Archive
CTP-2 released for SQL Server 2014 | and I’ve installed it !
Much awaited Community Test Preview 2 (CTP-2) for SQL Server 2014 is released and you can Download it from [here].
Check out the Release Notes [here]. This lists some limitations, issues and workarounds for them.
–> As mentioned in my [previous post] for CTP-1:
– You cannot upgrade your existing installation of CTP-1 to CTP-2.
– and similar to CTP-1 restrictions you cannot install CTP-2 with pre-existing versions of SQL Server, SSDT and Visual Studio.
Sp, this should also be a clean install to be used only for learning and POCs, and should not be used on Production Environments. Installation is very simple and similar to CTP-1 and latest SQL Server previous versions.
–> What’s new with CTP-2:
1. Can create Range Indexes for Ordered Scans (along with Hash Indexes in CTP-1).
2. Configure the In-memory usage limit to provide performance and stability for the traditional disk-based workloads.
3. Memory Optimization Advisor wizard added to SSMS for converting disk-based Tables to In-memory (Hekaton) Tables, by identifying Incompatible Data Types, Identity Columns, Constraints, Partitioning, Replications, etc.
4. Similar to above a “Naive Compilation Advisor” wizard for converting Stored Procedures to Natively Compiled SPs, by identifying Incompatible SQL statements, like: SET Options, UDFs, CTE, UNION, DISTINCT, One-part names, IN Clause, Subquery, TVFs, GOTO, ERROR_NUMBER, INSERT EXEC, OBJECT_ID, CASE, SELECT INTO, @@rowcount, QUOTENAME, EXECUTE, PRINT, EXISTS, MERGE, etc.
5. and many more enhancements with Always On like: allowing to view XEvents in UTC time, triggering XEvents when replicas change synchronization state, and recording the last time and transaction LSN committed when a replica goes to resolving state, new wizard to greatly simplify adding a replica on Azure.
Enough for now, let me go back and work with CTP-2, wait for more updates !!!
Behind the scenes with Hekaton Tables & Native Compiled SPs | SQL Server 2014
In my previous posts I talked about:
1. What’s [new with SQL Server 2014 & Hekaton] and CTP-1 [download link].
2. [Installing] SQL Server 2014 with Sneak-Peek.
3. Working with [Hekaton] Tables.
Here, in this post I’ll discuss more on what the new SQL Server 2014 does behind the scene while you create Hekaton or Memory-Optimized Tables & Native Compiled Stored Procedures.
I will use the same Database (Hekaton enabled) created in my [previous post], and then we will check what SQL Server does while creating Hekaton tables & Compiled SPs:
–> Create Memory-Optimized Table:
USE [ManTest] GO CREATE TABLE dbo.Test_memoryOptimizedTable ( TestID INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 1024), TestName NVARCHAR(100) NOT NULL, DateAdded DATETIME NOT NULL ) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA) GO
–> Create Native Compiled Stored Procedure:
USE [ManTest] GO CREATE PROCEDURE dbo.Test_NativelyCompiledStoredProcedure ( @param1 INT not null, @param2 NVARCHAR(100) not null ) WITH NATIVE_COMPILATION, SCHEMABINDING, EXECUTE AS OWNER AS BEGIN ATOMIC WITH ( TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english' ) INSERT dbo.Test_memoryOptimizedTable VALUES (@param1, @param2, getdate()) END GO
–> After executing above code as usual the Tables & Stored Procedure will be created. But the important thing here is what the Hekaton Engine does internally, is shown in the following image below:
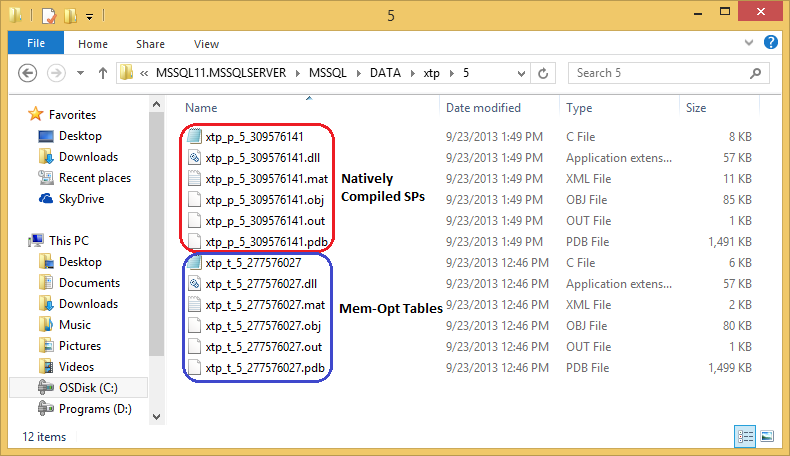
– It creates total 6 files for every Table & SP with following extensions: .c, .dll, .mat, .obj, .out and .pdb.
