Archive
Book Review – Getting Started with SQL Server 2014 Administration
I started working on SQL Server with version 2000 (back in yr2005), then upgraded to 2005 (in yr2008), skipped 2008 version, jumped to 2008 R2 (in yr2011), then 2012 (in yr2012) and now finally 2014 very recently.
Now “SQL Server 2014” looks very competitive if you compare it with other vendors in terms of DB Engine, BI Suite, Administration, Cloud Computing, and the latest In-Memory processing, all bundled in a single suit.
–> SQL Server 2014 is packed with new and robust features like:
1. In-Memory OLTP
2. Updatable ColumnStore Indexes for Data Warehouse
3. Enhanced AlwaysOn, Azure VMs for Availability replicas
4. Managed Backup to Azure
5. SQL Server Data Files in Azure
6. Encrypted Backups
7. Delayed durability
8. Buffer Pool Extension (with SSD)
9. Incremental Stats
“Getting Started with SQL Server 2014 Administration” book is authorized by Gethyn Ellis {B|L|T} and covers most of these features in Detail and in simple steps. I’ve also talked about some of these features on my previous blog post [link], and will be writing in future also.

–> The book contains following chapters:
Chapter 1: SQL Server 2014 and Cloud
Chapter 2: Backup and Restore Improvements
Chapter 3: In-Memory Optimized Tables
Chapter 4: Delayed Durability
Chapter 5: AlwaysOn Availability Groups
Chapter 6: Performance Improvements
The book starts (Chapter-1) by giving an introduction to the Cloud and how Microsoft Azure SQL Database enables your SQL Server database on Cloud in easy & graphical steps, which includes:
1.1. Creating Azure SQL DB
1.2. Integrating Azure Stirage
1.3. Creating Azure VMs
On Chapter-2 its talks about Backup & Restore improvements in 2014, which includes:
2.1. Database backups/restore to a URL and Azure Storage
2.2. SQL Server Managed Backup to Microsoft Azure
2.3. Encrypted Backups
Chapter-3 tells you about new In-Memory functionality by creating:
3.1. In-Memory Tables & Indexes
3.2. Native compiled Stored Procedures
Chapter-4 discuss about Delayed Durability and how it can help improve performance by using in-memory transaction log feature, which delays writing transaction log entries to disk.
Chapter-5 talks about enhancements to AlwaysOn Availability Groups and following:
5.1. Using Microsoft Azure Virtual Machines as replicas
5.2. Building AlwaysOn Availability Groups
5.3. Creating/Troubleshooting Availability Group
Last Chapter-6 talks about lot of improvements in Performance, which includes:
6.1. Partition switching and indexing, now it is possible for individual partitions of partitioned tables to be rebuilt.
6.2. Updatable and new Clustered ColumnStore Indexes.
6.3. Buffer pool extensions, will allow you to make use of SSD (Solid-State Drives) as extra RAM on your DB server, thus by providing an extension to the Database Engine buffer pool, which can significantly improve the I/O throughput.
6.4. New Cardinality estimator and better query plans.
6.5. Update Statistics incrementally instead of a full Scan.
PROS: The book covers most of the new features in SQL Server 2014, so it is good for DBAs and Developers who already have prior experience in SQL Server 2012 Admin and Dev. Overall a good book which gives good insights into SQL Server 2014, Azure and new features.
CONS: Not on negative side, but for newbies and junior DBAs I would suggest to get hold of some basic DBA book and stuff first then graduate to this book.
Download/Buy book Here [Packt Publishing].
Memory Optimized Indexes | Hash vs Range Indexes – SQL Server 2014
In SQL Server 2014 for In-Memory tables there are lot of changes in DDLs compared with normal Disk Based Tables. In-Memory Tables related changes we’ve seen in previous posts, check [here]. Here we will see Memory Optimized Index related changes and few important things to take care before designing your Tables and Indexes.
