“Generative AI”, my take after finishing a course
I just finished a course about “What Is Generative AI?” on LinkedIn. Here are some of my Key Takeaways:
1. Role of Generative AI: Generative AI is described as a tool that is changing how humans create. Its designed to generate new content or data that is similar to existing patterns. It’s used for tasks such as image synthesis, text generation, and creating realistic content.
2. Importance and Evolution: With Generative AI we no longer need artistic talent to draw or to sing. We can access now concise information in just a manner of seconds. We can also automatically generate text such as news articles or product descriptions. It traces the evolution of generative AI, mentioning breakthroughs and models like GANs, VAEs, ChatGPT, DALL-E, Kubrick, and Journey.
3. Generative AI vs Conventional AI: Generative AI as its name suggests, generates new content. In contrast to this Conventional or Discriminative AI, which focuses on classifying or identifying content that is based on preexisting data.
4. Applications of Generative AI: It is applied in various domains, including natural language models (e.g., ChatGPT), text-to-image applications (e.g., Midjourney, DALL-E, Stable Diffusion), GANs for creative purposes (e.g., Audi wheel designs, film visual effects), VAEs for anomaly detection (e.g., fraud detection, industrial quality control), and more.
5. Popular Generative AI Tools: Notable generative AI tools are mentioned, such as ChatGPT, DALL-E, Midjourney, and Stable Diffusion. As a creative techie you can go to GitHub and create a notebook by choosing your favourite Generative AI model from the repo.
6. Future Predictions: It provides predictions for the next two to three years, foreseeing continued use of generative AI in computer graphics, animation, natural language understanding, energy optimization, transportation, and more. Longer-term predictions include applications in architecture, manufacturing, content creation, and a paradigm shift in the job market.
7. Impact on Jobs: The future of jobs is discussed, acknowledging the possibility of a shift in the job market. It’s normal for some jobs to disappear, while other new ones will be introduced.
#ArtificialIntelligenceForBusiness #GenerativeaAI #ArtificialIntelligence
SQL Planner, a monitoring tool for SQL Server for DBAs & Developers
SQL Planner is a Microsoft SQL Server monitoring Software product that helps DBA or Developer to identify issues (for ex. High CPU, Memory, Disk latency, Expensive query, Waits, Storage shortage, etc) and root cause analysis with a fast and deep level of analytical reports. Historical data is stored in the repository database for as many days as you want.
About SQL Planner monitoring tool, watch the intro here:
SQL Planner has several features under one roof:
– SQL Server Monitoring
– SQL Server Backup Restore Solution
– SQL Server Index Defragmentation Report and Solution
– SQL server Scripting solution
– DBA Handover Notes Management