– Most important are the C Code and the DLL files with four (4) other supporting files for each Table the Stored Procedure and stores them at following path: “C:\Program Files\Microsoft SQL Server\MSSQL11.MSSQLSERVER\MSSQL\DATA\xtp\5\”.
– The “xtp” folder/directory here contains a sub-folder “5” which is nothing but the Database ID, check this:
SELECT DB_ID();
SELECT object_id, name, type
FROM sys.sysobjects
WHERE name IN ('Test_memoryOptimizedTable', 'Test_NativelyCompiledStoredProcedure');
– If you look closely the file are create with particular naming conventions and relate to the results of above query:
— For files xtp_t_5_277576027: xtp_t is for Table, 5 is the Database ID and 277576027 is the Object (table) ID.
— For files xtp_p_5_325576198: xtp_p is for Stored Procedure, 5 is the Database ID and 325576198 is the Object (Stored Procedure) ID.
–> Opening the xtp_t_5_277576027.c file looks like this:
#define __in
#define __out
#define __inout
#define __in_opt
#define __out_opt
#define __inout_opt
#define __in_ecount(x)
#define __out_ecount(x)
#define __deref_out_ecount(x)
#define __inout_ecount(x)
#define __in_bcount(x)
#define __out_bcount(x)
#define __deref_out_bcount(x)
#define __deref_out_range(x, y)
#define __success(x)
#define __inout_bcount(x)
#define __deref_opt_out
#define __deref_out
#define __checkReturn
#define __callback
#define __nullterminated
typedef unsigned char bool;
typedef unsigned short wchar_t;
typedef long HRESULT;
typedef unsigned __int64 ULONG_PTR;
#include "hkenggen.h"
#include "hkrtgen.h"
#include "hkgenlib.h"
#define ENABLE_INTSAFE_SIGNED_FUNCTIONS
#include "intsafe.h"
int _fltused = 0;
int memcmp(const void*, const void*, size_t);
void *memcpy(void*, const void*, size_t);
void *memset(void*, int, size_t);
#define offsetof(s,f) ((size_t)&(((s*)0)->f))
struct hkt_277576027
{
__int64 hkc_3;
long hkc_1;
unsigned short hkvdo[2];
};
struct hkis_27757602700002
{
long hkc_1;
};
struct hkif_27757602700002
{
long hkc_1;
};
unsigned short GetSerializeSize_277576027(
struct HkRow const* hkRow)
{
struct hkt_277576027 const* row = ((struct hkt_277576027 const*)hkRow);
return ((row->hkvdo)[1]);
}
HRESULT Serialize_277576027(
struct HkRow const* hkRow,
unsigned char* buffer,
unsigned short bufferSize,
unsigned short* copySize)
{
return (RowSerialize(hkRow, (GetSerializeSize_277576027(hkRow)), buffer, bufferSize, copySize));
}
HRESULT Deserialize_277576027(
struct HkTransaction* tx,
struct HkTable* table,
unsigned char const* data,
unsigned short datasize,
struct HkRow** hkrow)
{
return (RowDeserialize(tx, table, data, datasize, sizeof(struct hkt_277576027), (sizeof(struct hkt_277576027) + 200), hkrow));
}
unsigned short GetSerializeRecKeySize_277576027(
struct HkRow const* hkRow)
{
struct hkt_277576027 const* row = ((struct hkt_277576027 const*)hkRow);
unsigned short size = sizeof(struct hkif_27757602700002);
return size;
}
HRESULT SerializeRecKey_27757602700002(
struct HkRow const* hkRow,
unsigned char* hkKey,
unsigned short bufferSize,
unsigned short* keySize)
{
struct hkt_277576027 const* row = ((struct hkt_277576027 const*)hkRow);
struct hkif_27757602700002* key = ((struct hkif_27757602700002*)hkKey);
(*keySize) = sizeof(struct hkif_27757602700002);
if ((bufferSize < (*keySize)))
{
return -2013265920;
}
(key->hkc_1) = (row->hkc_1);
return 0;
}
HRESULT DeserializeRecKey_277576027(
unsigned char const* data,
unsigned short dataSize,
struct HkSearchKey* key,
unsigned short bufferSize)
{
struct hkif_27757602700002 const* source = ((struct hkif_27757602700002 const*)data);
