Archive
SQL Server 2025 Private Preview – Built-in AI, Fabric connectivity, Native JSON, and many more…
On 19th November 2024 Microsoft announced the Private Preview of SQL Server upcoming version i.e. SQL Server 2025 !!!
This v-Next version emphasizes modern AI and Generative AI (GenAI) capabilities powered by Microsoft Copilot and contemporary Large Language Models (LLMs). These capabilities align with the latest advancements in GenAI, such as OpenAI’s ChatGPT, Meta’s Llama, etc. It also integrates Semantic Kernel, LangChain, and Retrieval-Augmented Generation (RAG) functionalities, positioning it as an enterprise-ready AI database !!!
>> Built-in AI:
– SQL Server 2025 will be having Vector Database capabilities
— New native Vector datatype
— Vector search capabilities by using new vector functions VECTOR_DISTANCE() for calculating euclidean, cosine, and negative dot distance between two vectors.
— Vector index powered by DiskANN (Disk based Approximate Nearest Neighbor)
— I will be posting more about this topic in my upcoming blogs…
– Can call REST APIs with sp_invoke_external_rest_endpoint system Stored Procedure for calling LLMs
– Semanic Kernel integration, for semantic search capabilities for more intuitive data retrieval and analysis
– LangChain integration, by enabling seamless interaction between natural language queries and structured database operations
>> Fabric Mirroring:
– Mirroring replicates databases to Fabric with zero ETL
– Data is replicated into One Lake and kept up-to-date in near real-time
– Mirroring protects operational databases from analytical queries
– Compute replication is included with your Fabric capacity for no cost.
– Free Mirroring Storage for Replicas tiered to Fabric Capacity.
>> Other Database engine new features:
– Native JSON datatype, index, and functions
– Regular Expression (Regex) support, with new functions used at CHECK constraint, WHERE clause, SELECT list
– Copilot/GenAI in SSMS (Ver 21) for SQL query/code completions and recommendations
– Enhancements in Performance and Scalability
– Optimized locking for reducing memory lock consumption and minimizing concurrent transactions blocking through Transaction ID (TID) Locking and Lock After Qualification (LAQ)
– Real time event streaming to Azure Event Hubs and Kafka, by capturing and publishing incremental changes to data and schema
>> SQL Server setup – Feature selection:

Signup for the SQL Server 2025 Private Preview program here: https://aka.ms/sqleapsignup
>> References:
– https://www.microsoft.com/en-us/sql-server/blog/2024/11/19/announcing-microsoft-sql-server-2025-apply-for-the-preview-for-the-enterprise-ai-ready-database/
– https://www.linkedin.com/pulse/announcing-sql-server-2025-bob-ward-6s0hc/
– https://ignite.microsoft.com/en-US/sessions/BRK195
Reading JSON string with Nested array of elements | SQL Server 2016 – Part 3
In my [previous post] I discussed about how to Import or Read a JSON string and convert it in relational/tabular format in row/column from.
Today in this post I’ll talk about how to read/parse JSON string with nested array of elements, just like XML.
Native JSON support in SQL Server 2016 provides you few functions to read and parse your JSON string into relational format and these are:
– OPENJSON() Table valued function: parses JSON text and returns rowset view of JSON.
– JSON_Value() Scalar function: returns a value from JSON on the specified path.
We will see usage of both the functions in our example below:
Here, we have just one nested element, and the OPENJSON() function will get you the child elements values:
–> Method #1.a. Using OPENJSON() function:
DECLARE @json NVARCHAR(1000)
SELECT @json =
N'{
"OrderHeader": [
{
"OrderID": 100,
"CustomerID": 2000,
"OrderDetail":
{
"ProductID": 2000,
"UnitPrice": 350
}
}
]
}'
SELECT
OrderID,
CustomerID,
[OrderDetail.ProductID] AS ProductID,
[OrderDetail.UnitPrice] AS UnitPrice
FROM OPENJSON (@json, '$.OrderHeader')
WITH (
OrderID INT,
CustomerID INT,
[OrderDetail.ProductID] INT,
[OrderDetail.UnitPrice] INT
) AS Orders
OrderID CustomerID ProductID UnitPrice 100 2000 2000 350
But, if you have more than one nested elements the same query will give just 1 row with NULL values under the child columns, like this.