Features and Capabilities:
SQL Planner is mainly built for the Monitoring feature and has several metrics as below, their details are available here:
– CPU & Memory Usage reports, Expensive Query and Procedure
– Nice visualization on CPU , Memory , IO usage , expensive query details
– Performance counters Reports
– IO Usage Analysis
– Deadlock & Blockers analysis
– Always On Monitoring
– SQL Server Waits analysis
– SQL Server Agent Job Analysis
– Missing Index analysis
– Storage analysis
– SQL Error Log Scan & Report
– Receiving Alerts: There are 50+ criteria when the Notification is sent via email and
maintained in SQL Planner dashboard too, more details here.
– Handover Notes Management
Cost:
Absolutely forever free to students , teachers and for developer/ DBA in development environment.
Some screenshots of the tool capabilities:
2021 blogging in review (Thank you & Happy New Year 2022 !!!)
Happy New Year 2022… from SQL with Manoj !!!
As WordPress.com Stats helper monkeys have stopped preparing annual report from last few years for the blogs hosted on their platform. So I started preparing my own Annual Report every end of the year to thank my readers for their support, feedback & motivation, and also to check & share the progress of this blog.
As I mentioned in my last year’s annual report I could not dedicate enough time to blog in year 2019 & 2020, so it also continued in 2021 with fewer posts. Thus, due to inactivity of 2-3 years, the blog hits are remaining below ~1k hits per day which is very low from what I was getting earlier (around 3k to 3.5k hits per day). So, you can see a drastic decline of hits in 2021 year in the image below.
–> Here are some Crunchy numbers from 2021:
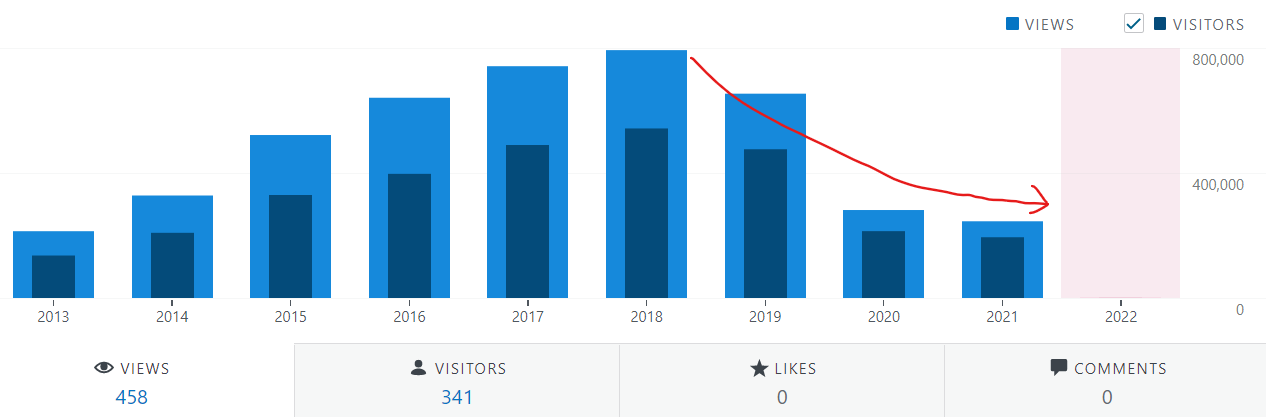
The Louvre Museum has a foot fall of ~10 million visitors per year. This blog was viewed about 245,470 times by 194,886 unique visitors in 2021. If it were an exhibit at the Louvre Museum, it would take about ~50 days for that many people to see it.
There were 18 pictures uploaded, taking up a total of ~1 MB. That’s about ~1 pictures every month.
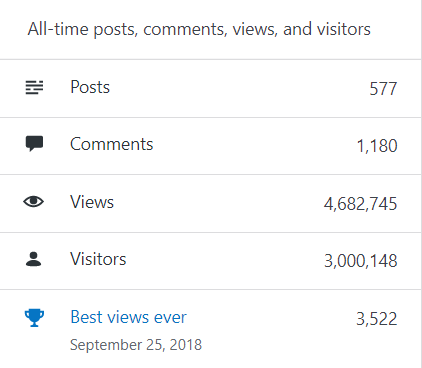
–> All-time posts, views, and visitors:
–> Posting Patterns:
In 2021, as I mentioned the reason above there were just 14 new posts, growing the total archive of this blog to 577 posts.
LONGEST STREAK: 4 post in April 2021
–> Attractions in 2021:
These are the top 5 posts that got most views in 2021:
0. Blog Home Page (30,424 views)
1. The server may be running out of resources, or the assembly may not be trusted with PERMISSION_SET = EXTERNAL_ACCESS or UNSAFE (12,151 views)
2. Reading JSON string with Nested array of elements (10,527 views)
3. Windows could not start SQL Server, error 17051, SQL Server Eval has expired (6,032 views)
4. Using IDENTITY function with SELECT statement in SQL Server (5,960 views)
5. SQL Server blocked access to procedure ‘dbo.sp_send_dbmail’ of component ‘Database Mail XPs’ (5,268 views)
–> How did they find me?