struct hkis_27757602700002* target = ((struct hkis_27757602700002*)key);
unsigned long targetSize = sizeof(struct hkis_27757602700002);
if ((targetSize > bufferSize))
{
return -2013265920;
}
(target->hkc_1) = (source->hkc_1);
return 0;
}
__int64 CompareSKeyToRow_27757602700002(
struct HkSearchKey const* hkArg0,
struct HkRow const* hkArg1)
{
struct hkis_27757602700002* arg0 = ((struct hkis_27757602700002*)hkArg0);
struct hkt_277576027* arg1 = ((struct hkt_277576027*)hkArg1);
__int64 ret;
ret = (CompareKeys_int((arg0->hkc_1), (arg1->hkc_1)));
return ret;
}
__int64 CompareRowToRow_27757602700002(
struct HkRow const* hkArg0,
struct HkRow const* hkArg1)
{
struct hkt_277576027* arg0 = ((struct hkt_277576027*)hkArg0);
struct hkt_277576027* arg1 = ((struct hkt_277576027*)hkArg1);
__int64 ret;
ret = (CompareKeys_int((arg0->hkc_1), (arg1->hkc_1)));
return ret;
}
unsigned long ComputeSKeyHash_27757602700002(
struct HkSearchKey const* hkArg)
{
struct hkis_27757602700002* arg = ((struct hkis_27757602700002*)hkArg);
unsigned long hashState = 0;
unsigned long hashValue = 0;
hashValue = (ComputeHash_int((arg->hkc_1), (&hashState)));
return hashValue;
}
unsigned long ComputeRowHash_27757602700002(
struct HkRow const* hkArg)
{
struct hkt_277576027* arg = ((struct hkt_277576027*)hkArg);
unsigned long hashState = 0;
unsigned long hashValue = 0;
hashValue = (ComputeHash_int((arg->hkc_1), (&hashState)));
return hashValue;
}
struct HkOffsetInfo const KeyOffsetArray_27757602700002[] =
{
{
offsetof(struct hkis_27757602700002, hkc_1),
0,
0,
},
};
struct HkKeyColsInfo const KeyColsInfoArray_277576027[] =
{
{
sizeof(struct hkis_27757602700002),
KeyOffsetArray_27757602700002,
sizeof(struct hkis_27757602700002),
sizeof(struct hkis_27757602700002),
},
};
struct HkOffsetInfo const OffsetArray_277576027[] =
{
{
offsetof(struct hkt_277576027, hkc_1),
0,
0,
},
{
(offsetof(struct hkt_277576027, hkvdo) + 0),
0,
0,
},
{
offsetof(struct hkt_277576027, hkc_3),
0,
0,
},
};
struct HkColsInfo const ColsInfo_277576027 =
{
sizeof(struct hkt_277576027),
OffsetArray_277576027,
KeyColsInfoArray_277576027,
};
struct HkHashIndexMD HashIndexMD_277576027[] =
{
{
2,
1,
1024,
CompareSKeyToRow_27757602700002,
CompareRowToRow_27757602700002,
ComputeSKeyHash_27757602700002,
ComputeRowHash_27757602700002,
},
};
struct HkTableMD TableMD =
{
sizeof(struct hkt_277576027),
(sizeof(struct hkt_277576027) + 200),
1,
HashIndexMD_277576027,
0,
0,
0,
(&ColsInfo_277576027),
277576027,
0,
GetSerializeSize_277576027,
Serialize_277576027,
Deserialize_277576027,
GetSerializeRecKeySize_277576027,
SerializeRecKey_27757602700002,
DeserializeRecKey_277576027,
};
__declspec(dllexport)
struct HkTableBindings g_Bindings =
{
277576027,
(&TableMD),
};
I cannot understand a single bit here, but this recalls memories when I was studying C & C++ in college 🙂
–> Final Cleanup
DROP PROCEDURE dbo.Test_NativelyCompiledStoredProcedure DROP TABLE dbo.Test_memoryOptimizedTable
Update: Know more about In-Memory tables:
Getting Started with Hekaton (Memory Optimized) tables | SQL Server 2014
Hekaton, which also means in-Memory or Memory Optimized Tables, is a Microsoft Code Project for its new version of SQL Server 2014. This version of SQL Server mainly focuses on the high performance In-Memory Database workloads. Which means this version includes Memory Optimized Tables which will reside into Server’s memory and efficiently provides execution of Business Logic by completely reducing I/O between Disk & Memory.
