Spark error – Parquet does not support decimal. See HIVE-6384
I was creating a Hive table in Databricks Notebook from a Parquet file located in Azure Data Lake store by following command:
val df = spark.read.parquet(
"abfss://adlsstore@MyStorageAccount.dfs.core.windows.net/x/y/z/*.parquet")
df.write.mode("overwrite").saveAsTable("tblOrderDetail")
But I was getting following error:
warning: there was one feature warning; re-run with -feature for details
java.lang.UnsupportedOperationException: Parquet does not support decimal. See HIVE-6384
As per the above error it relates to some Hive version conflict, so I tried checking the Hive version by running below command and found that it is pointing to an old version (0.13.0). This version of Hive metastore did not support the BINARY datatypes for parquet formatted files.
spark.conf.get("spark.sql.hive.metastore.version")

Also as per this Jira Task on HIVE-6384 the support for multiple datatypes was implemented for Parquet SerDe in Hive 1.2.0 version.
So to update the Hive metastore to the current version you just need to add below commands in the configuration of the cluster you are using.
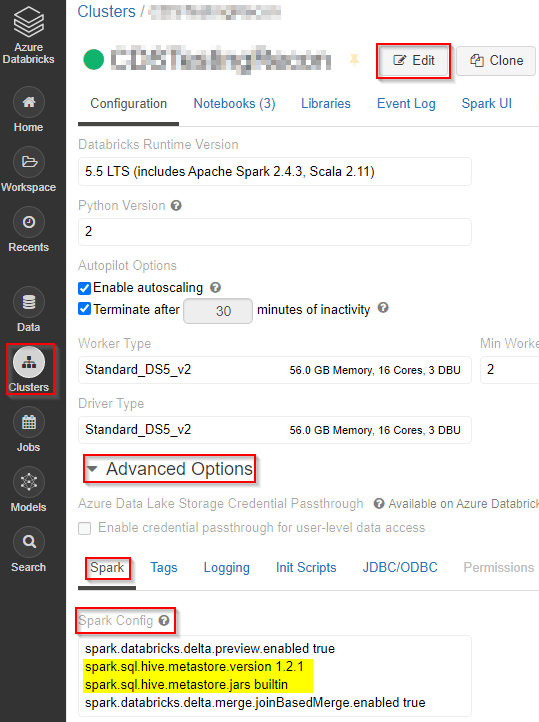
Click on “Clusters” –> click “Edit” on the top –> expand “Advanced Options” –> under “Spark” tab and “Spark Config” box add the below two commands:
spark.sql.hive.metastore.version 1.2.1
spark.sql.hive.metastore.jars builtin
You just need to restart the cluster so that the new settings are in use.
Some similar errors:
– Parquet does not support date
– Parquet does not support timestamp
-
August 6, 2020 at 5:45 pmHIVE-6384 Errors with Spark and Parquet – Curated SQL


![]()
Current Visitors

StatCounter …since April 2012

 Leisure blog: Creek & Trails
Leisure blog: Creek & Trails
- NMDC Hyderabad Marathon – My first 42k FM, cramps, training and fuelling
- Singapore (Part 2) – 6 days itinerary, sightseeing & attractions
- Singapore (Part 1) – Tickets, Visa, Hotel, Forex Card/Cash, Metro/Bus cards
- I got full refund of my flight tickets during COVID lockdown (AirIndia via MakeMyTrip)
- YouTube – Your Google Ads account was cancelled due to no spend
- YouTube latest update on its YPP (YouTube Partner Program) which may affect your channel
- Starting your own blog !!!
- How to file ITR (Income Tax Return) online AY 2017-18 (for simple salaried)
- Scam – Become a kin/hier and earn a fortune – via LinkedIn and Email
- Places to visit in and around Vizag (aka Visakhapatnam)