–> Some of the main points to note are:
1. Indexes on In-Memory tables must be created inline with CREATE TABLE DDL script only.
2. These Indexes are not persisted on Disk and reside only in memory, thus they are not logged. As these Indexes are not persistent so they are re-created whenever SQL Server is restarted. Thus In-Memory tables DO NOT support Clustered Indexes.
3. Only two types of Indexes can be created on In-Memory tables, i.e. Non Clustered Hash Index and Non Clustered Index (aka Range Index). So there is no bookmark lookup.
4. These Non Clustered Indexes are inherently Covering, and all columns are automatically INCLUDED in the Index.
5. Total there can be MAX 8 Non Clustered Indexes created on an In-Memory table.
–> Here we will see how Query Optimizer uses Hash & Range Indexes to process query and return results:
1. Hash Indexes: are used for Point Lookups or Seeks. Are optimized for index seeks on equality predicates and also support full index scans. Thus these will only perform better when the predicate clause contains only equality predicate (=).
2. Range Indexes: are used for Range Scans and Ordered Scans. Are optimized for index scans on inequality predicates, such as greater than or less than, as well as sort order. Thus these will only preform better when the predicate clause contains only inequality predicates (>, <, =, BETWEEN).
–> Let’s check this by some hands-on code. We will create 2 similar In-Memory tables, one with Range Index and another with Hash Index:
-- Create In-Memory Table with simple NonClustered Index (a.k.a Range Index):
CREATE TABLE dbo.MemOptTable_With_NC_Range_Index
(
ID INT NOT NULL
PRIMARY KEY NONCLUSTERED,
VarString VARCHAR(200) NOT NULL,
DateAdded DATETIME NOT NULL
) WITH (
MEMORY_OPTIMIZED = ON,
DURABILITY = SCHEMA_AND_DATA
)
GO
-- Create In-Memory Table with NonClustered Hash Index:
CREATE TABLE dbo.MemOptTable_With_NC_Hash_Index
(
ID INT NOT NULL
PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 10000),
VarString VARCHAR(200) NOT NULL,
DateAdded DATETIME NOT NULL
) WITH (
MEMORY_OPTIMIZED = ON,
DURABILITY = SCHEMA_AND_DATA
)
GO
–> Now we will Insert about 10k records on both the tables, so that we have good numbers of records to compare:
DECLARE @i INT = 1
WHILE @i <= 10000
BEGIN
INSERT INTO dbo.MemOptTable_With_NC_Range_Index
VALUES(@i, REPLICATE('a', 200), GETDATE())
INSERT INTO dbo.MemOptTable_With_NC_Hash_Index
VALUES(@i, REPLICATE('a', 200), GETDATE())
SET @i = @i+1
END
–> Now check the Execution Plan by using equality Operator (=) on both the tables:
SELECT * FROM MemOptTable_With_NC_Hash_Index WHERE ID = 5000 -- 4% SELECT * FROM MemOptTable_With_NC_Range_Index WHERE ID = 5000 -- 96%
You will see in the Execution Plan image below that Equality Operator with Hash Index Costs you only 4%, but Range Index Costs you 96%.

–> Now check the Execution Plan by using inequality Operator (BETWEEN) on both the tables:
SELECT * FROM MemOptTable_With_NC_Hash_Index WHERE ID BETWEEN 5000 AND 6000 -- 99% SELECT * FROM MemOptTable_With_NC_Range_Index WHERE ID BETWEEN 5000 AND 6000 -- 1%
You will see in the Execution Plan image below that Inequality Operator with Range Index Costs you only 1%, but Hash Index Costs you 99%.

So, while designing In-Memory Tables and Memory Optimized Indexes you will need to see in future that how you will be going to query that table. It also depends upon various scenarios and conditions, so always keep note of these things in advance while designing your In-Memory Tables.
Update: Know more about In-Memory tables:
XTP (eXtreme Transaction Processing) with Hekaton Tables & Native Compiled Stored Procedures – SQL Server 2014
In my previous posts [this & this] I talked about creating Memory Optimized Database, how to create In-Memory Tables & Native Compiled Stored Procedures and what happens when they are created.