The top referring sites and search engines in 2021 were:
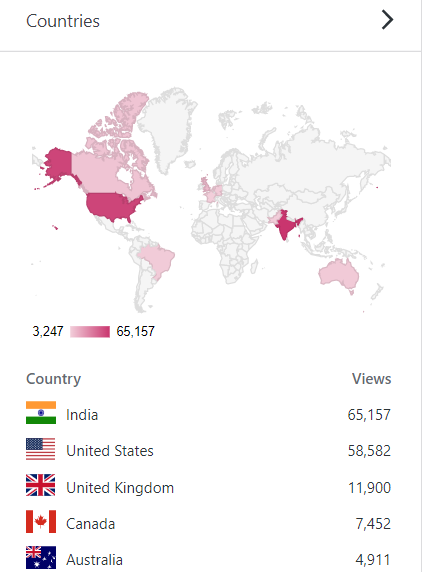
–> Where did they come from?
Out of 210 countries, top 5 visitors came from India, United States, United Kingdom, Canada and Australia:
–> Followers: 442
WordPress.com: 180
Email: 260
Facebook Page: 1,454
–> Alexa Rank (lower the better)
Global Rank: ~1m (as of 31st DEC 2021)
Previous rank: 835,163 (back in 2020)
–> YouTube Channel:
– SQLwithManoj on YouTube
– Total Subscribers: 19,675
– Total Videos: 80
–> 2022 New Year Resolution:
– Write at least 1 blog post every week or two.
– Write on new features in SQL Server 2022 and SQL/Data world.
– Started writing on Microsoft Big Data Platform, related to Azure Data Lake and Databricks (Spark/Scala), CosmosDB, etc. so I will continue to explore more on this area and write.
– Post at least 1 video every week on my YouTube channel
That’s all for 2021, see you in year 2022, all the best !!!
Connect me on Facebook, Twitter, LinkedIn, YouTube, Google, Email
SQL Server 2022 preview announced, some awesome new features !!!
SQL Server 2022 is coming !!!
On 2nd November 2021 in MS Ignite 2021 event Microsoft announced the preview of new version of SQL Server i.e. SQL Server 2022.
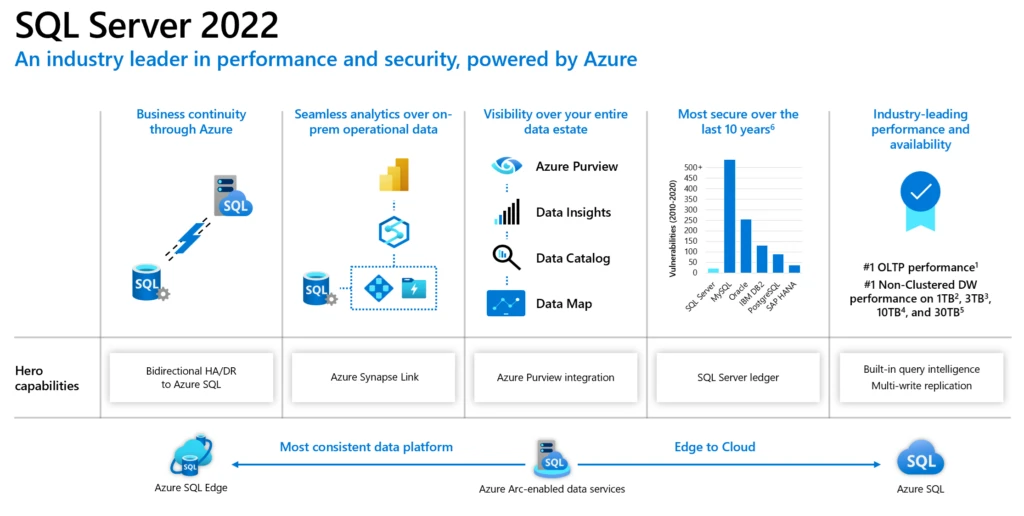
SQL Server 2022 will be more focused on Azure-enabled cloud and big data space, here are some excerpts from the announcements:
1. Azure Synapse link integration with SQL for ETL free and real time reporting & analytics: Here you can setup a Synapse Link relationship between SQL Pool in Azure Synapse and SQL Server as a data source and link required tables in Synapse Workspace. You can create PowerBI reports on top of these tables available in Synapse Workspace with real time data, without requiring you to write/setup an ETL from SQL Server to Synapse SQL Pool. This will also let you combine/JOIN datasets from different sources, data lake, files, etc. Similarly Data Scientists can create ML Models by using Synapse Spark Pools with PySpark language.
2. Azure Purview integration: with also work with SQL Server, for data discovery and data governance. Here you can use Purview to scan and capture SQL Server metadata for data catalog, classify the data (PII, non-PII, etc), and even control access rights on SQL Server.
3. Bi-directional HA/DR between SQL Server and Azure SQL MI: Now you can use Azure SQL Managed Instance as a Disaster Recovery site for your SQL Server workloads. You can setup Disaster Recovery as a Managed Service with Azure SQL Managed Instance (SQL MI). A Distributed Availability Group is created automatically with a new Azure SQL MI as READ_ONLY replica. This way you you can do failover from SQL Server to Azure SQL MI, and also back from Azure SQL MI to SQL Server.
4. QueryStore and IQP enhancements: Parameter Sensitive Plan optimization for handling Parameter Sniffing issues. Now the SQL optimizer will cache multiple plans for a Stored Procedure which uses different parameter values having big gap in cardinality providing consistent query performance. Enhancements on Cardinality-Estimation & Max-DOP feedback, and support for read replicas from Availability Groups.
