Archive
Spark error – Parquet does not support decimal. See HIVE-6384
I was creating a Hive table in Databricks Notebook from a Parquet file located in Azure Data Lake store by following command:
val df = spark.read.parquet(
"abfss://adlsstore@MyStorageAccount.dfs.core.windows.net/x/y/z/*.parquet")
df.write.mode("overwrite").saveAsTable("tblOrderDetail")
But I was getting following error:
warning: there was one feature warning; re-run with -feature for details
java.lang.UnsupportedOperationException: Parquet does not support decimal. See HIVE-6384
As per the above error it relates to some Hive version conflict, so I tried checking the Hive version by running below command and found that it is pointing to an old version (0.13.0). This version of Hive metastore did not support the BINARY datatypes for parquet formatted files.
spark.conf.get("spark.sql.hive.metastore.version")

Also as per this Jira Task on HIVE-6384 the support for multiple datatypes was implemented for Parquet SerDe in Hive 1.2.0 version.
So to update the Hive metastore to the current version you just need to add below commands in the configuration of the cluster you are using.
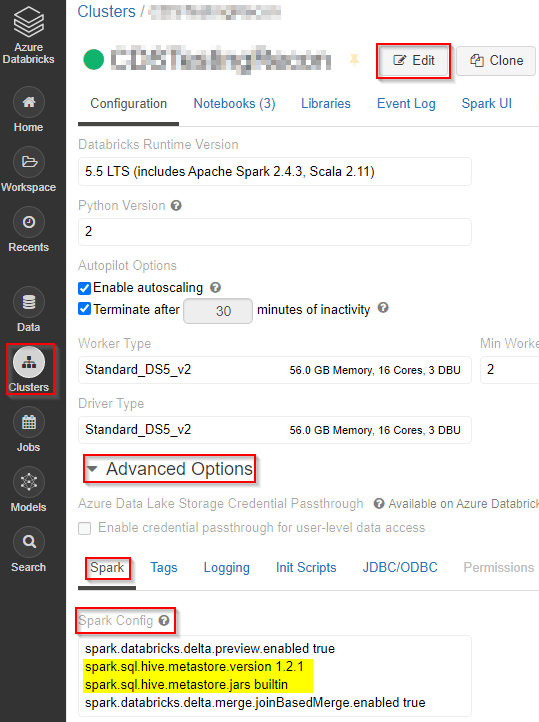
Click on “Clusters” –> click “Edit” on the top –> expand “Advanced Options” –> under “Spark” tab and “Spark Config” box add the below two commands:
spark.sql.hive.metastore.version 1.2.1
spark.sql.hive.metastore.jars builtin
You just need to restart the cluster so that the new settings are in use.
Some similar errors:
– Parquet does not support date
– Parquet does not support timestamp
Hadoop/HDFS storage types, formats and internals – Text, Parquet, ORC, Avro
HDFS or Hadoop Distributed File System is the distributed file system provided by the Hadoop Big Data platform. The primary objective of HDFS is to store data reliably even in the presence of node failures in the cluster. This is facilitated with the help of data replication across different racks in the cluster infrastructure. These files stored in HDFS system are used for further data processing by different data processing engines like Hadoop Map-Reduce, Hive, Spark, Impala, Pig etc.
–> Here we will talk about different types of file formats supported in HDFS:
1. Text (CSV, TSV, JSON): These are the flat file format which could be used with the Hadoop system as a storage format. However these format do not contain the self inherited Schema. Thus with this the developer using any processing engine have to apply schema while reading these file formats.
2. Parquet: file format is the Columnar oriented format in the Hadoop ecosystem. Parquet stores the binary data column wise, which brings following benefits:
– Less storage, efficient Compression resulting in Storage optimization, as the same data type is residing adjacent to each other. That helps in compressing the data better hence provide storage optimization.
– Increased query performance as entire row needs not to be loaded in the memory.
Parquet file format can be used with any Hadoop ecosystem like: Hive, Impala, Pig, Spark, etc.
