation_units AS au INNER JOIN sys.partitions AS p ON au.container_id = p.partition_id AND au.type = 2 ), obj as ( SELECT s_obj.name, s_obj.index_id, s_obj.allocation_unit_id, s_obj.OBJECT_ID, i.name IndexName, i.type_desc IndexTypeDesc FROM s_obj INNER JOIN sys.indexes i ON i.index_id = s_obj.index_id AND i.OBJECT_ID = s_obj.OBJECT_ID ) SELECT COUNT(*) AS cached_pages_count, obj.name AS BaseTableName, IndexName, IndexTypeDesc FROM sys.dm_os_buffer_descriptors AS bd INNER JOIN obj ON bd.allocation_unit_id = obj.allocation_unit_id INNER JOIN sys.tables t ON t.object_id = obj.OBJECT_ID WHERE database_id = DB_ID() AND obj.name = 'Person' AND schema_name(t.schema_id) = 'dbo' GROUP BY obj.name, index_id, IndexName, IndexTypeDesc ORDER BY cached_pages_count DESC; -- Run following Query, this will populate the Data Cache: SELECT * FROM dbo.Person -- Now run the previous DMV Query again, this time it will run on Cache'd Data and will return information of the Cache'd Pages:
Query Output: -> First DMV Query Run: cached_pages_count BaseTableName IndexName IndexTypeDesc 2 Person NULL HEAP -> Second DMV Query Run: cached_pages_count BaseTableName IndexName IndexTypeDesc 150 Person NULL HEAP
So, by checking the above Output you can clearly see that only 2 Pages were there before-Caching.
And after executing the Query on table [dbo].[Person] the Data Pages got Cache’d into the buffer pool. And on running the same DMV query again you get the number of Cache’d Pages in the Data Cache, i.e same 148 Pages (150-2).
-- Final Cleanup DROP TABLE dbo.Person GO
>> Check & Subscribe my [YouTube videos] on SQL Server.
SET STATISTICS IO – What is Scan count?
SET STATISTICS IO is a typical command which lets Database users to display information regarding the amount of disk activity generated by the Transact-SQL statements.
This command can be set to either ON or OFF.
Switching it to “ON”, it displays the stats of activity done by the SQL Server engine, like Scan Counts and number of Page Reads (Logical/Physical).
Let’s see here what does Scan Count exactly means in the information it provides:
As per MS BOL Scan Count is the:
Number of seeks/scans started after reaching the leaf level in any direction to retrieve all the values to construct the final dataset for the output.
– Scan count is 0 if the index used is a unique index or clustered index on a primary key and you are seeking for only one value. For example WHERE Primary_Key_Column = .
– Scant count is 1 when you are searching for one value using a non-unique clustered index which is defined on a non-primary key column. This is done to check for duplicate values for the key value that you are searching for. For example WHERE Clustered_Index_Key_Column = .
– Scan count is N when N is the number of different seek/scan started towards the left or right side at the leaf level after locating a key value using the index key.
Here we will see in what scenarios we will see different “Scan Counts”:
–> Execute below scripts as-is to see what they do:
USE [AdventureWorks2012] GO -- Insert some records into a new table from AdventureWorks's Person.Person table: SELECT TOP 5000 BusinessEntityID, Title, FirstName, MiddleName, LastName, Suffix, EmailPromotion, ModifiedDate INTO dbo.Person FROM [Person].[Person] GO -- Let's Clear the Cache: DBCC FREEPROCCACHE DBCC DROPCLEANBUFFERS GO -- Executing 3 different T-SQL statements to see what stats-information they provide: SET STATISTICS IO ON SELECT * FROM dbo.Person SELECT * FROM dbo.Person WHERE BusinessEntityID = 1 SELECT * FROM dbo.Person WHERE BusinessEntityID IN (1,2) SET STATISTICS IO OFF GO
Output Message: (5000 row(s) affected) Table 'Person'. Scan count 1, logical reads 38, physical reads 0, read-ahead reads 38, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. (1 row(s) affected) Table 'Person'. Scan count 1, logical reads 38, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. (2 row(s) affected) Table 'Person'. Scan count 1, logical reads 38, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
In the above Output window we can see that Scan Count = 1 in all the three queries.
This is because the table does not have an index and it does a single full Table-Scan for every query above.
The Execution plan below shows that all 3 queries are doing full Table-Scan.

