Archive
SQL DBA – Quickly Clone a Database in SQL Server (2016 SP1 & 2014 SP2) with DBCC CLONEDATABASE command
Have you ever been in a similar situation where your PROD database size is in GBs or TBs, and for a code-release validation or some performance-fix you need to restore it on an Dev or Test server? You know that taking backup & restore will take lot of time, but you have no other option.
We also face this many a times as our PROD database size ranges from 500 GB to 1-2 TB, and we end up waiting 4-5 hrs in this activity.
There are even third party tools, but they also take good time and have their own pros & cons.
Now SQL Server brings a new feature with SQL Server 2016 SP1 & 2014 SP2, i.e. DBCC CLONEDATABASE, to create a new database clone of an existing database within seconds. The new cloned database created is ReadOnly, with no data, but with Statistics.
With DBCC CLONEDATABASE feature you can generate a clone of a database in order to investigate a performance issue related to a Query or Workload.
Note: As best practice suggested by Microsoft product team this clone Database is not supposed to remain in PROD database, but can be moved to a Dev or Test box for further troubleshooting and diagnostic purposes.
–> Syntax:
DBCC CLONEDATABASE (source_db_name, target_clone_db_name)
[WITH [NO_STATISTICS][,NO_QUERYSTORE]]
–> The above statement creates Clone of the source database in following operations:
1. Validate the source database.
2. Get S lock for the source database.
3. Create snapshot of the source database.
4. Create an empty database by inheriting from “model” database, and using the same file layout as the source but with default file sizes as the “model” database.
5. Get X lock for the clone database.
6. Copies the system metadata from the source to the destination database.
7. Copies all schema for all objects from the source to the destination database.
8. Copies statistics for all indexes from the source to the destination database.
9. Release all DB locks.
–> Now let’s create a Clone Database on AdvantureWorks database:
-- With Stats
DBCC CLONEDATABASE ('AdventureWorks2014', 'AdventureWorks2014_CloneDB')
Message:
Database cloning for ‘AdventureWorks2014’ has started with target as ‘AdventureWorks2014_CloneDB’.
Database cloning for ‘AdventureWorks2014’ has finished. Cloned database is ‘AdventureWorks2014_CloneDB’.
Database ‘AdventureWorks2014_CloneDB’ is a cloned database. A cloned database should be used for diagnostic purposes only and is not supported for use in a production environment.
DBCC execution completed. If DBCC printed error messages, contact your system administrator.
–> I’ll create one more Clone Database without Stats:
-- Without Stats
DBCC CLONEDATABASE ('AdventureWorks2014', 'AdventureWorks2014_CloneDB_No_Stats')
WITH NO_STATISTICS, NO_QUERYSTORE

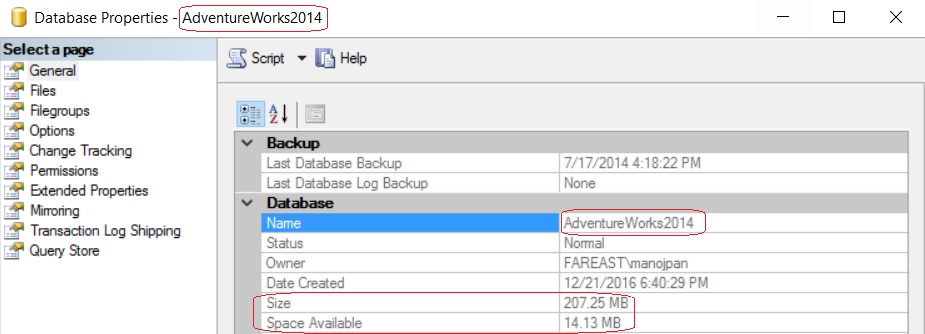
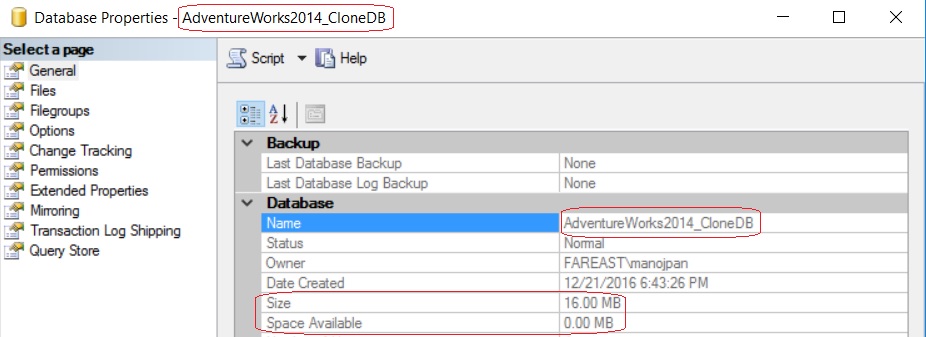
–> Let’s check the file size of all 3 Databases:
– The 1st image shows the size of original AdventureWorks2014 database i.e. 207 MB
– And 2nd and 3rd shows the size of other two Clone Databases i.e. just 16 MB.