–> Method #1.b. In case of multiple child elements:
DECLARE @json NVARCHAR(1000)
SELECT @json =
N'{
"OrderHeader": [
{
"OrderID": 100,
"CustomerID": 2000,
"OrderDetail": [
{
"ProductID": 2000,
"UnitPrice": 350
},
{
"ProductID": 3000,
"UnitPrice": 450
}
]
}
]
}'
SELECT
OrderID,
CustomerID,
[OrderDetail.ProductID] AS ProductID,
[OrderDetail.UnitPrice] AS UnitPrice
FROM OPENJSON (@json, '$.OrderHeader')
WITH (
OrderID INT,
CustomerID INT,
[OrderDetail.ProductID] INT,
[OrderDetail.UnitPrice] INT
) AS Orders
OrderID CustomerID ProductID UnitPrice 100 2000 NULL NULL
You might be expecting 2 rows with same OrderID & CustomerID, with different ProductID & UnitPrice, right?
Instead you get ProductID & UnitPrice column values as NULL. Because, here you are having array of child elements with OrderDetail node (notice the square-bracket after “OrderDetail”: node), thus the Query is not able to find the key on the path.
In this case what you have to do is, use the array positions with square brackets (“[” and “]”) in your query and call out separate columns for each child element, like below:
DECLARE @json NVARCHAR(1000)
SELECT @json =
N'{
"OrderHeader": [
{
"OrderID": 100,
"CustomerID": 2000,
"OrderDetail": [
{
"ProductID": 2000,
"UnitPrice": 350
},
{
"ProductID": 3000,
"UnitPrice": 450
}
]
}
]
}'
SELECT
OrderID,
CustomerID,
[OrderDetail[0]].ProductID] AS ProductID1,
[OrderDetail[0]].UnitPrice] AS UnitPrice1,
[OrderDetail[1]].ProductID] AS ProductID2,
[OrderDetail[1]].UnitPrice] AS UnitPrice2
FROM OPENJSON (@json, '$.OrderHeader')
WITH (
OrderID INT,
CustomerID INT,
[OrderDetail[0]].ProductID] INT,
[OrderDetail[0]].UnitPrice] INT,
[OrderDetail[1]].ProductID] INT,
[OrderDetail[1]].UnitPrice] INT
) AS Orders
OrderID CustomerID ProductID1 UnitPrice1 ProductID2 UnitPrice2 100 2000 2000 350 3000 450
You can also specify the child elements with full path by using the dollar sign “$” inside the WITH() clause (instead at column level above), like below:
–> Method #2. Using OPENJSON() function:
DECLARE @json NVARCHAR(1000)
SELECT @json =
N'{
"OrderHeader": [
{
"OrderID": 100,
"CustomerID": 2000,
"OrderDetail": [
{
"ProductID": 2000,
"UnitPrice": 350
},
{
"ProductID": 3000,
"UnitPrice": 450
}
]
}
]
}'
SELECT
OrderID,
CustomerID,
ProductID1,
UnitPrice1,
ProductID2,
UnitPrice2
FROM OPENJSON (@json, '$.OrderHeader')
WITH (
OrderID INT '$.OrderID',
CustomerID INT '$.CustomerID',
ProductID1 INT '$.OrderDetail[0].ProductID',
UnitPrice1 INT '$.OrderDetail[0].UnitPrice',
ProductID2 INT '$.OrderDetail[1].ProductID',
UnitPrice2 INT '$.OrderDetail[1].UnitPrice'
) AS Orders
OrderID CustomerID ProductID1 UnitPrice1 ProductID2 UnitPrice2 100 2000 2000 350 3000 450
Ok, so by using the key path and the array position we can get the child elements value in our Query result-set by using above 2 methods.
But instead of having them in separate columns how about pulling them in separate rows, this will also make your query dynamic as you would not know the number of child-elements before hand, right?
This can be done by CROSS APPLYing the JSON child node with the parent node and using the JSON_Value() function, like shown below:
–> Method #3. Using JSON_Value() with OPENJSON() function:
DECLARE @json NVARCHAR(1000)
SELECT @json =
N'{
"OrderHeader": [
{
"OrderID": 100,
"CustomerID": 2000,
"OrderDetail": [
{
"ProductID": 2000,
"UnitPrice": 350
},
{
"ProductID": 3000,
"UnitPrice": 450
},
{
"ProductID": 4000,
"UnitPrice": 550
}
]
}
]
}'
SELECT
JSON_Value (c.value, '$.OrderID') as OrderID,
JSON_Value (c.value, '$.CustomerID') as CustomerID,
JSON_Value (p.value, '$.ProductID') as ProductID,
JSON_Value (p.value, '$.UnitPrice') as UnitPrice
FROM OPENJSON (@json, '$.OrderHeader') as c
CROSS APPLY OPENJSON (c.value, '$.OrderDetail') as p
OrderID CustomerID ProductID UnitPrice 100 2000 2000 350 100 2000 3000 450 100 2000 4000 550
Ok, that’s it for today.
In my [next post] I’ll talk about storing JSON string in a table and doing some hands-on with it.
