Archive
Informatica – WRT_8229, Multiple-step OLE DB operation generated errors. Check each OLE DB status value, if available. No work was done.
Working with Informatica is fun, but challenging at times, don’t know if this is the same other ETL tools, like SSIS, etc.
Today, while running a Workflow I was getting an error on a session, and due to this the rows were not getting inserted from Source to Target table. The error is as follows:
Severity: ERROR
Timestamp: 1/25/2016 3:37:43 PM
Node: node03_AZxyzxyzxyzxyz
Thread: WRITER_1_*_1
Process ID: 7180
Message Code: WRT_8229
Message: Database errors occurred: Microsoft OLE DB Provider for SQL Server: Multiple-step OLE DB operation generated errors. Check each OLE DB status value, if available. No work was done.
Database driver error…
Function Name : Execute Multiple
SQL Stmt : INSERT INTO dbo.Contact (Id,Name,Description,CreatedBy,CreatedOn,ModifiedBy,ModifieOn,RowCheckSum) VALUES ( ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)

I check all the place and at last found that the last column “RowCheckSum” as mentioned in the error above, was not present in my Target table.
So, I just went ahead and added this column with simple “ALTER TABLE ADD COLUMN” statement.
And post this fix, my Workflow ran without any issues, and I got the table populated as expected.
Informatica – There is no Integration Service found for this workflow (error)
Today while executing a new Informatica Workflow that I designed I got a pop-up with following error message:
“There is no Integration Service found for this workflow”

The Workflow was not getting kicked off and there was nothing else showing up other than the error message box.
Thus, I did a bit research and as the error message indicates found that the Workflow needs to be linked to an Integration Service so that the data movement could be enabled from Source to the Target.
The Informatica Integration Service (or infasvcs) acts as a controller for entire workflow execution. Integration Service gets into action whenever a workflow is kicked off (either manually or by schedule). It reads Workflow, Session/Task and Mapping information from Repository Database and performs the execution as per transformations defined.
–> Right-click on the Workflow Designer and this opens up following window, which shows the Integration Service text box empty, below:

… you just need to click on the button adjacent to it (circled, above), which opens up following window:
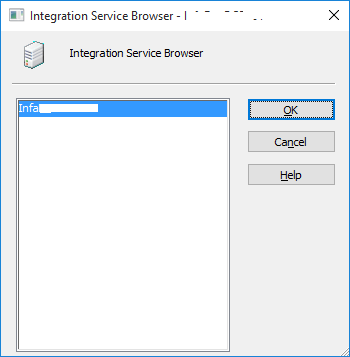
… here, you just need to select the Integration Services listed and click OK. Post this you will see the text box populated with the Integration Service name.
–> But if you want this to be assigned for more than one Workflow or to be executed with different Integration Service than you can go with this approach:
Close all the Workflow Folders.
And in main-menu click Services –> Assign Integration Service

… this will open following window below, and here you can select more than one Workflow and select Integration Services for them:

How to import/store photos with file name and other properties into SQL Server table – MSDN TSQL forum
–> Question:
I was tasked to load several thousand of photos into the SQL Server. Those photos are saved in a specific folder. I want to store the file name in one column and the photo in another column. It would take month for me to enter one by one.
Is there a way to loop through a given folder and add the file name and photo into the tables using TSQL?
–> Answer:
If you are on SQL Server 2012 and ahead, you can use FileTables feature, which is built on top of FileStream and very easy to implement.
FileTable feature does not store files (or images in your case) in SQL Database, but in a secure Windows File-System location which is only visible via SSMS.
Check my blog post on FileTables: https://sqlwithmanoj.com/2012/02/28/sql-server-2012-a-k-a-denali-new-feature-filetables/
After implementing FileTables feature you just need to copy-paste all these images or any kind of file on this folder and you are done.
The retrieval of data is very easy and you get all the properties stored in the metadata files.
Ref link.
Parse or Query XML column with XMLNAMESPACES (xmlns namespace) – MSDN TSQL forum
–> Question:
We have SQL audit information.
We would like to select XML column in some user friendly way.
CREATE TABLE [dbo].[audit](
[server_instance_name] [NVARCHAR](128) NULL,
[statement] [NVARCHAR](4000) NULL,
[additional_information] XML NULL
)
INSERT INTO [dbo].[audit]([server_instance_name],[statement],[additional_information])
VALUES('srv1','sp_addlinkedsrvlogin','')
INSERT INTO [dbo].[audit]([server_instance_name],[statement],[additional_information])
VALUES('srv2','','<action_info xmlns="http://schemas.microsoft.com/sqlserver/2008/sqlaudit_data"><session><![CDATA[Audit$A]]></session><action>event enabled</action><startup_type>manual</startup_type><object><![CDATA[audit_event]]></object></action_info>')
SELECT * FROM [dbo].[audit]
Output of the XML column:

Required Output:

–> Answer:
;WITH XMLNAMESPACES('http://schemas.microsoft.com/sqlserver/2008/sqlaudit_data' as ns)
SELECT
[server_instance_name]
,[statement]
,[additional_information]
,t.c.value ('ns:session[1]', 'varchar(50)') AS session
,t.c.value ('ns:action[1]', 'varchar(50)') AS action
,t.c.value ('ns:startup_type[1]', 'varchar(50)') AS startup_type
,t.c.value ('ns:object[1]', 'varchar(50)') AS object
FROM [audit] as a
OUTER APPLY a.additional_information.nodes('//ns:action_info') as t(c)
GO
-- OR --
;WITH XMLNAMESPACES(DEFAULT 'http://schemas.microsoft.com/sqlserver/2008/sqlaudit_data')
SELECT
[server_instance_name]
,[statement]
,t.c.value ('session[1]', 'varchar(50)') AS session
,t.c.value ('action[1]', 'varchar(50)') AS action
,t.c.value ('startup_type[1]', 'varchar(50)') AS startup_type
,t.c.value ('object[1]', 'varchar(50)') AS object
FROM [audit] as a
OUTER APPLY a.additional_information.nodes('//action_info') as t(c)
GO
Drop table finally
DROP TABLE [audit] GO
Ref link.
SQL Trivia – Difference between COUNT(*) and COUNT(1)
Yesterday I was having a discussion with one of the Analyst regarding an item we were going to ship in the release. And we tried to check and validate the data if it was getting populated correctly or not. To just get the count-diff of records in pre & post release I used this Query:
SELECT COUNT(*) FROM tblXYZ
To my surprise he mentioned to use COUNT(1) instead of COUNT(*), and the reason he cited was that it runs faster as it uses one column and COUNT(*) uses all columns. It was like a weird feeling, what to say… and I just mentioned “It’s not, and both are same”. He was adamant and disagreed with me. So I just kept quite and keep on using COUNT(*) 🙂
But are they really same or different? Functionally? Performance wise? or by any other means?
Let’s check both of them.
The MSDN BoL lists the syntax as COUNT ( { [ [ ALL | DISTINCT ] expression ] | * } )
So, if you specify any numeric value it come under the expression option above.
Let’s try to pass the value as 1/0, if SQL engine uses this value it would definitely throw a “divide by zero” error:
SELECT COUNT(1/0) FROM [Person].[Person]
… but it does not. Because it just ignores the value while taking counts. So, both * and 1 or any other number is same.
–> Ok, let’s check the Query plans:

and there was no difference between the Query plans created by them, both have same query cost of 50%.
–> These are very simple and small queries so the above plan might be trivial and thus may have come out same or similar.
So, let’s check more, like the PROFILE stats:
SET STATISTICS PROFILE ON SET STATISTICS IO ON SELECT COUNT(*) FROM [Sales].[SalesOrderDetail] SELECT COUNT(1) FROM [Sales].[SalesOrderDetail] SET STATISTICS PROFILE OFF SET STATISTICS IO OFF
If you check the results below, the PROFILE data of both the queries shows COUNT(*), so the SQL engine converts COUNT(1) to COUNT(*) internally.
SELECT COUNT(*) FROM [Sales].[SalesOrderDetail]
|--Compute Scalar(DEFINE:([Expr1002]=CONVERT_IMPLICIT(int,[Expr1003],0)))
|--Stream Aggregate(DEFINE:([Expr1003]=Count(*)))
|--Index Scan(OBJECT:([AdventureWorks2014].[Sales].[SalesOrderDetail].[IX_SalesOrderDetail_ProductID]))
SELECT COUNT(1) FROM [Sales].[SalesOrderDetail]
|--Compute Scalar(DEFINE:([Expr1002]=CONVERT_IMPLICIT(int,[Expr1003],0)))
|--Stream Aggregate(DEFINE:([Expr1003]=Count(*)))
|--Index Scan(OBJECT:([AdventureWorks2014].[Sales].[SalesOrderDetail].[IX_SalesOrderDetail_ProductID]))
–> On checking the I/O stats there is no difference between them:
Table 'SalesOrderDetail'. Scan count 1, logical reads 276, physical reads 1, read-ahead reads 288, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'SalesOrderDetail'. Scan count 1, logical reads 276, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Both the queries does reads of 276 pages, no matter they did logical/physical/read-ahead reads here. Check difference b/w logical/physical/read-ahead reads.
So, we can clearly and without any doubt say that both COUNT(*) & COUNT(1) are same and equivalent.
There are few other things in SQL Server that are functionally equivalent, like DECIMAL & NUMERIC datatypes, check here: Difference b/w DECIMAL & NUMERIC datatypes.


![]()
Current Visitors

StatCounter …since April 2012

 Leisure blog: Creek & Trails
Leisure blog: Creek & Trails
- NMDC Hyderabad Marathon – My first 42k FM, cramps, training and fuelling
- Singapore (Part 2) – 6 days itinerary, sightseeing & attractions
- Singapore (Part 1) – Tickets, Visa, Hotel, Forex Card/Cash, Metro/Bus cards
- I got full refund of my flight tickets during COVID lockdown (AirIndia via MakeMyTrip)
- YouTube – Your Google Ads account was cancelled due to no spend
- YouTube latest update on its YPP (YouTube Partner Program) which may affect your channel
- Starting your own blog !!!
- How to file ITR (Income Tax Return) online AY 2017-18 (for simple salaried)
- Scam – Become a kin/hier and earn a fortune – via LinkedIn and Email
- Places to visit in and around Vizag (aka Visakhapatnam)