Here in this post we will see how FAST actually In-Memory tables & Native Compiled Stored Procedures are, when compared with normal Disk based Tables & Simple Stored Procedures.
I’ll be using the same [ManTest] database used in my previous posts, you can refer to the DDL script [here].
–> We will create:
1. One Disk based Table & one simple Stored Procedure which will use this Disk based Table.
2. One In-Memory Table & one Native Compiled Stored Procedure which will use this In-Memory Table.
1. Let’s first create a Disk based Table and a normal Stored Procedure:
USE [ManTest]
GO
-- Create a Disk table (non-Memory Optimized):
CREATE TABLE dbo.DiskTable
(
ID INT NOT NULL
PRIMARY KEY,
VarString VARCHAR(200) NOT NULL,
DateAdded DATETIME NOT NULL
)
GO
-- Create normal Stored Procedure to load data into above Table:
CREATE PROCEDURE dbo.spLoadDiskTable @maxRows INT, @VarString VARCHAR(200)
AS
BEGIN
SET NOCOUNT ON
DECLARE @i INT = 1
WHILE @i <= @maxRows
BEGIN
INSERT INTO dbo.DiskTable VALUES(@i, @VarString, GETDATE())
SET @i = @i+1
END
END
GO
2. Now create an In-Memory table & a Native Compiled Stored Procedure to load data:
-- Create an In-Memory table:
CREATE TABLE dbo.MemOptTable
(
ID INT NOT NULL
PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 10000),
VarString VARCHAR(200) NOT NULL,
DateAdded DATETIME NOT NULL
) WITH (
MEMORY_OPTIMIZED = ON,
DURABILITY = SCHEMA_AND_DATA
)
GO
-- Create Native Compiled Stored Procedure to load data into above Table:
CREATE PROCEDURE dbo.spLoadMemOptTable @maxRows INT, @VarString VARCHAR(200)
WITH
NATIVE_COMPILATION,
SCHEMABINDING,
EXECUTE AS OWNER
AS
BEGIN ATOMIC
WITH (TRANSACTION ISOLATION LEVEL=SNAPSHOT, LANGUAGE='us_english')
DECLARE @i INT = 1
WHILE @i <= @maxRows
BEGIN
INSERT INTO dbo.MemOptTable VALUES(@i, @VarString, GETDATE())
SET @i = @i+1
END
END
GO
–> Now we will try to Load 10k record in above 2 table in various ways, as follows:
1. Load Disk based Table by T-SQL script using a WHILE loop.
2. Load the same Disk based Table by Stored Procedure which internally uses a WHILE loop.
3. Load In-Memory Table by T-SQL script using a WHILE loop.
4. Load the same In-Memory Table by Native Compiled Stored Procedure which internally uses a WHILE loop.
–> Working with Disk based Tables:
SET NOCOUNT ON
DECLARE
@StartTime DATETIME2,
@TotalTime INT
DECLARE
@i INT,
@maxRows INT,
@VarString VARCHAR(200)
SET @maxRows = 10000
SET @VarString = REPLICATE('a',200)
SET @StartTime = SYSDATETIME()
SET @i = 1
-- 1. Load Disk Table (without SP):
WHILE @i <= @maxRows
BEGIN
INSERT INTO dbo.DiskTable VALUES(@i, @VarString, GETDATE())
SET @i = @i+1
END
SET @TotalTime = DATEDIFF(ms,@StartTime,SYSDATETIME())
SELECT 'Disk Table Load: ' + CAST(@TotalTime AS VARCHAR) + ' ms (without SP)'
-- 2. Load Disk Table (with simple SP):
DELETE FROM dbo.DiskTable
SET @StartTime = SYSDATETIME()
EXEC spLoadDiskTable @maxRows, @VarString
SET @TotalTime = DATEDIFF(ms,@StartTime,SYSDATETIME())
SELECT 'Disk Table Load: ' + CAST(@TotalTime AS VARCHAR) + ' ms (with simple SP)'
–> Working with In-Memory Tables:
-- 3. Load Memory Optimized Table (without SP): SET @StartTime = SYSDATETIME() SET @i = 1 WHILE @i <= @maxRows BEGIN INSERT INTO dbo.MemOptTable VALUES(@i, @VarString, GETDATE()) SET @i = @i+1 END SET @TotalTime = DATEDIFF(ms,@StartTime,SYSDATETIME()) SELECT 'Memory Table Load: ' + CAST(@TotalTime AS VARCHAR) + ' ms (without SP)' -- 4. Load Memory Optimized Table (with Native Compiled SP): DELETE FROM dbo.MemOptTable SET @StartTime = SYSDATETIME() EXEC spLoadMemOptTable @maxRows, @VarString SET @TotalTime = DATEDIFF(ms,@StartTime,SYSDATETIME()) SELECT 'Disk Table Load: ' + CAST(@TotalTime AS VARCHAR) + ' ms (with Native Compiled SP)' GO
–> Output (Loaded 10k records):
Disk based Table Load : 28382 ms (without SP) Disk based Table SP Load : 8297 ms (with simple SP) In-Memory Table Load : 5176 ms (without SP) In-Memory Table SP Load : 174 ms (with Native Compiled SP)
So, you can clearly see the benefit and multifold increase in performance by using In-Memory Tables & Native Compiled Stored Procedures. The graph below shows performance in visual bar charts, impressive, isn’t it?

–> Final Cleanup
DROP PROCEDURE dbo.spLoadDiskTable DROP TABLE dbo.DiskTable DROP PROCEDURE dbo.spLoadMemOptTable DROP TABLE dbo.MemOptTable GO
Update: Know more about In-Memory tables:
CTP-2 released for SQL Server 2014 | and I’ve installed it !
Much awaited Community Test Preview 2 (CTP-2) for SQL Server 2014 is released and you can Download it from [here].
Check out the Release Notes [here]. This lists some limitations, issues and workarounds for them.
–> As mentioned in my [previous post] for CTP-1:
– You cannot upgrade your existing installation of CTP-1 to CTP-2.
– and similar to CTP-1 restrictions you cannot install CTP-2 with pre-existing versions of SQL Server, SSDT and Visual Studio.
Sp, this should also be a clean install to be used only for learning and POCs, and should not be used on Production Environments. Installation is very simple and similar to CTP-1 and latest SQL Server previous versions.
–> What’s new with CTP-2:
1. Can create Range Indexes for Ordered Scans (along with Hash Indexes in CTP-1).
2. Configure the In-memory usage limit to provide performance and stability for the traditional disk-based workloads.
3. Memory Optimization Advisor wizard added to SSMS for converting disk-based Tables to In-memory (Hekaton) Tables, by identifying Incompatible Data Types, Identity Columns, Constraints, Partitioning, Replications, etc.
4. Similar to above a “Naive Compilation Advisor” wizard for converting Stored Procedures to Natively Compiled SPs, by identifying Incompatible SQL statements, like: SET Options, UDFs, CTE, UNION, DISTINCT, One-part names, IN Clause, Subquery, TVFs, GOTO, ERROR_NUMBER, INSERT EXEC, OBJECT_ID, CASE, SELECT INTO, @@rowcount, QUOTENAME, EXECUTE, PRINT, EXISTS, MERGE, etc.
5. and many more enhancements with Always On like: allowing to view XEvents in UTC time, triggering XEvents when replicas change synchronization state, and recording the last time and transaction LSN committed when a replica goes to resolving state, new wizard to greatly simplify adding a replica on Azure.
Enough for now, let me go back and work with CTP-2, wait for more updates !!!
Behind the scenes with Hekaton Tables & Native Compiled SPs | SQL Server 2014
In my previous posts I talked about:
1. What’s [new with SQL Server 2014 & Hekaton] and CTP-1 [download link].
2. [Installing] SQL Server 2014 with Sneak-Peek.