So, as soon as a Memory Optimized Table is created the data it contains will also load into Memory. Let’s see here a Hands-On with Hekaton Tables by simple T-SQL Scripts:
–> Let’s first create a Test Database:
USE [master] GO CREATE DATABASE [ManTest] CONTAINMENT = NONE ON PRIMARY ( NAME = N'ManTest', FILENAME = N'D:\SQLServer2014\MSSQL\DATA\ManTest.mdf', SIZE = 5120KB, FILEGROWTH = 1024KB ) LOG ON ( NAME = N'ManTest_log', FILENAME = N'D:\SQLServer2014\MSSQL\Log\ManTest_log.ldf', SIZE = 1024KB, FILEGROWTH = 10% ) GO
–> Now we will create a FileGroup and associate the [ManTest] Database with it:
USE [ManTest]
GO
-- Add MEMORY_OPTIMIZED_DATA filegroup to the database.
ALTER DATABASE [ManTest]
ADD FILEGROUP [ManTestFG] CONTAINS MEMORY_OPTIMIZED_DATA
GO
-- Add file to the MEMORY_OPTIMIZED_DATA filegroup.
ALTER DATABASE [ManTest]
ADD FILE
( NAME = ManTestFG_file1,
FILENAME = N'D:\SQLServer2014\MSSQL\DATA\Datasample_database_1') -- You might need to check and correct the path here.
TO FILEGROUP ManTestFG
GO
A SQL Server FileGroup is required to store memory_optimized_data in a SQL Server Database. As per MSDN this FileGroup will be used to guarantee durability of memory-resident data in the event of a server crash or restart. During the crash recovery phase in server startup, the data is recovered from this FileGroup and loaded back into memory.
–> Now we will create Memory Optimized Table with new Options added in CREATE TABLE syntax:
-- Create memory optimized table and hash indexes on the memory optimized table: CREATE TABLE dbo.Person_memoryOptimizedTable ( PersonID INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 19972), PersonName NVARCHAR(100) NOT NULL, DateAdded DATETIME NOT NULL ) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA) GO
The Options:
– NONCLUSTERED HASH WITH : Clustered Index not allowed (as indexes are not stored, but re-created after SQL Server is restarted), so a PK should be defined with NonClustered Index of Type ‘Hash’.
– BUCKET_COUNT : Indicates the number of buckets that should be created in the Hash index.
– MEMORY_OPTIMIZED=ON : makes the table Memory Optimized.
– DURABILITY = SCHEMA_AND_DATA : makes the Table and its Data available all the time in-Memory.
Note:
– Indexes can only be created online with CREATE TABLE statement.
– If you don’t provide the DURABILITY = SCHEMA_AND_DATA option, then the Data will be persisted in the Table only.
– The Option DURABILITY = SCHEMA_ONLY will not make the Table Data Durable on Disk and data will lost after Server Restart or Crash, but the Table Schema will be available.
–> Let’s insert some records in the table created above:
-- Inserting records into the Memory Optimized Table from [Person] table in [AdventureWorks] DB: INSERT INTO dbo.Person_memoryOptimizedTable SELECT [BusinessEntityID], CONCAT([FirstName], ' ', [MiddleName], ' ', [LastName]) AS PersonName, GETDATE() AS DateAdded FROM [AdventureWorks2012].[Person].[Person]
You will get following error:
Msg 41317, Level 16, State 3, Line 34
A user transaction that accesses memory optimized tables or natively compiled procedures cannot access more than one user database or databases model and msdb, and it cannot write to master.
This means that you cannot insert records into Memory Optimized Tables across databases.