–> Now we will check the Execution Plans of a query on all these three databases:
-- Check Execution plan on below T-SQL query in all 3 databases: SELECT P.BusinessEntityID, P.Title, P.FirstName, P.MiddleName, P.LastName, E.BirthDate, E.Gender, E.HireDate, E.JobTitle, E.MaritalStatus, D.Name FROM [Person].[Person] P INNER JOIN [HumanResources].[Employee] E ON E.BusinessEntityID = P.BusinessEntityID CROSS APPLY ( SELECT TOP 1 DepartmentID FROM [HumanResources].[EmployeeDepartmentHistory] DH WHERE DH.BusinessEntityID = E.BusinessEntityID ORDER BY StartDate DESC) EDH INNER JOIN [HumanResources].[Department] D ON D.DepartmentID = EDH.DepartmentID
– On executing the above query on original AdventureWorks2014 database & AdventureWorks2014_CloneDB it shows same execution plan, like it shows:
1. Hash Match operator
2. 72% cost on Person PK
3. 18% cost on EmployeeDepartmentHistory PK

(click on the image to expand)
– But on executing the same query on AdventureWorks2014_CloneDB_No_Stats it shows different execution plan, here it shows:
1. Nested Loop operator
2. 92% cost on Person PK
3. 5% cost on EmployeeDepartmentHistory PK

(click on the image to expand)
Now “CREATE OR ALTER” Stored Procedure, Function, View, Trigger with SQL Server 2016
SQL Server 2016 release was packed with lot of new features, and I tried to cover most of them, [check here]. This includes some of the major new features like, Polybase, Temporal Tables, JSON support, Stretch DB, Row Level Security, Dynamic data Masking, etc. are very unique to the other Database systems in competition.
But Microsoft’s SQL Server team also keeps on adding few features in every release which were already there in other Database systems, so that developers could use those and make their life easier, like the new IF EXISTS option with DROP & ALTER statements I already discussed in my [previous post].
Now, with the recent Service Pack 1, one more feature has been added, which developers (mainly from the Oracle background) were missing from long time, and that is CREATE OR ALTER option while creating programming modules, like:
1. Stored Procedures (SP)
2. Functions (UDFs)
3. Views
4. Triggers
–> Now you can create a new Stored Procedure without checking its existence, simply by using the new CREATE OR ALTER option, like below:
CREATE OR ALTER PROCEDURE dbo.spgetEmployeeDetails @EmpID INT AS BEGIN SELECT BusinessEntityID, Title, FirstName, MiddleName, LastName FROM Person.Person WHERE BusinessEntityID = @EmpID END GO
… you can execute the above code multiple times and it won’t fail. First time this CREATEs the SP, next time it will ALTER it.
–> Previously you need to add an IF EXISTS() condition to check if the SP already exists or not. If exists then drop and then create a new SP, like:
IF EXISTS(SELECT * FROM INFORMATION_SCHEMA.ROUTINES WHERE ROUTINE_NAME = 'spgetEmployeeDetails') DROP PROCEDURE dbo.spgetEmployeeDetails GO CREATE PROCEDURE dbo.spgetEmployeeDetails @EmpID INT AS BEGIN SELECT BusinessEntityID, Title, FirstName, MiddleName, LastName FROM Person.Person WHERE BusinessEntityID = @EmpID END GO
SQL Server 2016 1st Service Pack (SP1) is out (download, new features & enhancements)
Almost 6 months back i.e. on 1st June 2016 Microsoft released SQL Server 2016 RTM, i.e. full and final version, which you can [check and download here].
Yesterday (i.e. 16-Nov-2016) Microsoft released the 1st Service Pack (SP1) of SQL Server 2016.
–> Download:
To download the SQL Server 2016 SP1 you can Register and Download the Full version or Free evaluation version (180 days).
… or you can Download the new Setup utility here, which provides you option to do a Basic or Custom installation, or download the ISO or CAB file (~2.5 GB).
… or you can also just download the Service Pack (SP1) (~550 MB), instead of the whole Setup (~2.5 GB).
–> What’s new SP1:
1. Features which were only available in Enterprise edition are now enabled in Standard, Web, Express, and LocalDB editions, link.
2. List of Bugs and issues fixed, link.
3. CREATE OR ALTER syntax for Stored Procedures, Views, Functions, and Triggers.
4. DBCC CLONEDATABASE (source_database_name, target_database_name), with optional WITH NO_STATISTICS, NO_QUERYSTORE. Creates a duplicate database by cloning Schema, metadata and statistics, without the data.
5. OPTION (USE HINT(‘hint1’, ‘hint2’)), support for a more generic query hinting is added, link.
6. Post this Service Pack (SP1) Parallel INSERTs in INSERT..SELECT to local temporary tables is disabled by default and will require TABLOCK hint for parallel insert to be enabled.
7. New DMVs are added, and some enhanced:
– sys.dm_exec_valid_use_hints to list hints
– sys.dm_exec_query_statistics_xml to return showplan XML transient statistics
– sys.dm_db_incremental_stats_properties to check incremental statistics for the specified table
– New column instant_file_initialization_enabled is added to sys.dm_server_services, to allow DBAs to programmatically identify if Instant File initialization (IFI) is in effect at the SQL Server service startup.
– New column estimated_read_row_count is added to sys.dm_exec_query_profiles
– New columns sql_memory_model and sql_memory_model_desc are added to sys.dm_os_sys_info, to provide information about the locking model for memory pages, and to allow DBAs to programmatically identify if Lock Pages in Memory (LPIM) privilege is in effect at the service startup time.