5. SQL Server Ledger: Built on Blockchain technology, this feature will allow you to create and setup smart contracts on SQL Server itself. With ledger based immutable record of data you can make sure the data modified over time is not tampered with, and will be helpful in Banking, Retail, e-commerce, Supply Chain and many more industries.
6. Scalable SQL Engine and new features coming:
– Buffer Pool parallel scan
– Improvements on tempDB latch contention (System page GAM/SGAM concurrency)
– In-Memory (Hekaton) OLTP enhancements
– Multi-write replication with last writer wins
– Redesigned and improved SPANSHOT backups
– Polybase (REST API) for connecting to various files formats (parquet, JSON, csv) in Data lake, Delta tables, ADLS, S3, etc.
– Backup/Restore to S3 storage
– JSON enhancements and new functions
– New Time series T-SQL functions
For more details on SQL Server 2022 please check here” Microsoft official SQL Server Blog.
SQL DBA – Integration Services evaluation period has expired
I got an email from one SQL Server developer that he is not able to use import/export wizard and it is failing with below error:
TITLE: SQL Server Import and Export Wizard --------------------------------------
Data flow execution failed. Error 0xc0000033:
{5CCE2348-8B9F-4FD0-9AFA-9EA6D19576A7}: Integration Services evaluation period has
expired. Error 0xc0000033: {5CCE2348-8B9F-4FD0-9AFA-9EA6D19576A7}: Integration
Services evaluation period has expired. ------------------------------
ADDITIONAL INFORMATION: Integration Services evaluation period has expired.
({5CCE2348-8B9F-4FD0-9AFA-9EA6D19576A7}) ----------------------------------------
–> Investigate:
As per the above error message its clear that the SQL Server Instance that you had installed was under Evaluation of 180 days, because you didn’t applied any Product Key. So, now how can you make it usable again? All you need is a Product key of SQL Server and installation media to start an upgrade so that you can apply the new Product Key there.
–> Fix:
1. Open the SQL Server Installation Center and click on Maintenance link, and then click on Edition Upgrade:

2. Now on the Upgrade window Click Next and you will reach the Product Key page, apply the Key and click Next:

3. On the Select Instance page, select the SQL Instance that you want to fix and Click next. It will take some time and finally you will see a final window and click Upgrade:

4. Finally you will see the successful window, click on Close button:

5. Now Restart the SQL Server Service for this Instance, and you will see it running fine.
–> Finally, go back to SSMS and now you can connect to the SQL Instance.


![]()
Current Visitors

StatCounter …since April 2012

 Leisure blog: Creek & Trails
Leisure blog: Creek & Trails
- An error has occurred; the feed is probably down. Try again later.