3. ORC: stands for Optimized Row Columnar, which is a Columnar oriented storage format. ORC is primarily used in the Hive world and gives better performance with Hive based data retrievals because Hive has a vectorized ORC reader. Schema is self contained in the file as part of the footer. Because of the column oriented nature it provide better compression ratio and faster reads.
4. Avro: is the Row oriented storage format, and make a perfect use case for write heavy applications. The schema is self contained with in the file in the form of JSON, which help in achieving efficient schema evolution.
–> Now, Lets take a deep dive and look at these file format through a series of videos below:
Author/Speaker Bio: Viresh Kumar is a v-blogger and an expert in Big Data, Hadoop and Cloud world. He has an experience of ~14 years in the Data Platform industry.
Book: Hadoop – The Definitive Guide: Storage and Analysis at Internet Scale
Azure Databricks learning resources (documentation and videos)
Databricks Introduction
– What is Azure Databricks [Video]
– Create Databricks workspace with Apache Spark cluster
– Extract, Transform & Load (ETL) with Databricks
– Documentation:
– Azure
– Databricks
From Channel 9
1. Data Science using Azure Databricks and Apache Spark [Video]
2. Data ingestion, stream processing and sentiment analysis using Twitter [Video]
3. ETL with Azure Databricks using ADF [Video]
4. ADF new features & integration with Azure Databricks [Video]
5. Azure Databricks introduces R Studio Integration [Video]
6. Run Jars and Python scripts on Azure Databricks using ADF [Video]
From Microsoft Build Conf
Azure Databricks (a fully managed Apache Spark offering)
Databricks Introduction:
Azure Databricks = Best of Databricks + Best of Azure
Azure Databricks is an Apache Spark-based analytics platform optimized for the Microsoft Azure cloud services platform (PaaS).
It is a fast, easy-to-use, and collaborative Apache Spark–based analytics platform. Designed in collaboration with the creators of Apache Spark, it combines the best of Databricks and Azure to help you accelerate innovation with one-click set up, streamlined workflows, and an interactive workspace that enables collaboration among data scientists, data engineers, and business analysts. Because it’s an Azure service, you benefit from native integrations with other Azure services such as Power BI, SQL Data Warehouse, and Cosmos DB. You also get enterprise-grade Azure security, including Active Directory integration, compliance, and enterprise-grade SLAs.

–> With Databricks you can:
– Launch your new Spark environment with a single click.
– Integrate effortlessly with a wide variety of data stores.
– Use Databricks Notebooks to unify your processes and instantly deploy to production.
– Improve and scale your analytics with a high-performance processing engine optimized for the comprehensive, trusted Azure platform.
Learning Resources:
– Webinar recording on Azure Databricks
Prepare for Certification Exam 70-775: Perform Data Engineering on Microsoft Azure HDInsight
In my [previous post] I’ve tried to collate some basic stuff about HDInsight to let you know the basics and get started. You can also check [Microsoft Docs] for HDInsight to know more and deep dive into the Big-Data platform.
Microsoft Certification Exams is one of a good and easy approach to understand the technology. You can find details about Exam 70-775 certification on the Microsoft Certification page.