So, we have a workaround here, we will insert records into a #temp table first and then insert from this #temp table.
-- So, I'll insert records from [AdvantureWorks] Database to #temp table first: SELECT [BusinessEntityID], CONCAT([FirstName], ' ', [MiddleName], ' ', [LastName]) AS PersonName, GETDATE() AS DateAdded into #tempPerson FROM [AdventureWorks2012].[Person].[Person] -- (19972 row(s) affected) -- Now, I can insert records from #temp table into the Memory Optimized Table: INSERT INTO dbo.Person_memoryOptimizedTable SELECT [BusinessEntityID], PersonName, DateAdded FROM #tempPerson -- (19972 row(s) affected) -- Let's check contents of the Table: SELECT * FROM Person_memoryOptimizedTable GO
So, we here saw how to create Memory Optimized Tables and create a Separate Database to store them by allocating a FileGroup to the DB.
-- Final Cleanup DROP TABLE dbo.Person_memoryOptimizedTable DROP TABLE #tempPerson GO USE master GO DROP DATABASE ManTest GO
Update: Know more about In-Memory tables:
Next post I’ll discuss more about Memory Optimized tables, their benefits and limitations.
Finally installed SQL Server 2014 CTP1
Last month I posted the availability of the first Community Test Preview (CTP-1) of SQL Server 2014, [link].
As mentioned officially by Microsoft this preview (CTP-1) should be installed on a fresh OS (Windows 8 or Server 2012) and not with existing Dev machine. So, some days back I finally managed to get an isolated machine and installed on it. The Installation is similar to SQL Server 2012, only difference is the version number till now.
After successful install on opening SSMS you will see following Splash Screen with 2014 branding:

.
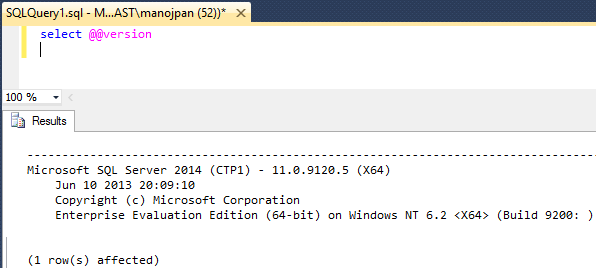
–> On checking the version by SQL statement you get:
.
–> On checking the “Tables” section on Object Explorer it gives you option to create “Memory Optimized Tables”:
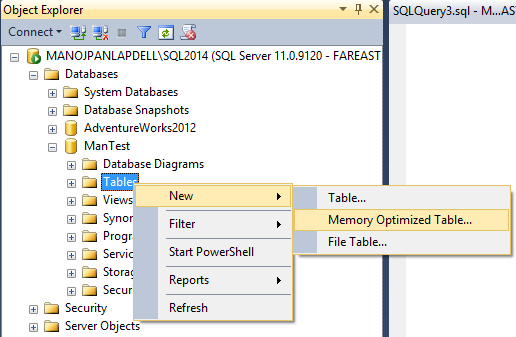
… but this is not graphical (like Create Table), it provides a Script template and opens it in SQL Query Editor.
.
–> On checking the “Stored Procedures” section on Object Explorer it gives you option to create “Natively Compiled Stored Procedures”:
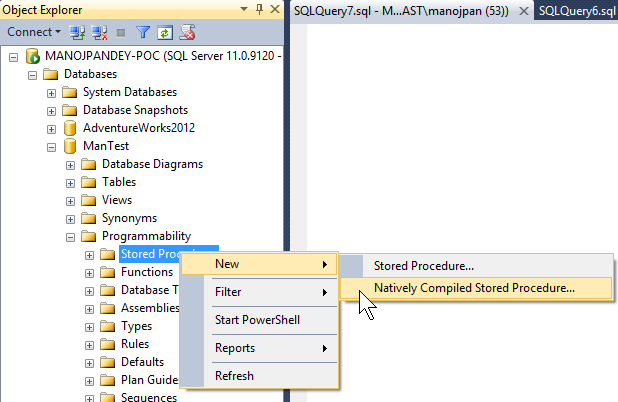
… and just like “Create Procedure” it also provides a Script template and opens it in SQL Query Editor.
Next post I’ll come with some hands-on with Creating a Database, Memory Optimized tables and new things introduced in SQL Server 2014.
