Archive
Reference a table in a Stored Procedure (SP), and call the SP from the trigger? – MSDN TSQL forum
–> Question:
I have three tables “a”, “b”, “c “.
I want to make one trigger on table “a” and one on table “b”, the trigger inturn calls a stored proc(SP) to perform insertion deletion task on table “c”.
When some body inserts or updates table “a” , the trigger on table “a” inserts or updates table “c” by calling the stored proc(SP), and there after updates table “b” from trigger it self (this stmt is below the call of (SP).
Q1) i am using table “a” in (SP), i wanted to know that, is it correct to use the table “a” in stored proc(SP) to get the new inserted record or updated record to insert or update table “c” as the control is till in tigger of table “a”?
Well when table “b” gets updated from the trigger of table “a” , then the trigger of table “b” gets activated and it inserts or update the table “c” by calling (SP).
Q2) at this place when trigger of table”b” calls the same (SP) to insert table “c”, it uses table “a” and “b” to insert update tabel “c”, at this point also the control is still in trigger, so i whould like to know is it correct (technically).
I know that by changing few things in tables i can make things easy
I read this in msdn:
“AFTER specifies that the trigger is fired only when all operations specified in the triggering SQL statement have executed successfully. All referential cascade actions and constraint checks also must succeed before this trigger fires.”
But I would to know that, what exactally happens in above case , how and when event are fired and gets affected. and finally is it correct?
–> My Answer:
Why are you creating a separate Stored Proc to fire from the trigger?
You can have the SP logic in the Trigger itself. If you use an SP, then you would not get the INSERTED & DELETED Trigger/Magic tables that you can get in the Trigger.
Also you can avoid Triggers and create single SP to add records in Table a & b and update the table c in a single transaction.
Ref Link.
Clustered Index do “NOT” guarantee Physically Ordering or Sorting of Rows
Myth: Lot of SQL Developers I’ve worked with and interviewed have this misconception, that Clustered Indexes are Physically Sorted and Non-Clustered Index are Logically Sorted. When I ask them reasons, all come with their own different versions.
I discussed about this in my previous post long time back, where I mentioned as per the MSDN that “Clustered Indexes do not guarantee Physical Ordering of rows in a Table”. And today in this post I’m going to provide an example to prove it.
Clustered Index is the table itself as its Leaf-Nodes contains the Data-Pages of the table. The Data-Pages are nothing but Doubly Linked-List Data-Structures linked to their leading & preceding Data-Pages. The Data-Pages and rows in them are Ordered by the Clustering Key. Thus there can be only one Clustered Index on a table.
When a new Clustered Index is created on a table, it reorganizes the table’s Data-Pages Physically so that the rows are Logically sorted. But when a tables goes through updates, like INSERT/UPDATE/DELETE operations then the index gets fragmented and thus the Physical Ordering of Data-Pages gets lost. But still the Data-Pages of the Clustered Index or the Table are chained together by Doubly Linked-List in Logical Order.
We will see this behavior in the following example:
USE AdventureWorks2012
GO
CREATE TABLE test (i INT PRIMARY KEY not null, j VARCHAR(2000))
INSERT INTO test (i,j)
SELECT 1, REPLICATE('a',100) UNION ALL
SELECT 2, REPLICATE('a',100) UNION ALL
SELECT 3, REPLICATE('a',100) UNION ALL
SELECT 5, REPLICATE('a',100) UNION ALL
SELECT 6, REPLICATE('a',100)
SELECT * FROM test
DBCC IND(AdventureWorks2012, 'test', -1);
DBCC TRACEON(3604);
DBCC PAGE (AdventureWorks2012, 1, 22517, 1);
As you can see above we inserted 5 records in a table having PK as Clustering Key with following values: 1,2,3,5,6. We skipped the value 4.
–> Here is the Output of DBCC PAGE command execute in the end:
The DBCC PAGE provides very descriptive Output, but here I’ve just extracted the useful information we need.
OFFSET TABLE: Row - Offset 4 (0x4) - 556 (0x22c) --> 1=6 3 (0x3) - 441 (0x1b9) --> 1=5 2 (0x2) - 326 (0x146) --> 1=3 1 (0x1) - 211 (0xd3) --> 1=2 0 (0x0) - 96 (0x60) --> 1=1
It show the 5 rows with their memory allocated address in both decimal and hexadecimal formats, which is contiguous. Thus all the rows are Physically Ordered.
Now, let’s insert the value “4” that we skipped initially:
INSERT INTO test (i,j)
SELECT 4, REPLICATE('a',100)
SELECT * FROM test
DBCC IND(AdventureWorks2012, 'test', -1);
DBCC TRACEON(3604);
DBCC PAGE (AdventureWorks2012, 1, 22517, 1);
–> Here is the new Output of DBCC PAGE command execute in the end:
OFFSET TABLE: Row - Offset 5 (0x5) - 556 (0x22c) --> 1=6 4 (0x4) - 441 (0x1b9) --> 1=5 3 (0x3) - 671 (0x29f) --> 1=4 <-- new row added here 2 (0x2) - 326 (0x146) --> 1=3 1 (0x1) - 211 (0xd3) --> 1=2 0 (0x0) - 96 (0x60) --> 1=1
As you can see very clearly in the output above that the memory allocation address for the new row with PK value = “4” is 671, which is not in between and greater than the address of the last row i.e. 556. The memory address of the last 2 rows is unchanged (441 & 556) and the new row is not accommodated in between as per the sort order but at the end. There is no Physical Ordering and the new row is Logically Chained with other rows and thus is Logically and Ordered, similar to the image below:
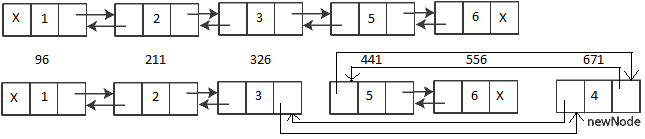
Myth Busted: Hope the above exercise clears that Clustered Indexes do not guarantee the Physical Ordering of Rows & Data Pages.
-- Final Cleanup DROP TABLE test


![]()
Current Visitors

StatCounter …since April 2012

 Leisure blog: Creek & Trails
Leisure blog: Creek & Trails
- NMDC Hyderabad Marathon – My first 42k FM, cramps, training and fuelling
- Singapore (Part 2) – 6 days itinerary, sightseeing & attractions
- Singapore (Part 1) – Tickets, Visa, Hotel, Forex Card/Cash, Metro/Bus cards
- I got full refund of my flight tickets during COVID lockdown (AirIndia via MakeMyTrip)
- YouTube – Your Google Ads account was cancelled due to no spend
- YouTube latest update on its YPP (YouTube Partner Program) which may affect your channel
- Starting your own blog !!!
- How to file ITR (Income Tax Return) online AY 2017-18 (for simple salaried)
- Scam – Become a kin/hier and earn a fortune – via LinkedIn and Email
- Places to visit in and around Vizag (aka Visakhapatnam)