Though the web page provides most the details of what would be asked in the Exam, but lacks in providing the study material against each module and topics under it. Thus here with this post I’ve tried to find and provide the study material links against each of the topics covered on these modules:
The exam is divided into 4 Modules:
1. Administer and Provision HDInsight Clusters
2. Implement Big Data Batch Processing Solutions
3. Implement Big Data Interactive Processing Solutions
4. Implement Big Data Real-Time Processing Solutions
Module #1. Administer and Provision HDInsight Clusters
1. Deploy HDInsight clusters
– Create a HDInsight cluster [Portal] [ARM Template] [PowerShell] [.net SDK] [CLI]
– Create HDInsight clusters with Hadoop, Spark, Kafka, etc [Link]
– Select an appropriate cluster type based on workload considerations [Link]
– Create a cluster in a private virtual network [Link]
– Create a domain-joined cluster [Link]
– Create a cluster that has a custom metastore [link]
– Manage managed disks [with Apache Kafka]
– Configure vNet peering [Link]
2. Deploy and secure multi-user HDInsight clusters
– Provision users who have different roles
– Manage users, groups & permissions [Ambari] [PowerShell] [Apache Ranger]
– Configure Kerberos [Link]
– Configure service accounts
– Implement SSH [Connecting] [Tunneling]
– Restrict access to data [Link]
3. Ingest data for batch and interactive processing
– Ingest data from cloud or on-premises data; store data in Azure Data Lake
– Store data in Azure Blob Storage
– Perform routine small writes on a continuous basis using Azure CLI tools
– Ingest data in Apache Hive and Apache Spark by using Apache Sqoop, Application Development Framework (ADF), AzCopy, and AdlCopy
– Ingest data from an on-premises Hadoop cluster
4. Configure HDInsight clusters
– Manage metastore upgrades
– View and edit Ambari configuration groups
– View and change service configurations through Ambari
– Access logs written to Azure Table storage
– Enable heap dumps for Hadoop services
– Manage HDInsight configuration, use HDInsight .NET SDK, and PowerShell
– Perform cluster-level debugging
– Stop and start services through Ambari
– Manage Ambari alerts and metrics
5. Manage and debug HDInsight jobs
– Describe YARN architecture and operation
– Examine YARN jobs through ResourceManager UI and review running applications
– Use YARN CLI to kill jobs
– Find logs for different types of jobs
– Debug Hadoop and Spark jobs
– Use Azure Operations Management Suite (OMS) to monitor and manage alerts, and perform predictive actions
Module #2. Implement Big Data Batch Processing Solutions
1. Implement batch solutions with Hive and Apache Pig
– Define external Hive tables; load data into a Hive table
– Use partitioning and bucketing to improve Hive performance
– Use semi-structured files such as XML and JSON with Hive
– Join tables with Hive using shuffle joins and broadcast joins
– Invoke Hive UDFs with Java and Python; design scripts with Pig
– Identify query bottlenecks using the Hive query graph
– Identify the appropriate storage format, such as Apache Parquet, ORC, Text, and JSON
2. Design batch ETL solutions for big data with Spark
– Share resources between Spark applications using YARN queues and preemption
– Select Spark executor and driver settings for optimal performance, use partitioning and bucketing to improve Spark performance
– Connect to external Spark data sources
– Incorporate custom Python and Scala code in a Spark DataSets program
– Identify query bottlenecks using the Spark SQL query graph
3. Operationalize Hadoop and Spark
– Create and customize a cluster by using ADF
– Attach storage to a cluster and run an ADF activity
– Choose between bring-your-own and on-demand clusters
– Use Apache Oozie with HDInsight
– Choose between Oozie and ADF
– Share metastore and storage accounts between a Hive cluster and a Spark cluster to enable the same table across the cluster types
– Select an appropriate storage type for a data pipeline, such as Blob storage, Azure Data Lake, and local Hadoop Distributed File System (HDFS)
Module #3. Implement Big Data Interactive Processing Solutions
1. Implement interactive queries for big data with Spark SQL
– Execute queries using Spark SQL
– Cache Spark DataFrames for iterative queries
– Save Spark DataFrames as Parquet files,
– Connect BI tools to Spark clusters
– Optimize join types such as broadcast versus merge joins
