Columnstore Indexes in SQL Server 2012
This time the new version of SQL Server 2012 a.k.a Denali has introduced a new kind of index i.e. ColumnStore Index, which is very different from the traditional indexes. This new index differs in the way it is created, stores its table contents in specific format and provides fast retrieval of data from the new storage.
–> Before talking about ColumnStore Index, let’s first check and understand what is a ColumnStore?
ColumnStore is a data storage method that uses xVelocity technology based upon Vertipaq engine, which uses a new Columnar storage technique to store data that is highly Compressed and is capable of In-memory Caching and highly parallel data scanning with Aggregation algorithms.
Traditionally, on the other side a RowStore is the traditional and by-default way to store data for each row and then joins all the rows and store them in Data Pages, and is still the same storage mechanism for Heap and Clustered Indexes.
The ColumnStore or Columnar data format does not store data in traditional RowStore fashion, instead the data is grouped and stored as one column at a time in Column Segments.
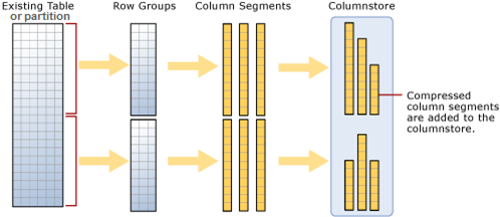
–> Here is what happens when you try to create a ColumnStore Index on a table:
1. Existing table rows are divided into multiple RowGroups, a Row-Group can contain upto 1 million rows.
2. Each column of a RowGroup is stored in its own Segment and is compressed.
3. The individual compressed Column Segments are added to the ColumnStore.
4. When new rows are inserted or existing ones are updated (in small batches, except BulkLoad) they are added to a separate Delta Store, upto a threshold of 1 million rows.
5. When a Delta-Store reaches its threshold of 1 million rows a separate process Tuple-mover invokes and closes the delta-store, compresses it & stores it into the ColumnStore index.
–> Thus, Columnstore indexes can produce faster results by doing less I/O operations by following:
1. Reading only the required columns, thus less data is read from disk to memory.
2. Heavy Column compression, which reduces the number of bytes that must be read and moved.
3. Advanced query execution technology by processing chunks of columns called batches (1000 rows) in a streamlined manner, further reducing CPU usage.
4. Stored as ColumnStore Object Pool in RAM to cache ColumnStore Index, instead of SQL Buffer Pool (for Pages)
–> Please Note: In SQL Server 2012 ColumnStore indexes has some limitations:
1. A Table (Heap or BTree) can have only one NonClustered ColumnStore Index.
2. Cannot be a Clustered Index.
3. A Table with NonClustered ColumnStore Index becomes readonly and cannot be updated.
4. Check MSDN BoL for more limitations with SQL Server 2012 version, link.
-
December 21, 2017 at 7:00 amSQL Server 2017 – ColumnStore Index enhancements and improvements over previous versions | SQL with Manoj


![]()
Current Visitors

StatCounter …since April 2012

 Leisure blog: Creek & Trails
Leisure blog: Creek & Trails
- NMDC Hyderabad Marathon – My first 42k FM, cramps, training and fuelling
- Singapore (Part 2) – 6 days itinerary, sightseeing & attractions
- Singapore (Part 1) – Tickets, Visa, Hotel, Forex Card/Cash, Metro/Bus cards
- I got full refund of my flight tickets during COVID lockdown (AirIndia via MakeMyTrip)
- YouTube – Your Google Ads account was cancelled due to no spend
- YouTube latest update on its YPP (YouTube Partner Program) which may affect your channel
- Starting your own blog !!!
- How to file ITR (Income Tax Return) online AY 2017-18 (for simple salaried)
- Scam – Become a kin/hier and earn a fortune – via LinkedIn and Email
- Places to visit in and around Vizag (aka Visakhapatnam)