Import/Read a JSON string and convert it in tabular (row/column) form | SQL Server 2016 – Part 2
In my [previous post] I discussed on how to format/convert any Query/Table data to a string in JSON format. JSON in SQL Server was limited to this feature only till the CTP 2 version.
But now with the CTP 3 release you can do reverse of it also, means now you can read back JSON data and convert it to tabular or row & column format.
Let’s check this by taking same sample data from our previous JSON-Export post.
DECLARE @json NVARCHAR(1000)
SELECT @json = N'{"StudList":
[
{
"ID":1,
"FirstName":"Manoj",
"LastName":"Pandey",
"Class":10,
"Marks":80.5
},
{
"ID":2,
"FirstName":"Saurabh",
"LastName":"Sharma",
"Class":11,
"Marks":82.7
},
{
"ID":3,
"FirstName":"Kanchan",
"LastName":"Pandey",
"Class":10,
"Marks":90.5
},
{
"ID":4,
"FirstName":"Rajesh",
"LastName":"Shah",
"Class":11,
"Marks":70.3
},
{
"ID":5,
"FirstName":"Kunal",
"LastName":"Joshi",
"Class":12,
"Marks":64.7
}
]'
SELECT ID, FirstName, LastName, Class, Marks
FROM OPENJSON (@json, '$.StudList')
WITH (
ID INT,
FirstName VARCHAR(255),
LastName VARCHAR(255),
Class INT,
Marks DECIMAL(3,1)
) AS StudList
– Output:

Well, that was simple, isn’t it!!!
In my [next post] I’ll talk about Nested Properties in a JSON string with single and multiple elements.
Native JSON support – new feature in SQL Server 2016
In my [previous blog post] on “SQL Server 2016 Enhancements” we discussed about the new features coming in. Native JSON support is on of those feature that will help you support and manage NoSQL/Unstructured document data within a SQL Server database.
–> JSON (or JavaScript Object Notation) is a popular, language-independent, lightweight data-interchange format used in modern web and mobile applications, as well for storing Unstructured data. JSON is an alternate to XML and is more compact than that format, and thus has become the first choice for many applications that need to move data around on the web. One of the biggest reasons JSON is becoming more important than XML is that XML has to be parsed with an XML parser, while JSON can be parsed by a standard JavaScript function. This makes it easier and faster than working with XML.
For more details on JSON check at json.org
–> JSON in SQL Server 2016 is not treated as a separate Datatype by the DB Engine, like XML. For example, appending FOR JSON AUTO to a standard SELECT statement returns the result set in a JSON format. The JSON data is stored as NVARCHAR type, unlike XML datatype for XML data, thus JSON will be supported wherever NVARCHAR is supported.
–> Here is a sample & simple query to convert a row-set into a JSON format:
SELECT TOP 10
M.ProductModelID,
M.Name AS [ProductModel.Name],
ProductID,
P.Name AS [Product.Name],
ProductNumber,
MakeFlag
FROM Production.Product P
INNER JOIN Production.ProductModel M
ON P.ProductModelID = M.ProductModelID
FOR JSON PATH, ROOT('ProductModel') -- here, JSON syntax similar to XML
Check the last line, the syntax is almost similar to XML datatype. So, if you familiar with XML syntax in T-SQL, working with JSON will be a seamless experience.
Check my [next post] on how to work with JSON string with SQL queries.
Check this video on how to work with JSON and SQL:
–> More from MS BoL and whitepapers on JSON support:
JSON syntax is simple and human-readable. JSON values consist of name/value pairs, and individual values are separated by commas. Objects are containers of one or more name/value pairs and are contained within curly brackets. JSON arrays can contain multiple objects, and arrays are contained within square brackets.
JSON is the storage format used in several NoSQL engines, including Azure DocumentDB. DocumentDB uses Azure Blob storage to store schema-less documents, but provides a rich SQL query dialect that allows you to conduct SQL queries over the data contained in the documents. In addition to DocumentDB, Azure Search also utilizes JSON. Azure Search is a fully managed search solution that allows developers to embed sophisticated search experiences into web and mobile applications without having to worry about the complexities of full-text search and without having to deploy, maintain, or manage any infrastructure.
The combination of SQL Server’s new support for JSON with these other Microsoft tools enables many scenarios for moving data back and forth between relational and schema-less storage and the applications that access such data. For example, these tools would allow you to set up periodical extractions of relational data in SQL Server, transforming the data into JSON and loading it to a JSON-based Azure DocumentDB storage that is searchable from a mobile device, along with data from many other sources, utilizing Azure Search.
Check more on [MSDN BoL] for JSON support in SQL Server 2016.
Microsoft announced SQL Server 2016 – New features and enhancements
On Monday, 4th May 2015 Microsoft at Ignite event announced the new version of SQL Server i.e. SQL Server 2016, which will be available for Public Preview this summer.