3. Working with [Hekaton] Tables.
Here, in this post I’ll discuss more on what the new SQL Server 2014 does behind the scene while you create Hekaton or Memory-Optimized Tables & Native Compiled Stored Procedures.
I will use the same Database (Hekaton enabled) created in my [previous post], and then we will check what SQL Server does while creating Hekaton tables & Compiled SPs:
–> Create Memory-Optimized Table:
USE [ManTest] GO CREATE TABLE dbo.Test_memoryOptimizedTable ( TestID INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 1024), TestName NVARCHAR(100) NOT NULL, DateAdded DATETIME NOT NULL ) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA) GO
–> Create Native Compiled Stored Procedure:
USE [ManTest] GO CREATE PROCEDURE dbo.Test_NativelyCompiledStoredProcedure ( @param1 INT not null, @param2 NVARCHAR(100) not null ) WITH NATIVE_COMPILATION, SCHEMABINDING, EXECUTE AS OWNER AS BEGIN ATOMIC WITH ( TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english' ) INSERT dbo.Test_memoryOptimizedTable VALUES (@param1, @param2, getdate()) END GO
–> After executing above code as usual the Tables & Stored Procedure will be created. But the important thing here is what the Hekaton Engine does internally, is shown in the following image below:
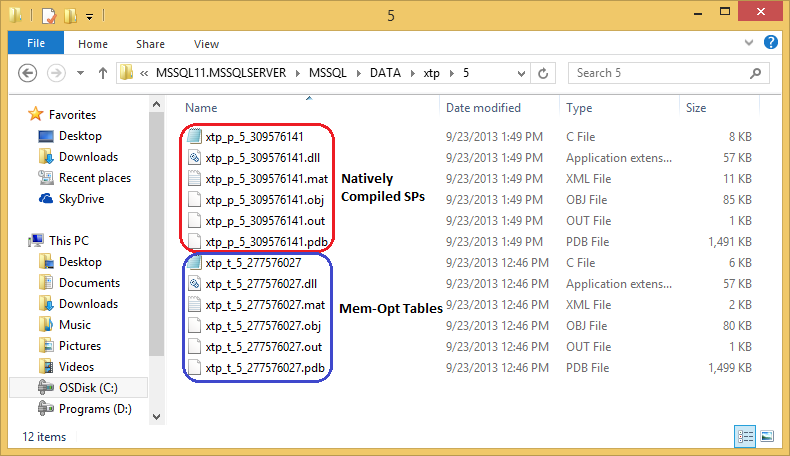
– It creates total 6 files for every Table & SP with following extensions: .c, .dll, .mat, .obj, .out and .pdb.
– Most important are the C Code and the DLL files with four (4) other supporting files for each Table the Stored Procedure and stores them at following path: “C:\Program Files\Microsoft SQL Server\MSSQL11.MSSQLSERVER\MSSQL\DATA\xtp\5\”.
– The “xtp” folder/directory here contains a sub-folder “5” which is nothing but the Database ID, check this:
SELECT DB_ID();
SELECT object_id, name, type
FROM sys.sysobjects
WHERE name IN ('Test_memoryOptimizedTable', 'Test_NativelyCompiledStoredProcedure');
– If you look closely the file are create with particular naming conventions and relate to the results of above query:
— For files xtp_t_5_277576027: xtp_t is for Table, 5 is the Database ID and 277576027 is the Object (table) ID.
— For files xtp_p_5_325576198: xtp_p is for Stored Procedure, 5 is the Database ID and 325576198 is the Object (Stored Procedure) ID.