– Manage Spark Thrift server and change the YARN resources allocation
– Identify use cases for different storage types for interactive queries
2. Perform exploratory data analysis by using Spark SQL
– Use Jupyter and Apache Zeppelin for visualization and developing tidy Spark DataFrames for modeling
– Use Spark SQL’s two-table joins to merge DataFrames and cache results
– Save tidied Spark DataFrames to performant format for reading and analysis (Apache Parquet)
– Manage interactive Livy sessions and their resources
3. Implement interactive queries for big data with Interactive Hive
– Enable Hive LLAP through Hive settings
– Manage and configure memory allocation for Hive LLAP jobs
– Connect BI tools to Interactive Hive clusters
4. Perform exploratory data analysis by using Hive
– Perform interactive querying and visualization
– Use Ambari Views
– Use HiveQL
– Parse CSV files with Hive
– Use ORC versus Text for caching
– Use internal and external tables in Hive
– Use Zeppelin to visualize data
5. Perform interactive processing by using Apache Phoenix on HBase
– Use Phoenix in HDInsight
– Use Phoenix Grammar for queries
– Configure transactions, user-defined functions, and secondary indexes
– Identify and optimize Phoenix performance
– Select between Hive, Spark, and Phoenix on HBase for interactive processing
– Identify when to share metastore between a Hive cluster and a Spark cluster
Module #4. Implement Big Data Real-Time Processing Solutions
1. Create Spark streaming applications using DStream API
– Define DStreams and compare them to Resilient Distributed Dataset (RDDs)
– Start and stop streaming applications
– Transform DStream (flatMap, reduceByKey, UpdateStateByKey)
– Persist long-term data stores in HBase and SQL
– Persist Long Term Data Azure Data Lake and Azure Blob Storage
– Stream data from Apache Kafka or Event Hub
– Visualize streaming data in a PowerBI real-time dashboard
2. Create Spark structured streaming applications
– Use DataFrames and DataSets APIs to create streaming DataFrames and Datasets
– Create Window Operations on Event Time
– Define Window Transformations for Stateful and Stateless Operations
– Stream Window Functions, Reduce by Key, and Window to Summarize Streaming Data
– Persist Long Term Data HBase and SQL
– Persist Long Term Data Azure Data Lake and Azure Blob Storage
– Stream data from Kafka or Event Hub
– Visualize streaming data in a PowerBI real-time dashboard
3. Develop big data real-time processing solutions with Apache Storm
– Create Storm clusters for real-time jobs
– Persist Long Term Data HBase and SQL
– Persist Long Term Data Azure Data Lake and Azure Blob Storage
– Stream data from Kafka or Event Hub
– Configure event windows in Storm
– Visualize streaming data in a PowerBI real-time dashboard
– Define Storm topologies and describe Storm Computation Graph Architecture
– Create Storm streams and conduct streaming joins
– Run Storm topologies in local mode for testing
– Configure Storm applications (Workers, Debug mode)
– Conduct Stream groupings to broadcast tuples across components
– Debug and monitor Storm jobs
4. Build solutions that use Kafka
– Create Spark and Storm clusters in the virtual network
– Manage partitions
– Configure MirrorMaker
– Start and stop services through Ambari
– Manage topics
5. Build solutions that use HBase
– Identify HBase use cases in HDInsight
– Use HBase Shell to create updates and drop HBase tables
– Monitor an HBase cluster
– Optimize the performance of an HBase cluster
– Identify uses cases for using Phoenix for analytics of real-time data
– Implement replication in HBase


![]()
Current Visitors

StatCounter …since April 2012

 Leisure blog: Creek & Trails
Leisure blog: Creek & Trails
- NMDC Hyderabad Marathon – My first 42k FM, cramps, training and fuelling
- Singapore (Part 2) – 6 days itinerary, sightseeing & attractions
- Singapore (Part 1) – Tickets, Visa, Hotel, Forex Card/Cash, Metro/Bus cards
- I got full refund of my flight tickets during COVID lockdown (AirIndia via MakeMyTrip)
- YouTube – Your Google Ads account was cancelled due to no spend
- YouTube latest update on its YPP (YouTube Partner Program) which may affect your channel
- Starting your own blog !!!
- How to file ITR (Income Tax Return) online AY 2017-18 (for simple salaried)
- Scam – Become a kin/hier and earn a fortune – via LinkedIn and Email
- Places to visit in and around Vizag (aka Visakhapatnam)