SQL Server 2014 | New Features
Around 3 years back (~ Nov’2010) the first Community Test Preview (CTP-1) of SQL Server 2012 was released, and with great excitement I blogged about its new features and availability. Now after 3 years, last month-end (June’2013) the first Community Test Preview (CTP-1) of SQL Server 2014 is released, and with same great excitement here I’m with my similar blog post.
SQL Server 2014, this time mainly focuses on high performance in-Memory Operations for OLTP Databases by providing Memory Optimized Tables & Natively Compiled Stored Procedures. There is not much enhancement in T-SQL section, which was with SQL Server 2012. But with In-Memory features SQL Server 2014 has made a lot of impression and is definitely going to make a lot of impact.
Let’s see what all new features SQL Server 2014 is packed with:
.
>> Database Engine:
–> Memory-optimized tables: read more.
–> Natively Compiled Stored Procedures: read more.
-> AlwaysOn enhancements
– The maximum number of secondary replicas is increased from 4 to 8.
– When disconnected from the primary replica or during cluster quorum loss, readable secondary replicas now remain available for read workloads.
– Enhancements are made to increase the efficiency and ease of troubleshooting availability groups
– Failover cluster instances (FCIs) can now use Cluster Shared Volumes as cluster shared disks in Windows Server 2012 and above.
– The following three dynamic management views now return information for FCIs:
1. sys.dm_hadr_cluster (Transact-SQL)
2. sys.dm_hadr_cluster_members (Transact-SQL)
3. sys.dm_hadr_cluster_networks (Transact-SQL)
–> Managing the lock priority of online operations
Additional partition switching and index rebuild operations can now be performed while a table is online. The ONLINE = ON option now contains a WAIT_AT_LOW_PRIORITY option which permits you to specify how long the rebuild process should wait for the necessary locks.
–> Columnstore indexes
– Updateable Clustered Columnstore Indexes: can perform some insert, update, and delete operations, read more.
– SHOWPLAN displays information about columnstore indexes: The EstimatedExecutionMode and ActualExecutionMode properties have two possible values: Batch or Row. The Storage property has two possible values: RowStore and ColumnStore.
– Archival data compression: ALTER INDEX … REBUILD has a new COLUMNSTORE_ARCHIVE data compression option that further compresses the specified partitions of a columnstore index, read more.
–> Buffer pool extension
Provides the seamless integration of solid-state drives (SSD) as a nonvolatile random access memory (NvRAM) extension to the Database Engine buffer pool to significantly improve I/O throughput.
–> Query plans
Includes substantial improvements to the component that creates and optimized query plans.
–> Inline specification of CLUSTERED and NONCLUSTERED
Inline specification of CLUSTERED and NONCLUSTERED indexes is now allowed for disk-based tables.
–> SELECT … INTO
The SELECT … INTO statement is improved and can now operate in parallel.
–> Deployment Enhancements
Deploy a SQL Server Database to a Windows Azure Virtual Machine enables deployment of a SQL Server database to a Windows Azure VM, read more.
.
>> Analysis Services & BI
1. Updates to Design Tool installation
2. Features recently added: Power View for Multidimensional Models
… read more.
.
>> No Changes to Integration Services, Reporting Services & Replication
.
You can know more about the CTP-1 version from my previous blog post. This post provides the Download Link, Install Prerequisites, Limitations, etc for the beta product.


![]()
Current Visitors

StatCounter …since April 2012

 Leisure blog: Creek & Trails
Leisure blog: Creek & Trails
- NMDC Hyderabad Marathon – My first 42k FM, cramps, training and fuelling
- Singapore (Part 2) – 6 days itinerary, sightseeing & attractions
- Singapore (Part 1) – Tickets, Visa, Hotel, Forex Card/Cash, Metro/Bus cards
- I got full refund of my flight tickets during COVID lockdown (AirIndia via MakeMyTrip)
- YouTube – Your Google Ads account was cancelled due to no spend
- YouTube latest update on its YPP (YouTube Partner Program) which may affect your channel
- Starting your own blog !!!
- How to file ITR (Income Tax Return) online AY 2017-18 (for simple salaried)
- Scam – Become a kin/hier and earn a fortune – via LinkedIn and Email
- Places to visit in and around Vizag (aka Visakhapatnam)