–> Opening the xtp_t_5_277576027.c file looks like this:
#define __in
#define __out
#define __inout
#define __in_opt
#define __out_opt
#define __inout_opt
#define __in_ecount(x)
#define __out_ecount(x)
#define __deref_out_ecount(x)
#define __inout_ecount(x)
#define __in_bcount(x)
#define __out_bcount(x)
#define __deref_out_bcount(x)
#define __deref_out_range(x, y)
#define __success(x)
#define __inout_bcount(x)
#define __deref_opt_out
#define __deref_out
#define __checkReturn
#define __callback
#define __nullterminated
typedef unsigned char bool;
typedef unsigned short wchar_t;
typedef long HRESULT;
typedef unsigned __int64 ULONG_PTR;
#include "hkenggen.h"
#include "hkrtgen.h"
#include "hkgenlib.h"
#define ENABLE_INTSAFE_SIGNED_FUNCTIONS
#include "intsafe.h"
int _fltused = 0;
int memcmp(const void*, const void*, size_t);
void *memcpy(void*, const void*, size_t);
void *memset(void*, int, size_t);
#define offsetof(s,f) ((size_t)&(((s*)0)->f))
struct hkt_277576027
{
__int64 hkc_3;
long hkc_1;
unsigned short hkvdo[2];
};
struct hkis_27757602700002
{
long hkc_1;
};
struct hkif_27757602700002
{
long hkc_1;
};
unsigned short GetSerializeSize_277576027(
struct HkRow const* hkRow)
{
struct hkt_277576027 const* row = ((struct hkt_277576027 const*)hkRow);
return ((row->hkvdo)[1]);
}
HRESULT Serialize_277576027(
struct HkRow const* hkRow,
unsigned char* buffer,
unsigned short bufferSize,
unsigned short* copySize)
{
return (RowSerialize(hkRow, (GetSerializeSize_277576027(hkRow)), buffer, bufferSize, copySize));
}
HRESULT Deserialize_277576027(
struct HkTransaction* tx,
struct HkTable* table,
unsigned char const* data,
unsigned short datasize,
struct HkRow** hkrow)
{
return (RowDeserialize(tx, table, data, datasize, sizeof(struct hkt_277576027), (sizeof(struct hkt_277576027) + 200), hkrow));
}
unsigned short GetSerializeRecKeySize_277576027(
struct HkRow const* hkRow)
{
struct hkt_277576027 const* row = ((struct hkt_277576027 const*)hkRow);
unsigned short size = sizeof(struct hkif_27757602700002);
return size;
}
HRESULT SerializeRecKey_27757602700002(
struct HkRow const* hkRow,
unsigned char* hkKey,
unsigned short bufferSize,
unsigned short* keySize)
{
struct hkt_277576027 const* row = ((struct hkt_277576027 const*)hkRow);
struct hkif_27757602700002* key = ((struct hkif_27757602700002*)hkKey);
(*keySize) = sizeof(struct hkif_27757602700002);
if ((bufferSize < (*keySize)))
{
return -2013265920;
}
(key->hkc_1) = (row->hkc_1);
return 0;
}
HRESULT DeserializeRecKey_277576027(
unsigned char const* data,
unsigned short dataSize,
struct HkSearchKey* key,
unsigned short bufferSize)
{
struct hkif_27757602700002 const* source = ((struct hkif_27757602700002 const*)data);
struct hkis_27757602700002* target = ((struct hkis_27757602700002*)key);
unsigned long targetSize = sizeof(struct hkis_27757602700002);
if ((targetSize > bufferSize))
{
return -2013265920;
}
(target->hkc_1) = (source->hkc_1);
return 0;
}
__int64 CompareSKeyToRow_27757602700002(
struct HkSearchKey const* hkArg0,
struct HkRow const* hkArg1)
{
struct hkis_27757602700002* arg0 = ((struct hkis_27757602700002*)hkArg0);
struct hkt_277576027* arg1 = ((struct hkt_277576027*)hkArg1);
__int64 ret;
ret = (CompareKeys_int((arg0->hkc_1), (arg1->hkc_1)));