New Sample database “WideWorldImporters” for SQL Server 2016 and Azure SQL Database
So now as SQL Server 2016 is released (on 1-June-2016) and is in market for few days, so Microsoft team has released a new Sample Database “WideWorldImporters” specially for learning and working with new features of SQL Server 2016 and Azure SQL Database.
Till now AdventureWorks was quiet popular Sample Database since SQL Server 2005 to SQL Server 2014, and still will be. And prior to this we had Northwind and Pubs sample databases to work with SQL Server 2000 version.
–> WideWorldImporters:
You can download both the OLTP and OLAP (DW/BI) databases from this GitHub link.
1. WideWorldImporters (OLTP): contains sample tables for OnLine Transaction Processing (OLTP) workloads, as well as Real-time Operation Analytics.
2. WideWorldImportersDW (OLAP, DW/BI): contains sample tables for OnLine Analytical Processing (OLAP) workloads, in Dimensional Model, like Fact and Dimension tables.
3. For Azure SQL Database: you can download the bacpac for both the editions OLTP/OLAP.
–> These Sample Databases are designed in such a way that these can be used to check and evaluate the new Features of SQL Server 2016, like:
1. Temporal Database and Tables
2. Native JSON support
3. ColumnStore Index
4. In-Memory OLTP
5. Row Level Security, Dynamic Data Masking and Always Encrypted
6. Partitioning
7. Query Store
8. Polybase
–> The MSDN Documentation of these sample databases provides you more information on:
1. Installation and Configuration
2. The Database Catalog
3. Use of SQL Server features and capabilities (mentioned in above points)
4. Some Sample Queries (zip file)
–> After Downloading and Restoring the sample tables looks like this in Object Explorer:

Polybase error in SQL Server 2016 : Row size exceeds the defined Maximum DMS row size, larger than the limit of [32768 bytes]
I got an email form one of my reader regarding issues while working with SQL Server 2016 and Polybase, and it is as follows:
I am able to successfully install SQL with Polybase and able to query data in Azure storage but for a table I am getting error.
I am trying to pull data by creating External Data Source connection in SQL enabled Polybase features. I am getting below error as:
Cannot execute the query “Remote Query” against OLE DB provider “SQLNCLI11” for linked server “(null)”. 107093;Row size exceeds the defined Maximum DMS row size: [40174 bytes] is larger than the limit of [32768 bytes]
With the error description its quiet evident that the External tables does not support row size more than 32768 bytes. But still I take a look online and found in Azure Documentation that this is a limitation right now with Polybase. The Azure document mentions:
Wide rows support is not supported yet, “If you are using Polybase to load your tables, define your tables so that the maximum possible row size, including the full length of variable length columns, does not exceed 32,767 bytes. While you can define a row with variable length data that can exceed this figure, and load rows with BCP, you will not be be able to use Polybase to load this data quite yet. Polybase support for wide rows will be added soon. Also, try to limit the size of your variable length columns for even better throughput for running queries.”
link: https://azure.microsoft.com/en-us/documentation/articles/sql-data-warehouse-develop-table-design/


![]()
Current Visitors

StatCounter …since April 2012

 Leisure blog: Creek & Trails
Leisure blog: Creek & Trails
- NMDC Hyderabad Marathon – My first 42k FM, cramps, training and fuelling
- Singapore (Part 2) – 6 days itinerary, sightseeing & attractions
- Singapore (Part 1) – Tickets, Visa, Hotel, Forex Card/Cash, Metro/Bus cards
- I got full refund of my flight tickets during COVID lockdown (AirIndia via MakeMyTrip)
- YouTube – Your Google Ads account was cancelled due to no spend
- YouTube latest update on its YPP (YouTube Partner Program) which may affect your channel
- Starting your own blog !!!
- How to file ITR (Income Tax Return) online AY 2017-18 (for simple salaried)
- Scam – Become a kin/hier and earn a fortune – via LinkedIn and Email
- Places to visit in and around Vizag (aka Visakhapatnam)