–> Now let’s create a Unique Clustered Index on the table and see what “Scan Count” it gives on the same set of queries:
-- Create a Unique Clustered Index on the table: CREATE UNIQUE CLUSTERED INDEX C_IX ON dbo.Person(BusinessEntityID) GO -- Let's Clear the Cache again: DBCC FREEPROCCACHE DBCC DROPCLEANBUFFERS GO -- Execute below statements and see what Output-Message it gives: SET STATISTICS IO ON SELECT * FROM dbo.Person SELECT * FROM dbo.Person WHERE BusinessEntityID = 1 SELECT * FROM dbo.Person WHERE BusinessEntityID IN (1,2) SET STATISTICS IO OFF
Output Message: (5000 row(s) affected) Table 'Person'. Scan count 1, logical reads 44, physical reads 0, read-ahead reads 35, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. (1 row(s) affected) Table 'Person'. Scan count 0, logical reads 2, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. (2 row(s) affected) Table 'Person'. Scan count 2, logical reads 4, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
In the above Output window we can see a difference in Scan Count in all 3 queries.
1. First Query shows Scan Count = 1 as there is a Index but to return all rows it has to Scan the whole Index.
2. Second Query shows Scan Count = 0 as it uses the Index, but does a Index-Seek instead of Scan and Optimizer knows that there is only 1 value for BusinessEntityID = 1.
3. Third Query shows Scan Count = 2 as it also uses the Index, but it does a ORDERED FORWARD seek as it is looking for 2 different values, i.e. BusinessEntityID = 1 and 2.
Note: You will also see a reduction in number of Reads for the 2nd & 3rd queries, as it is utilizing the Index we created on the table, thus optimizing the performance.
Query plan for 3rd query:
|--Clustered Index Seek(OBJECT:([AdventureWorks2012].[dbo].[Person].[C_IX]),
SEEK:([AdventureWorks2012].[dbo].[Person].[BusinessEntityID]=(1) OR
[AdventureWorks2012].[dbo].[Person].[BusinessEntityID]=(2))
ORDERED FORWARD)
The Execution plan below shows very clearly how the above 3-queries are using Index:

–> Let’s see what count it gives for T-SQL statement with 5 values:
SET STATISTICS IO ON SELECT * FROM dbo.Person WHERE BusinessEntityID IN (1,2,3,4,5) SET STATISTICS IO OFF
(5 row(s) affected) Table 'Person'. Scan count 5, logical reads 10, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Here, we can see the Scan Count = 5 for the above query and reason is obvious. It is doing 5 ORDERED FORWARD Seeks to retrieve the 5 unique values.
-- Final Cleanup: DROP TABLE dbo.Person
Check more on MSDN about SET STATISTICS IO : http://msdn.microsoft.com/en-us/library/ms184361.aspx
SQL Server 2012 (a.k.a. Denali) – Best Practices Analyzer
Microsoft SQL Server 2012 released its Best Practices Analyzer (BPA) on 1st week of April and is available free for download at following [link].
-> Overview …as mentioned in the link
BPA is a diagnostic tool that performs the following functions:
1. Gathers information about a Server and a Microsoft SQL Server 2012 instance installed on that Server.
2. Determines if the configurations are set according to the recommended best practices.
3. Reports on all configurations, indicating settings that differ from recommendations.
4. Indicates potential problems in the installed instance of SQL Server.
5. Recommends solutions to potential problems.
-> System Requirements to install
– PowerShell V2.0
– Microsoft Baseline Configuration Analyzer V2.0
The download link also provides information about:
– Installation Instructions.
– And some Additional Information about its capabilities.
… stay tuned for more updates about SQL Server 2012.


![]()
Current Visitors

StatCounter …since April 2012

 Leisure blog: Creek & Trails
Leisure blog: Creek & Trails
- NMDC Hyderabad Marathon – My first 42k FM, cramps, training and fuelling
- Singapore (Part 2) – 6 days itinerary, sightseeing & attractions
- Singapore (Part 1) – Tickets, Visa, Hotel, Forex Card/Cash, Metro/Bus cards
- I got full refund of my flight tickets during COVID lockdown (AirIndia via MakeMyTrip)
- YouTube – Your Google Ads account was cancelled due to no spend
- YouTube latest update on its YPP (YouTube Partner Program) which may affect your channel
- Starting your own blog !!!
- How to file ITR (Income Tax Return) online AY 2017-18 (for simple salaried)
- Scam – Become a kin/hier and earn a fortune – via LinkedIn and Email
- Places to visit in and around Vizag (aka Visakhapatnam)