return ret;
}
__int64 CompareRowToRow_27757602700002(
struct HkRow const* hkArg0,
struct HkRow const* hkArg1)
{
struct hkt_277576027* arg0 = ((struct hkt_277576027*)hkArg0);
struct hkt_277576027* arg1 = ((struct hkt_277576027*)hkArg1);
__int64 ret;
ret = (CompareKeys_int((arg0->hkc_1), (arg1->hkc_1)));
return ret;
}
unsigned long ComputeSKeyHash_27757602700002(
struct HkSearchKey const* hkArg)
{
struct hkis_27757602700002* arg = ((struct hkis_27757602700002*)hkArg);
unsigned long hashState = 0;
unsigned long hashValue = 0;
hashValue = (ComputeHash_int((arg->hkc_1), (&hashState)));
return hashValue;
}
unsigned long ComputeRowHash_27757602700002(
struct HkRow const* hkArg)
{
struct hkt_277576027* arg = ((struct hkt_277576027*)hkArg);
unsigned long hashState = 0;
unsigned long hashValue = 0;
hashValue = (ComputeHash_int((arg->hkc_1), (&hashState)));
return hashValue;
}
struct HkOffsetInfo const KeyOffsetArray_27757602700002[] =
{
{
offsetof(struct hkis_27757602700002, hkc_1),
0,
0,
},
};
struct HkKeyColsInfo const KeyColsInfoArray_277576027[] =
{
{
sizeof(struct hkis_27757602700002),
KeyOffsetArray_27757602700002,
sizeof(struct hkis_27757602700002),
sizeof(struct hkis_27757602700002),
},
};
struct HkOffsetInfo const OffsetArray_277576027[] =
{
{
offsetof(struct hkt_277576027, hkc_1),
0,
0,
},
{
(offsetof(struct hkt_277576027, hkvdo) + 0),
0,
0,
},
{
offsetof(struct hkt_277576027, hkc_3),
0,
0,
},
};
struct HkColsInfo const ColsInfo_277576027 =
{
sizeof(struct hkt_277576027),
OffsetArray_277576027,
KeyColsInfoArray_277576027,
};
struct HkHashIndexMD HashIndexMD_277576027[] =
{
{
2,
1,
1024,
CompareSKeyToRow_27757602700002,
CompareRowToRow_27757602700002,
ComputeSKeyHash_27757602700002,
ComputeRowHash_27757602700002,
},
};
struct HkTableMD TableMD =
{
sizeof(struct hkt_277576027),
(sizeof(struct hkt_277576027) + 200),
1,
HashIndexMD_277576027,
0,
0,
0,
(&ColsInfo_277576027),
277576027,
0,
GetSerializeSize_277576027,
Serialize_277576027,
Deserialize_277576027,
GetSerializeRecKeySize_277576027,
SerializeRecKey_27757602700002,
DeserializeRecKey_277576027,
};
__declspec(dllexport)
struct HkTableBindings g_Bindings =
{
277576027,
(&TableMD),
};
I cannot understand a single bit here, but this recalls memories when I was studying C & C++ in college 🙂
–> Final Cleanup
DROP PROCEDURE dbo.Test_NativelyCompiledStoredProcedure DROP TABLE dbo.Test_memoryOptimizedTable
Update: Know more about In-Memory tables:


![]()
Current Visitors

StatCounter …since April 2012

 Leisure blog: Creek & Trails
Leisure blog: Creek & Trails
- NMDC Hyderabad Marathon – My first 42k FM, cramps, training and fuelling
- Singapore (Part 2) – 6 days itinerary, sightseeing & attractions
- Singapore (Part 1) – Tickets, Visa, Hotel, Forex Card/Cash, Metro/Bus cards
- I got full refund of my flight tickets during COVID lockdown (AirIndia via MakeMyTrip)
- YouTube – Your Google Ads account was cancelled due to no spend
- YouTube latest update on its YPP (YouTube Partner Program) which may affect your channel
- Starting your own blog !!!
- How to file ITR (Income Tax Return) online AY 2017-18 (for simple salaried)
- Scam – Become a kin/hier and earn a fortune – via LinkedIn and Email
- Places to visit in and around Vizag (aka Visakhapatnam)