>> MSDN Blog announcement: http://blogs.technet.com/b/dataplatforminsider/archive/2015/05/04/sql-server-2016-public-preview-coming-this-summer.aspx
>> Microsoft SQL Server 2016 official page: https://www.microsoft.com/en-us/server-cloud/products/sql-server-2016
This version of SQL Server is going to be a major release with new features and will also overcome some limitations of SQL Server 2014.
-> New Performance Enhancements:
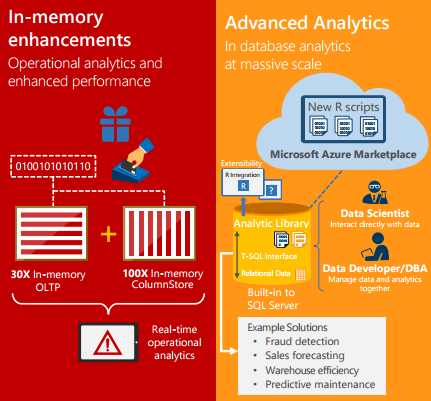
– In-memory OLTP enhancements: Greater T-SQL surface area, terabytes of memory supported and greater number of parallel CPUs, provide up to 30x faster Transactions, more than 100x faster Queries than disk-based relational databases and Real-time Operational Analytics, Demo video.
– Query Data Store: Monitor and optimize query plans with full history of query execution.
– Native JSON: Parsing & storing of JSON as relational data & exporting relational data to JSON, as it is becoming a popular format to store NoSQL/Unstructured data, Demo video.
–> Security Upgrades:
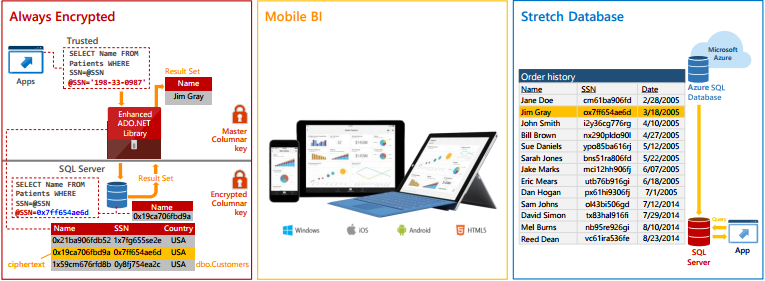
– Always Encrypted: Help protect data at rest and in motion with the master key residing with the application & no application changes required.
– Row Level Security: Customers can implement Row-level Security on databases to enable implementation of fine-grained access control over rows in a database table for greater control over which users can access which data, demo video.
– Dynamic Data Masking: Real-time obfuscation of data to prevent unauthorized access, demo video.
–> Even Higher Availability, with Enhanced AlwaysOn:
– Up to 3 synchronous replicas for auto failover across domains, for more robust High Availability and Disaster Recovery
– Round-robin load balancing of replicas
– DTC & SSIS support
– Automatic failover based on database health
–> Hybrid Cloud Solution:
– Stretch Database: Stretch operational tables in a secure manner into Azure for cost effective historic data availability, that lets you dynamically stretch your warm and cold transactional data to Microsoft Azure, demo video.
– Azure Data Factory integration with SSIS
–> Deeper Insights Across Data
– PolyBase: Manage relational & non-relational data with the simplicity of T-SQL.
– Enhanced SSIS: Designer support for previous SSIS versions and support for Power Query.
– Built-in Advanced Analytics: Bringing predictive analytic algorithms directly into SQL Server.
>> Check the SQL Server 2016 Datasheet here for more information on this: http://download.microsoft.com/download/F/D/3/FD33C34D-3B65-4DA9-8A9F-0B456656DE3B/SQL_Server_2016_datasheet.pdf
–> YouTube Videos on SQL Server 2016:


![]()
Current Visitors

StatCounter …since April 2012

 Leisure blog: Creek & Trails
Leisure blog: Creek & Trails
- NMDC Hyderabad Marathon – My first 42k FM, cramps, training and fuelling
- Singapore (Part 2) – 6 days itinerary, sightseeing & attractions
- Singapore (Part 1) – Tickets, Visa, Hotel, Forex Card/Cash, Metro/Bus cards
- I got full refund of my flight tickets during COVID lockdown (AirIndia via MakeMyTrip)
- YouTube – Your Google Ads account was cancelled due to no spend
- YouTube latest update on its YPP (YouTube Partner Program) which may affect your channel
- Starting your own blog !!!
- How to file ITR (Income Tax Return) online AY 2017-18 (for simple salaried)
- Scam – Become a kin/hier and earn a fortune – via LinkedIn and Email
- Places to visit in and around Vizag (aka Visakhapatnam)
